
动态手势识别实战
Github:Wonderseen_Gesture_NetAuthor:Wonderseen | Xiamen University | 2018.04.27如需转载本文,请先联系作者本人,谢谢。因为工程维护需要时间,代码陆续在上传。具体请跟进上面的链接,如果觉得项目对您有帮助,请您给予一点鼓励,送个star。大三上的课余时间基本都花在手势识别的项目上,其中最困难的部分是选择手势...
Github:Wonderseen_Gesture_Net
Author:Wonderseen | Xiamen University | 2018.04.27
如需转载本文,请先联系作者本人,谢谢。
因为工程维护需要时间,代码陆续在上传。具体请跟进上面的链接,如果觉得项目对您有帮助,请您给予一点鼓励,送个star。
- 大三上的课余时间基本都花在手势识别的项目上,其中最困难的部分是选择手势识别问题的解决方案。最近看到有些朋友也在做手势识别的项目,所以整理一下自己的方案,以作参考。
设备选项:
RGB传感器(单相机single-view或者多相机multi-view)、深度传感器(相机方面根据精度选择设备,一般的双目精度【较少毫米级】不如TOF或者结构光精度高)以及前两者结合的传感器(截至去年为止,某宝能搜到的提供完整sdk的成品有SR系列、Kinect、图漾等)
- 传统方案:在深度学习大行其道之前,出现过许多识别手势的方法。
- 阈值分割在匹配手部mask,再根据手指尖的关系对指尖伸展情况,进行指端伸展情况判断(数手指头之类的),进而判断设定的若干个手势
比如内切圆记录为掌心,凸集形成的多边形顶点数记录为指尖等,这里可以衍生的形态学方法比较多,翻墙也可以找到会议论文可以参考。
- 利用提取到的手部灰度图(这里觉得有困难的可以尝试用标记来识别手部,比如蓝手套等)和提前设定好的手部模板进行匹配
方案2:涉及的是图像相似度的计算,比如基于图像灰度图的NCC方法或者基于形状的匹配方法等。
这类方法主要用在工业视觉项目,其表现为其检测范围内的背景相对简单,同时光照被人为提前设定;不过,在复杂环境下或者被测物体多自由度的情况下,方案2的表现比较差。这个方案我没有怎么尝试,目前尚不清楚优化效果。
- 制作好手势图数据集,用adaboost算法选出Haar或者Hog特征,获得手部特征描述子,并用来检测和识别手势。
方案3:用Opencv比较容易实现,库和示例比较完整。
(1) 首先,训练手部的检测器,用来获得手部局部图;
(2)接着,利用多种手势检测器对局部图进行检测分类。
这个方案实施过程中,要注意用于训练的正负样本的选择,以及训练参数的设定,留好裕度。用Opencv自带的adaboost进行迭代前要了解到,Hard 的正样本是会被丢弃的,并会从未训练的样本中,抽取新的样本,用以补充训练队列。
转载自知乎作者【白裳丶】adaboost+haar工程实现过程及细节
- 阈值分割在匹配手部mask,再根据手指尖的关系对指尖伸展情况,进行指端伸展情况判断(数手指头之类的),进而判断设定的若干个手势
- 必须提一句:上述的3种方案,适用于特定环境的试验中,但是对光照比较敏感,难以适应各种光照,不过好在实现起来会比较轻松,如果是作为视觉入门项目,建议初学者走走这三个方案的弯路,对巩固基础知识比较有帮助。
- 同时方案1和方案2较为死板,因为这两种方案限定了手部与相机的相对关系,比如限定了”手部必须正对相机”这样隐性的要求。

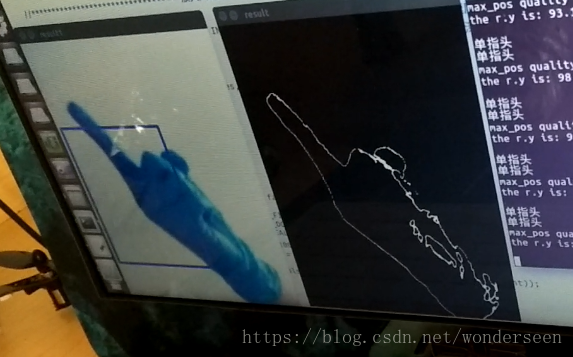

深度学习大背景下,提出方案4。
深度学习应用背景:
手势估计任务可以归结为关键点估计的一类问题。这两年关键点估计在学术上是解决得比较通透的问题,该方向目前亟待解决的新问题,主要出现在以下两种情况中:
(1)在待检测目标存在大面积被遮挡的情况下
(2)在同一视野中,目标对象的尺寸短时间内发生快速变化时
如何对关键点或者图像语义进行准确的实例估计,即instance segmentation。就普通爱好者而言,做手势识别任务,先从基础情况入手。这里假设任务环境:在图像采集过程中,被捕捉的手部图像是稳定的、并且不被其他物体所遮挡。
我所用的方案 :
整个流程包括【手部分割】(Handmask Semantic Segmentation)、【手势关键点估计】(HandUV Estimation)、【手势分类】(Gesture Classification)。
手部分割:为了缩小检测范围,减少图像噪声的影响,这个做法和mtcnn的two-stream做法类似。为了实现这个目的,你也可以不使用FCN;实现的途径是多样的,比如你如果愿意换而采用RPN(Region Proposal Net)实现,那么mask rcnn、ssd、yolo v3等均可以进行一番尝试。
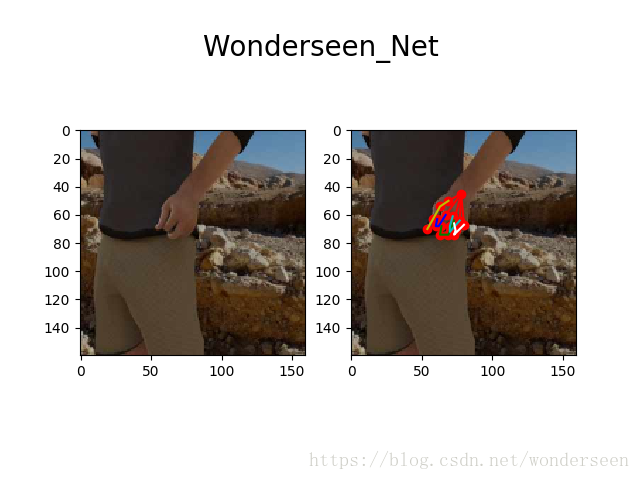
原创作者:雷鸣–基于深度学习的目标检测算法综述关键点估计:对手部的21dofs 或者 26dofs (或者更多)的2d坐标进行估计。2d估计的方案就比较多了,基于像素预测的cpm、hg或者基于边框回归的mask-rcnn及其变种。因为vgg网络太沉,所以我没有完全采用它的结构。出于减少网络复杂度的考虑,我综合GoogleNet的特征提取结构和u-net的优点,写了比较浅层的网络,在这个关键点估计任务中,优化后表现还不错,关键点和ground truth的平均距离差在1.4个像素。对于有更多精力的朋友,建议您不要止步于此,继续延伸,利用KL散度等信息从2d往3d进行深度的回归估计。
手势分类:单类定长输入的分类问题,想必大家一定不陌生。这里我的trick是:为关键点设置高斯监督,并结合Part cropped at Proposal Region作优化。
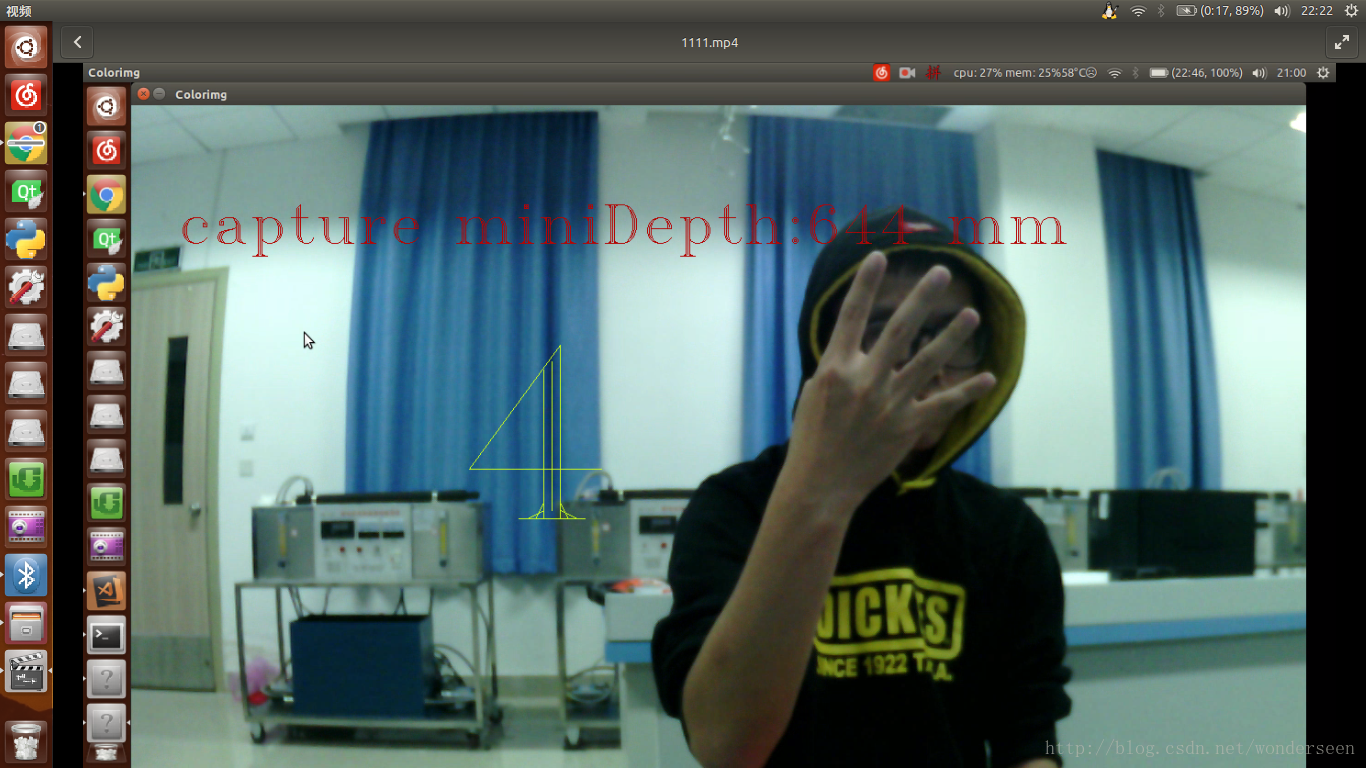
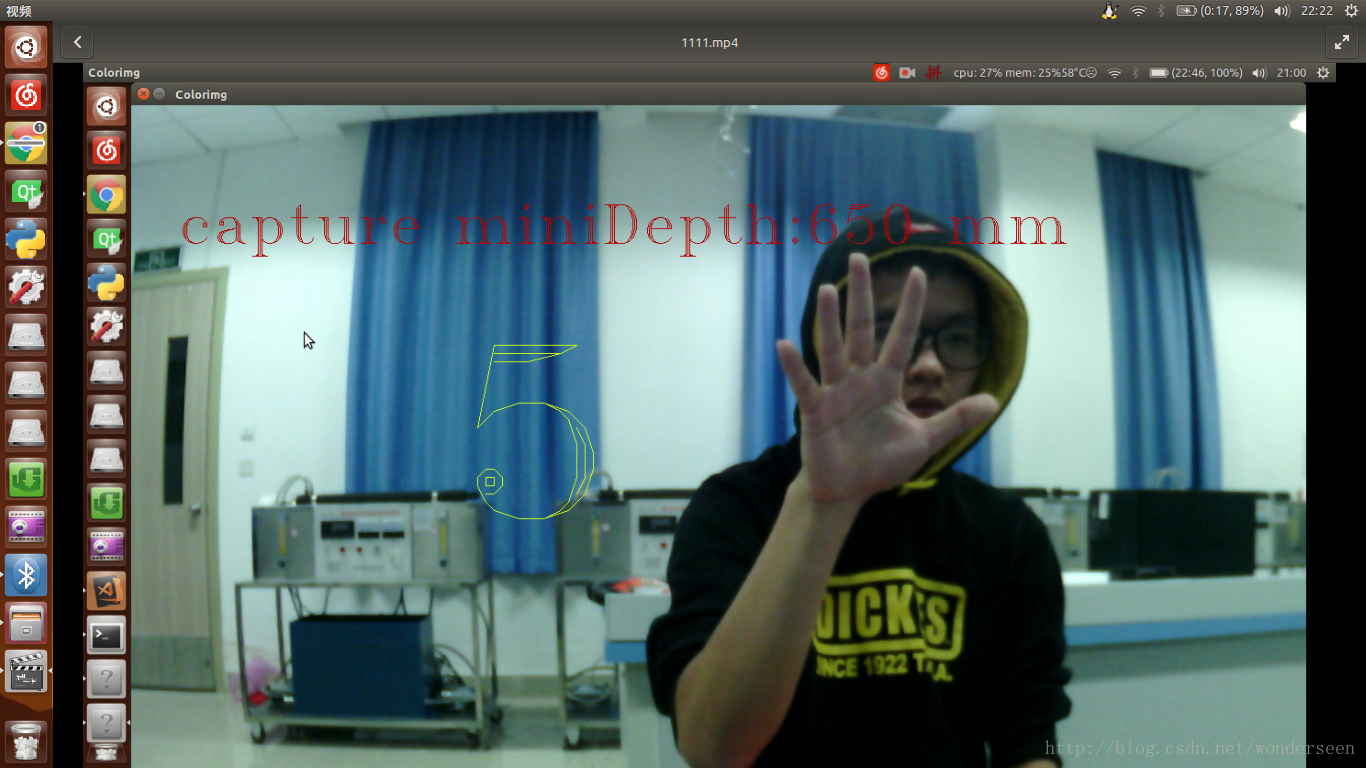
我的小demo测试视频,用五个简单手势,控制单点的运动

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 41
41 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)