Java 演示:如何使用Zookeeper 集群例子
概述Zookeeper是Apache下的项目之一,倾向于对大型应用的协同维护管理工作。IBM则给出了IBM对ZooKeeper的认知: Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。总之,可以用“协调”这个核心的词来形容它的作用。关于
概述
Zookeeper是Apache下的项目之一,倾向于对大型应用的协同维护管理工作。IBM则给出了IBM对ZooKeeper的认知: Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。总之,可以用“协调”这个核心的词来形容它的作用。关于它能干吗,你可以看看 “Zookeeper能干什么?”。
特征
-
我们可以把Zookeeper理解为一个精简的文件系统(和Linux文件系统结构非常相似),其每一个节点称为znode,znode下可以存放子节点,也可以直接对节点进行赋值存值。
-
Zookeeper被应用与一些集群上,提高集群的高可用。它可以帮助你避免单点故障,使你的系统更加可靠。
-
Zookeeper的集群我们可以通俗的理解为,一个有Leader的团队,团队中各个成员的数据都是一致的。团队中的Leader采用选举算法推举,所以可以保证在Leader出现问题的时候,又会选举出新的Leader。(fast paxos 选举算法大家可以深入了解下)
-
Zookeeper使用路径来描述节点,节点可以被看做是一个目录,也可以被看做是一个文件,它同时具有两者的特点。
-
Zookeeper的Watch机制也是它的最大被应用的原因。当我们有很多客户端连接到Zookeeper时,当被设置了Watch的数据发生了改变的时候,则服务器将这个改变发送给设置了Watch的客户端,通知它们。所以我们经常用它来做业务系统的统一配置管理。使用zk的Watch要特别注意一点就是它的“一次性触发器”(最后的Java例子中有模拟这点)。
集群部署
1. 下载
官网:http://zookeeper.apache.org/releases.html
下载:zookeeper-3.4.8.tar.gz
2. 安装
因为资源有限,所以我在同一个服务器上面创建3个目录 server1、server2、server3 来模拟3台服务器集群。
cd server1
tar -zxvf zookeeper-3.4.8.tar.gz
mkdir data
mkdir dataLog
data 为数据目录,dataLog 为日志目录。
3. 配置
cd zookeeper-3.4.8/conf
创建文件 zoo.cfg,内容如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
tickTime:zookeeper中使用的基本时间单位, 毫秒值。
initLimit:这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个 tickTime 时间间隔数。这里设置为5表名最长容忍时间为 5 * 2000 = 10 秒。
syncLimit:这个配置标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 2 * 2000 = 4 秒。
dataDir 和 dataLogDir 看配置就知道干吗的了,不用解释。
clientPort:监听client连接的端口号,这里说的client就是连接到Zookeeper的代码程序。
server.{myid}={ip}:{leader服务器交换信息的端口}:{当leader服务器挂了后, 选举leader的端口}
maxClientCnxns:对于一个客户端的连接数限制,默认是60,这在大部分时候是足够了。但是在我们实际使用中发现,在测试环境经常超过这个数,经过调查发现有的团队将几十个应用全部部署到一台机器上,以方便测试,于是这个数字就超过了。
修改zoo.cfg非常简单,然后还需要创建myid文件:
cd server1
echo 1 > myid
然后拷贝server1为server2和server3,并修改其中的zoo.cfg配置,当然也要修改myid的内容为2和3。
下面给出3个server的zoo.cfg 内容:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这里做下说明:因为我们是在同一个机器上模拟的集群,所以要注意server端口号和clientPort不要重复了,不然会出现端口冲突。所以,如果我们是3个不同的机器上做的3个server,那么我们的zoo.cfg配置都是一样的(注意server.{myid}=后面的IP地址使用具体的IP地址,如192.168.0.88)。还有就是,每一个server的myid内容都不能一样,这也可以理解为不同server的标识。
4. 启动
进入 zookeeper-3.4.8/bin 目录,使用 ./zkServer.sh start 启动zk服务。(你也可以使用 ./zkServer.sh start myzoo.cfg 指定配置文件启动,这在自动化运维的时候很有用)
使用 tail -f zookeeper.out 查看日志。
要说的是:在启动第一个的时候,日志中会出现一堆错误,仔细一看就能明白,是因为另外2个server还没有启动它连接不上的错误。然后当我们启动第二个server的时候,日志中的错误将会减少。最后我们把所有server都启动起来后,日志中便没有错误了。
5. 测试
随便进入一个zk目录,连接一个server测试。
cd zookeeper-3.4.8/bin
zkCli.sh -server 127.0.0.1:2181
如果你要连接别的服务器,请指定具体的IP地址。
几个基本命令说明:
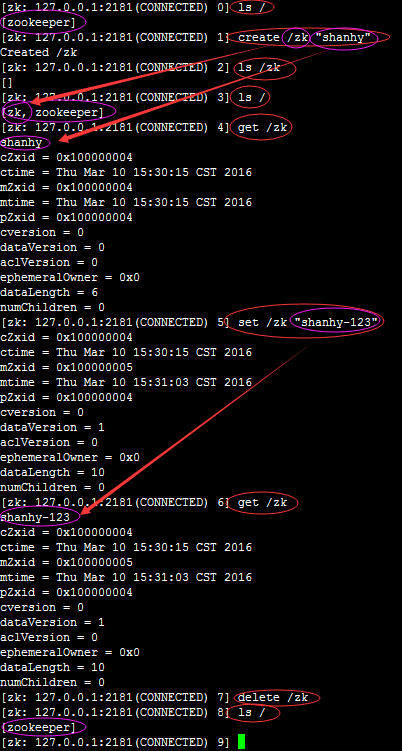
ls 查看指定节点中包含的子节点(如:ls / 或 ls /app1/server1)
create 创建节点并赋值
get 读取节点内容
set 改变节点内容
delete 删除节点
注意zk中所有节点都基于路径确定,如你要删除 /app1/server1/nodeA 的命令为:
delete /app1/server1/nodeA
下面是基本操作截图:
Java程序Demo
创建一个Maven工程
打开pom.xml文件添加zookeeper依赖
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
创建Demo.java,代码如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
我想代码不用解释了,该注释的里面都注释了。
下面有一种特殊的情况的处理思路:
有server1、server2、server3这三个服务,在client去连接zk的时候,指向server1初始化的过程中是没有问题的,然而刚刚初始化完成,准备去连接server1的时候,server1因为网络等原因挂掉了。
然而对client来说,它会拿server1的配置去请求连接,这时肯定会报连接被拒绝的异常以致启动退出。
所以优雅的解决这个问题的方法思路就是“在连接的时候判断连接状态,如果未连接成功,程序自动使用其他连接去请求连接”,这样来避开这种罕见的异常问题。
代码如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
上面的代码是基于zk提供的库的API来你使用的,为了更易于使用,有人写了开源的zkclient,我们可以直接使用它来操作zk。
zkclient 开源地址:https://github.com/sgroschupf/zkclient
maven 依赖配置:
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
zkClient 针对 zk 的一次性watcher,做了重新封装,然后定义了 stateChanged、znodeChanged、dataChanged 三种监听器。
- 监听children变化
- 监听节点数据变化
- 监听连接状态变化
代码如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
ZkClient 做了便捷的包装,对Watch做了增强处理。
subscribeChildChanges实际上是通过exists和getChildren关注了两个事件。这样当create(“/path”)时,对应path上通过getChildren注册的listener也会被调用。另外subscribeDataChanges实际上只是通过exists注册了事件。因为从上表可以看到,对于一个更新,通过exists和getData注册的watcher要么都会触发,要么都不会触发。
关于session超时的问题,ZkClient 貌似还是有对 Session Expired 处理的,在ZkClient.processStateChanged方法中。虽然能重新连接,但是连接上是一个新的 session,原有创建的ephemeral znode和watch会被删除,程序上你可能需要处理这个问题。

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 3
3 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)