
集合框架--集合框架体系概述
集合框架体系主要如上图所示,集合类主要分为两大类:Collection和Map。先简单概述几个相关问题。1、先说明下什么是集合? 当数据多了需要存储,需要容器,但是数据的个数又不确定的时候,无法使用数组(数组长度是固定的,集合长度是可变的),这时便使用了Java中的另一个容器--集合。2、数组与集合有哪些不同? 数组中存储的是同一类型的元素,可以存储基本数据
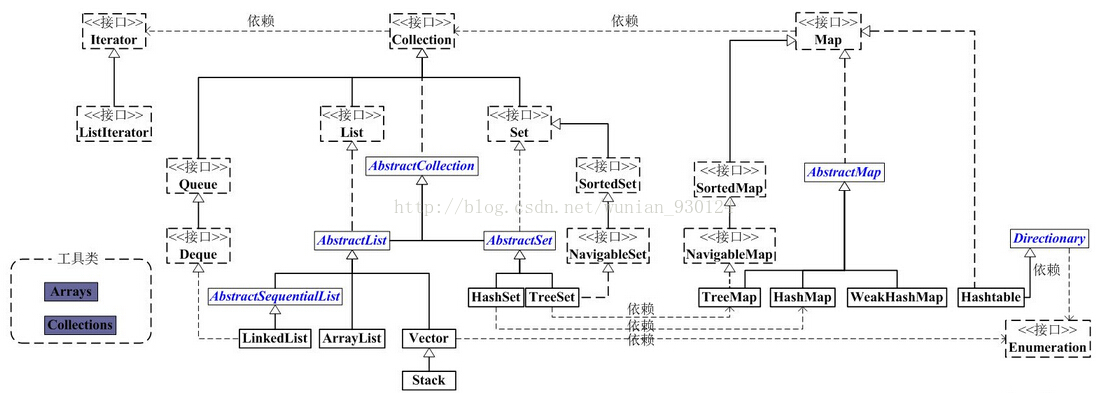
集合框架体系主要如上图所示,集合类主要分为两大类:Collection和Map。
先简单概述几个相关问题。
1、先说明下什么是集合?
当数据多了需要存储,需要容器,但是数据的个数又不确定的时候,无法使用数组(数组长度是固定的,集合长度是可变的),这时便使用了Java中的另一个容器--集合。
2、数组与集合有哪些不同?
数组中存储的是同一类型的元素,可以存储基本数据类型值。
集合存储的是对象,而且对象的类型可以不一致。
3、什么时候使用集合呢?
当对象多的时候,先进行存储。
在实际的使用中,我们有了更多的需求,于是出现了集合框架,有了更多的容器(每个容器有自己的数据结构,因此其功能也不同),在不断向上抽取的过程中,出现了体系,最终形成了集合框架.
细节:1 集合中存储的都是对象的地址(引用)
2 集合中是否可以存储基本数值?不可以,但在jdk1.5后可以这么写,但是存储的还是对象(基本数据类型包装类对象)
3 存储的时候自动提升为Object类型,取出的时候如果需要使用元素的特有内容,必须进行向下转型
接下来,简单谈谈Collection,collection是List、Set等集合高度抽象出来的接口,它包含了这些集合的基本操作。主要分为:List和Set。
一、List接口:
通常表示一个列表(数组、队列、链表、栈等),有序的,
元素是可以重复的,通过索引就可以精确的操作集合中的元素,List接口的特有方法,都是围绕索引定义的。
List获取元素的方式有两种:一种是迭代,还有一种是遍历+get
List接口是支持对元素进行增删改查动作的(add,set,get,remove)
常用的实现类为ArrayList和LinkedList,还有不常用的Vector(已过时)。
1、ArrayList:是数组结构,长度是可变的,原理是(创建新数组+复制数组),查询速度快,增删较慢,不同步。ArrayList不是线程安全的,只能用在单线程环境下,多线程环境下可以考虑使用Collections.synchronizedList(List i)函数返回一个线程安全的ArrayList类,或者使用Concurrent并发包下对应的集合类。
2、LinkedList:是基于双向循环链表实现的,是链表结构,不同步的,增删速度快,查询较慢。由于实现了Queue接口,因此也可以用于实现堆栈、队列。
3、Vector:可以增长的数组结构,同步的,效率很低,查询增删凑慢,已过时。
二、Set集合:不允许包含重复的元素(通过hashcode和equals函数保证),不保证顺序,而且方法和Collection一致,set集合取出元素的方式只有一种:迭代器。
常用的实现类为HashSet和TreeSet。
1、HashSet:基于HashMap实现,哈希表结构,不同步,保证元素的唯一性依赖于hashCode(),equals()方法。
Hash概述:哈希算法hash也称散列,结果叫哈希值。数组中存储的都是(元素与哈希值的)对应关系,该数组称为哈希表,查询速度比数组快,重复元素存不进去,保证元素的唯一性。
哈希冲突怎么解决?元素的哈希值(hashcode())一致了,这是会再次判断元素的内容是否相同(equals()),如果equlas返回true,意味着两个元素相同,如果返回的是false,意味着两个元素不相同,继续通过算法算出位置进行存储(拉链法)。
2、TreeSet:基于TreeMap实现,实现了SortedSet接口,是有序的,添加到TreeSet中的元素要实现Comparable接口,以便使用元素的自然排序对元素进行排序,或者根据创建set时提供的Comparator进行排序。
comparable和comparator的区别:
Comparable:此接口强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序,类的 compareTo 方法被称为它的自然比较方法。
他们都是用来实现集合中元素的比较、排序的,只是comparable是在集合内部定义的方法实现的排序,而comparator是在集合外部实现的排序。
comparator位于包java.util下,而comparable位于包java.lang下。
元素的排序比较有两种方式:
a,元素自身具备的自然排序,其实就是实现了Comparable接口,重写了compareTo方法。如果元素自身不具备自然排序,或者具备的自然排序不是所需要的,这时使用第二种方式。
b,比较器排序,其实就是在创建TreeSet集合时,在构造函数中指定具体的比较方式,需要定义一个类实现Comparator接口,重写compare方法。
到此为止,在往集合中存储对象时,通常该对象都需要覆盖hashcode(),equals(),同时实现Comparable接口,建立对象的自然排序。
·
三、Map:抽象类AbstractMap通过适配器模式实现了Map接口中大部分的函数,TreeMap、HashMap等实现类都是通过继承AbstractMap来实现,另外,不常用的HashTable直接实现了Map接口,他和Vector都是JDK1.0就引入的集合类。
1、内部存储的都是key-value键值对
2、必须保证键的唯一性,value可以有多个相同的
Map
|--Hashtable:数据结构为哈希表,同步的,不允许null作为键和值,被hashmap所替代
|--Properties:属性集,键和值都是字符串,可结合流进行键值的操作
|--HashMap:数据结构为哈希表,不同步,允许null作为键和值,无序的
|--TreeMap:数据结构是二叉树,不同步,可对map集合中给的键进行排序
四、Iterator:是遍历集合的迭代器(不能遍历Map,只能遍历Collection),Collection的实现类都实现了iterator()函数,它返回一个Iterator对象,用来遍历集合,ListIterator则专门用来遍历List。其中,枚举Emumeration和迭代器Iterator功能重复,Iterator多一个删除操作,由于其名字太长,被弃用。
五、Arrays和Collections
Collections:集合框架中用于操作集合对象的工具类,都是静态方法。
1、获取Collection最值
2、对List集合排序,也可以二分查找
3、对排序逆序
4、可以将非同步的集合转成同步的集合
Arrays:用于操作数组的工具类,类中定义的都是静态工具方法。
1、对数组排序
2、二分查找
3、数组复制
4、将两个数组进行元素的比较,判断两个数组是否相同
5、将数组转成字符串
6、将数组转成list集合(asList方法),为了使用集合的方法操作数组中的元素
注意:数组长度是固定的,在转成集合后,长度也是固定的,所以不要使用集合的增删功能;如果数组中存储的是基本数据类型,那么转成集合后,数组对象作为集合中的元素存在;如果数组中元素是引用数据类型时,转成集合后,数组元素作为集合元素存在。

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)