强化学习介绍(RL)
机器学习有三大分支,监督学习、无监督学习和强化学习,强化学习是系统从环境学习以使得奖励最大的机器学习。人工智能中称之为强化学习,在控制论中被称之为动态规划,两者在概念上是等价的。也被翻译为增强学习。
一、简介
机器学习有三大分支,监督学习、无监督学习和强化学习,强化学习是系统从环境学习以使得奖励最大的机器学习。**人工智能中称之为强化学习,在控制论中被称之为动态规划,两者在概念上是等价的。**也被翻译为增强学习。
二、概念
- 不同于机器学习的其它两个分支:
- 它不是无监督学习,因为有回报(Reward)信号
- 反馈是延时的,而不是即时的
- 数据是与时间有关的序列
- 智能体的动作与后续的数据有关
- 强化学习基于一种回报假设:
- 回报是标量反馈信号
- 表明智能体(Agent)在这步做得有多好
- 智能体(Agent)的任务就是最大化累计回报
Reinforcement learning is learning what to do ----how to map situations to actions ---- so as to maximize a numerical reward signal.
强化学习关注的是智能体如何在环境中采取一系列行为,从而获得最大的累积回报。
- 连续决策(Sequential Decision Making):
- 目标:选择一个Action尽量最大化将来的总回报
- Aciton可能有长期的影响
- 回报可能延时
- 牺牲即时回报去获得更好的长期回报
金融投资就是一个这样的过程。
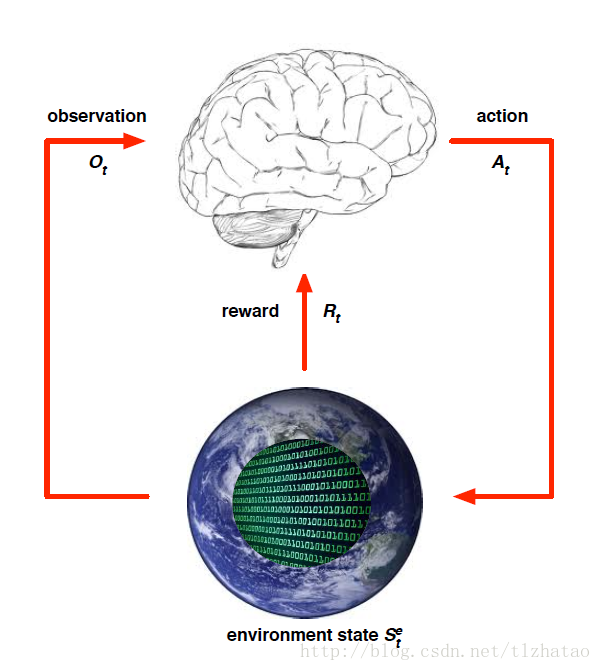
- 环境状态(Environment State):
- Environment State是Environment私有的表达
- Environment利用这些数据寻找下个Observation或者Reward
- Environment State不总是对Agent可见的
- 即使Environment State是可见的,也有可能包含一些不相关的信息
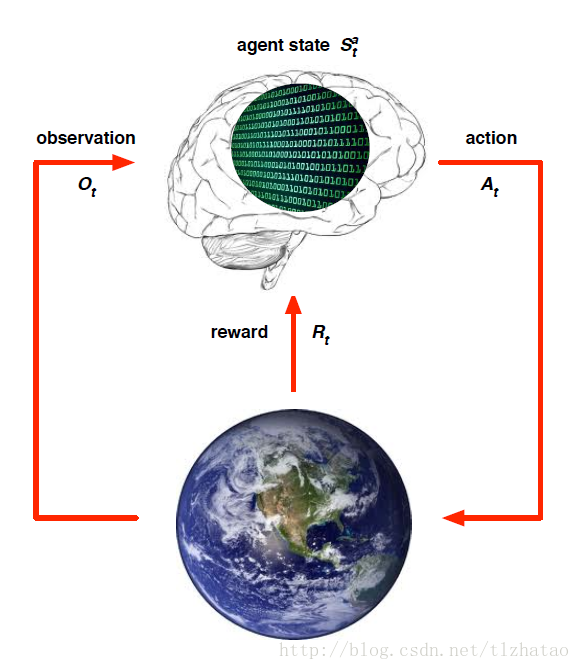
- 智能体状态(Agent State):
- Agent State是Agent的内在表达
- Agent用这些信息寻找下个Action
- 这些信息被用于强化学习算法
- 信息状态(Information State):包含来自历史记录的所有有用的信息,也称之为Markov State
- 将来信息独立给定现在信息的过去信息
- 一旦状态已知,历史记录就可以扔掉
- 这个状态是将来的充要统计
- Environment State是Markov
- 历史记录也是Markov
- 完全可观察的环境(Fully Observable Environments):Agent可以直接观察到的Environment State
- Agent State = Environment State = Information State
- 这是一个Markov Decision Process
- 部分可观察的环境(Partially Observable Environments)
- Agent不能直接观察到Environment
- Agent State不等于Environment State
- 这是一个Partially Observable Markov Decision Process
- Agent必须创建自己的State表达自己
- 强化学习智能体的主要组件(Major Components of an RL Agent):
- Policy:Agent的习惯函数
- Value Function:每个State或者Action的好坏
- Model:Agent的环境表达
- 策略(Policy):
- Policy是Agent的习惯表达
- State到Action的映射
- 确定策略
- 随机策略
- 值函数(Value Function):
- Value Function是将来回报的预测
- 用于评估State的好坏
- 因此,可以用于动作间的选择
- 模型(Model):
- Model预测下一步Environment做什么
- 预测下个状态
- 预测下个回报
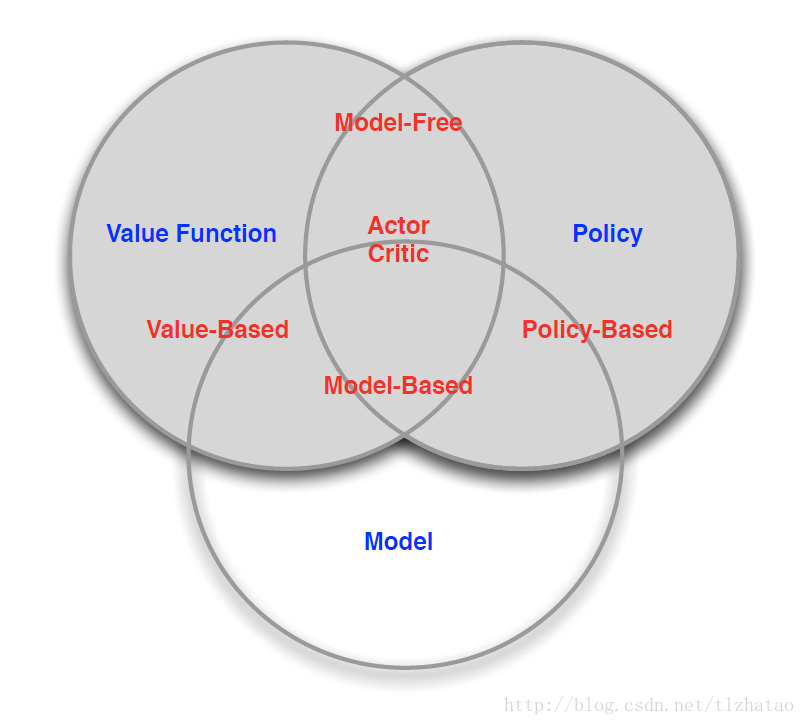
三、Agent的分类:
- Value Based:
- Value Function
- Policy Based:
- Policy
- Actor Critic:
- Policy
- Value Function
- Model Free:
- Policy或Value Function
- Model Based:
- Policy或Value Function
- Model
四、过程:
通过强化学习,一个智能体(Agent)应该知道在什么状态(State)下应该采取什么行为(Action),这个状态从以获取最大的回报(Reward)。强化学习是从环境状态到动作的映射的学习,我们把这个映射称之为策略(Policy)。
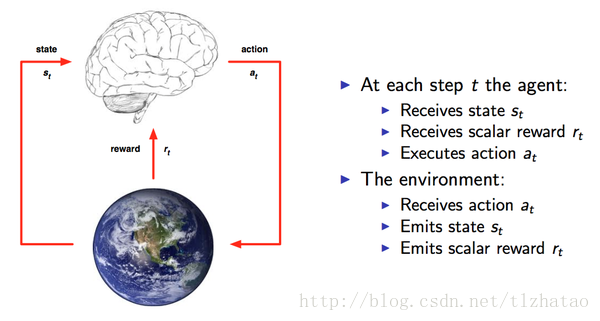
从David Silver的图可以看出Agent和Environment之间的关系 ,每个时间点Agent都会根据上一刻的State,从可以选择的动作集合中选择一个动作a_t执行,这个动作集合可以是连续的,比如机器人的控制,也可以是离散的比如游戏中的几个按键,动作集合的数量将直接影响整个任务的求解难度,执行a_t后得到一个Reward。环境收到动作a_t,放出State和Reward。
Agent都是根据当前的State来确定下一步的动作。因此,状态State和动作Action存在映射关系,也就是一个State可以对应一个Action,或者对应不同动作的概率(概率最高的就是最值得执行的动作)。状态与动作的关系其实就是输入与输出的关系,而State到Action的过程就称之为一个Policy。我们需要找到这样一个Policy使得Reward最大。
五、例子
- 直升机特技飞行
- 机器人行走
- 战胜棋类世界冠军
- 玩游戏比人类还要好

上图是一个吃豆子游戏,迷宫的每一格就是一种State,Agent在每个State下,应该选择上下左右这些Action,吃豆子会得到正的Reward,被吃掉则反之。而在每个State下会选择哪一个Action则是Policy。
输入是:
- State = Observation,例如迷宫的每一格是一个State
- Actions = 在每个状态下,有什么行动
- Reward = 进入每个状态时,能带来正面或负面的回报
输出就是:
- Policy = 在每个状态下,会选择哪个行动
再详细一点就是:
- State = 迷宫中Agent的位置,可以用一对座标表示,例如(1,3)
- Action = 在迷宫中每一格,你可以行走的方向,例如:{上,下,左,右}
- Reward = 当前的状态 (current state) 之下,迷宫中的一格可能有食物 (+1) ,也可能有怪兽 (-100)
- Policy = 一个由状态 → 行动的函数,即: 函数对给定的每一个状态,都会给出一个行动
六、预测与控制
- Prediction:评估未来
- 给定Policy
- Control:优化未来
- 找到最好的Policy
七、一些问题
-
强化学习像一个尝试-错误的学习
-
Agent发现一个最好的Policy
-
来自环境的经验
-
在这条路上不要丢掉太多的Reward
-
探索寻找更多关于Environment的信息
-
运用那些可以最大化Reward的信息
-
探索和利用通常一样重要

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)