《Kubernetes与云原生应用》系列之四——实践案例“单节点多容器模式”
原文转自InfoQ一、K8s与容器设计模式目前K8s社区推出的容器设计模式主要分为三大类:单容器管理模式单节点多容器模式多节点多容器模式一类比一类更复杂。根据复杂性的不同,本系列文章给出不同篇幅的实践案例介绍。对于第一类,只在本文中用一小节给与介绍;对于第二类,在本文中,针对每一种典型设计模式分一个小节给予介绍;对于较复杂的第三类,每一种典型设计模式将用一篇文章给予介绍。二、单容器管
一、K8s与容器设计模式
目前K8s社区推出的容器设计模式主要分为三大类:
- 单容器管理模式
- 单节点多容器模式
- 多节点多容器模式
一类比一类更复杂。根据复杂性的不同,本系列文章给出不同篇幅的实践案例介绍。
对于第一类,只在本文中用一小节给与介绍;
对于第二类,在本文中,针对每一种典型设计模式分一个小节给予介绍;
对于较复杂的第三类,每一种典型设计模式将用一篇文章给予介绍。
二、单容器管理模式
K8s的最大特色是支持多容器的微服务实例。当然,单容器的模式也是支持的,只不过这种模式并不能突出K8s的特色和强大。很多人对K8s一直以来的印象是:功能强大,但入门较难。其实,单单就启动一个单容器微服务实例,K8s的命令行操作跟Docker原生命令一样简单。
运行一个nginx容器
# kubectl run nginx --image=nginx
deployment "nginx" created
# kubectl get deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx 1 1 1 1 24s
# kubectl get rs
NAME DESIRED CURRENT AGE
nginx-3137573019 1 1 1m由上面的例子可以看到,K8s只要一个命令就可以启动以nginx为镜像的一个微服务实例。与此同时,K8s的强大之处在于,方便用户用一个命令的同时,仍然保证了K8s应用体系的完整性和规范性。也就是说,虽然用户只运行了一个命令,但K8s为用户自动创建了四种API对象,包括:Deployment,ReplicaSet(RS),Pod和Container,要想伸缩同一服务的实例个数也非常简单。
# kubectl scale deployment nginx --replicas=3
deployment "nginx" scaled
# kubectl get rs
NAME DESIRED CURRENT AGE
nginx-3137573019 3 3 22m依靠这种兼顾易用性和模型一致性的设计理念,K8s使自己既适合简单场景也适合复杂场景。
三、单节点多容器模式
从单节点多容器模式开始的容器设计模式,是真正体现K8s设计特点的地方,也就是基于多容器微服务模型的分布式应用模型。在K8s体系中,Pod是一个轻量级的节点,同一个Pod中的容器可以共享同一块存储空间和同一个网络地址空间,这使得我们可以实现一些组合多个容器在同一节点工作的模式。既然Pod的特点是共享存储空间和网络地址,那么单节点多容器模式一定是利用这两种特性的。
1.挎斗模式(Sidecar pattern)
第一种单节点多容器模式是挎斗模式。这种模式主要是利用在同一Pod中的容器可以共享存储空间的能力。
应用场景a
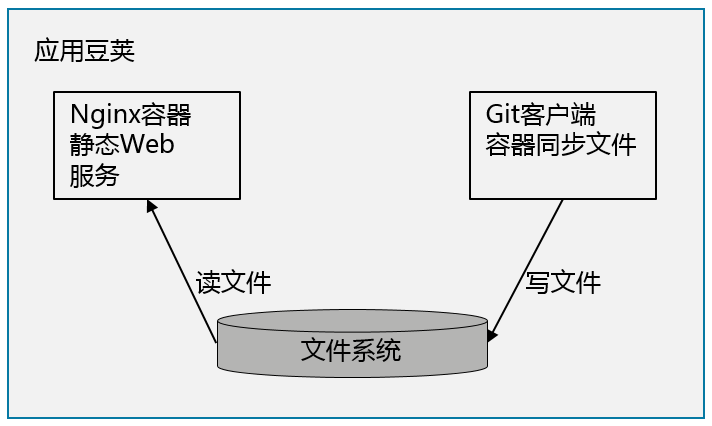
一个工具容器写文件到共享的文件目录,应用主容器从共享的文件目录读文件。例如 : 我们可以用Nginx构建一个代码发布仓库,简单的将代码放到某个本地目录即可。为了保持同步,我们同时用一个装有Git客户端的容器定时到原始代码仓库同步下拉最新的代码。这种模式的好处是,工具容器的镜像,也就是打包有Git客户端的镜像可以重用,而不需要跟应用的容器打包在一起。同样的应用,应用主容器用Nginx,也可以用Apache Httpd,都可以跟工具容器组合起来形成微服务。
应用场景b
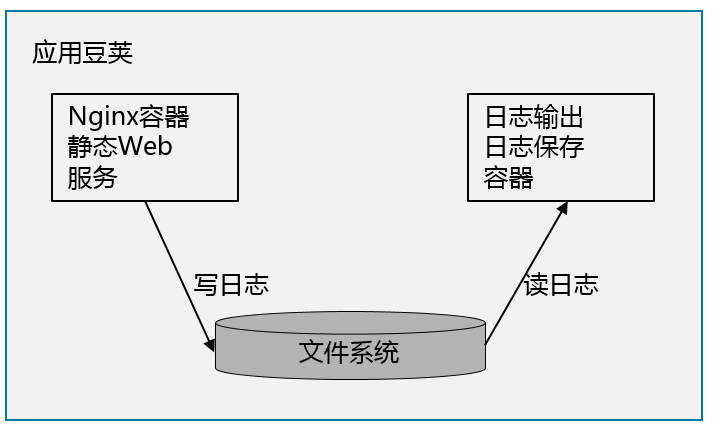
一个工具容器读文件,应用容器写文件。例如:一个基于Nginx的Web应用向文件系统写入日志,而一个收集日志的容器从共享目录读出日志,并输出到集群的日志系统。这一模式的好处在于,工具容器的镜像是可以重用的,不需要在每次更新应用容器打包的时候,把工具容器的执行文件打包进去。
2.外交官模式(Ambassador pattern)
第二种单节点多容器模式是外交官模式。这种模式主要利用同一Pod中的容器可以共享网络地址空间的特性。
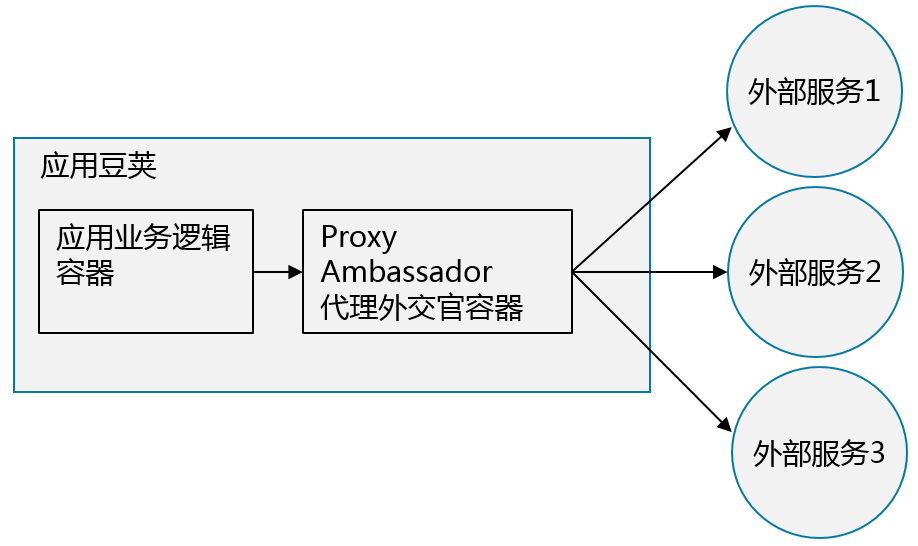
如图所示,在一个Pod中给应用容器搭配一个工具容器作为代理服务器。
工具容器帮助应用容器访问外部服务,使得应用容器访问服务时不需要使用外网的IP地址,而只需要用localhost访问本地服务。在这种模式下,作为代理服务器的工具容器好像外部服务派驻在Pod中的“外交官”,使得应用容器办理业务时只需要跟本Pod的外交官打交道,而不需要出国,因此而得名。
实例:基于外交官模式的Redis访问演示案例
我们这里用一个访问Redis服务的简单案例,来实践体验一下Ambassador模式和K8s单节点多容器模式的应用细节。本案例的文件清单在Github上。
2.1 创建一个Redis Master节点的Pod
该Pod用于初始化Redis集群。
# kubectl create -f /examples/redis/redis-master.yaml2.2 创建一个redis的服务
这个服务可以在前端作为多个redis Pod节点的负载均衡。
# kubectl create -f /examples/redis/redis-service.yaml2.3 创建redis的replication controller
创建控制多个redis服务Pod的RC,当然也可以用Deployment或ReplicaSet来创建。
# kubectl create -f /examples/redis/redis-controller.yaml
# kubectl get rc
NAME DESIRED CURRENT AGE
redis 1 1 19h创建完后可以用# kubectl get rc 与# kubectl get Pod命令查看rc和Pod,会发现并没有产生新的Redis Pod,这是因为原来的Pod redis-master已经满足了replica=1的要求。
2.4 创建redis-sentinel的服务
# kubectl create -f /examples/redis/redis-sentinel-service.yaml2.5 创建控制多个redis sentinel服务Pod的RC。
# kubectl create -f /examples/redis/redis-sentinel-controller.yaml2.6 将redis实例和redis-sentinel实例扩展成3个
# kubectl scale rc redis --replicas=3
# kubectl scale rc redis-sentinel --replicas=32.7 删除手工启动的redis实例redis-master
删除掉我们手工创建的redis master的Pod,redis的rc会自动启动新的redis pod以满足replicas=3的要求。同时,Redis sentinel节点会选举出一个新的节点作为master节点。
# kubectl delete pods redis-master2.8 查询redis集群中所有redis实例的IP
# kubectl describe pod -l name=redis | grep IP
IP: 10.120.44.3
IP: 10.120.63.3
IP: 10.120.80.5我们知道,这3个redis实例中,只有一个是Master节点,是可写的,可以调用SET命令和GET命令;其他两个节点是Slave节点,是只读的,只能调用GET命令。我们可以用下面的命令测试三个redis节点。
# echo -e "SET test1 SET test1 8\r\nQUIT\r\n" | curl telnet://10.120.44.3:6379
-READONLY You can't write against a read only slave.
+OK
# echo -e "SET test1 8\r\nQUIT\r\n" | curl telnet://10.120.63.3:6379
-READONLY You can't write against a read only slave.
+OK
# echo -e "SET test1 8\r\nQUIT\r\n" | curl telnet://10.120.80.5:6379
+OK
+OK通过上面的测试我们可以知道只有IP为10.120.80.5的redis pod是Master节点,其他两个是slave节点。
对于只读的操作,我们可以利用redis的service IP,通过K8s的kube-proxy来访问,如下,我们得到redis的CLUSTER-IP为10.123.248.129,可以用这个IP来读取Redis数据。那么,如果用这个IP来写数据将怎么样呢,后面将看到。
# kubectl get svc -l name=redis
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
redis 10.123.248.129 <none> 6379/TCP 5d
# echo -e "GET test1\r\nQUIT\r\n" | curl telnet://10.123.248.129:6379
$1
8
+OK2.9 制作Ambassador容器镜像
截至目前,我们还没有用到外交官模式。下面我们用Haproxy制作一个外交官代理,用来访问Redis服务,使得跟该容器在同一个Pod里的容器,在访问Redis读写服务的时候,都只需要访问本地localhost服务。本例中的文件在Github上可以找到。
Dockerfile文件清单:Dockerfile
FROM haproxy:1.5
COPY tmpl-haproxy.cfg /
COPY starthaproxy.sh /
CMD ["sh"Node.js "-c"Node.js "/starthaproxy.sh"]启动haproxy的文件清单:starthaproxy.sh
echo "Proxying localhost ${INPUT_PORT} to ${TARGET_IP}:
${TARGET_PORT}"
cat tmpl-haproxy.cfg | sed -e "s/INPUT_PORT/${INPUT_PORT}/" -e "s/TARGET_IP/${TARGET_IP}/" -e "s/TARGET_PORT/${TARGET_PORT}/" > /haproxy.cfg
haproxy -f /haproxy.cfg通过这里的Dockerfile构建的代理服务器容器,根据输入的环境变量INPUT_PORT、TARGET_IP和TARGET_PORT,可以将发向本地INPUT_PORT的服务请求转发到目标TARGET_IP:TARGET_PORT上去。
因此这个容器可以作为一个简单方便的本地代理服务器使用。
2.10 使用Ambassador代理服务器的pod
使用Ambassador代理服务的Pod文件清单:demo-redis-amb-centos.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
name: demo-redis-amb-centos
name: demo-redis-amb-centos
spec:
containers:
- name: app-main-container
image: centos:7
args:
- sleep
- "1000000"
- name: redis-amb-read
image: xwangqingyuan/port-forward-haproxy
env:
- name: INPUT_PORT
value: "6379"
- name: TARGET_IP
value: "10.123.248.129"
- name: TARGET_PORT
value: "6379"
ports:
- containerPort: 6379
- name: redis-amb-write
image: xwangqingyuan/port-forward-haproxy
env:
- name: INPUT_PORT
value: "16379"
- name: TARGET_IP
value: "10.120.80.5"
- name: TARGET_PORT
value: "6379"
ports:
- containerPort: 16379
volumes:
- name: data
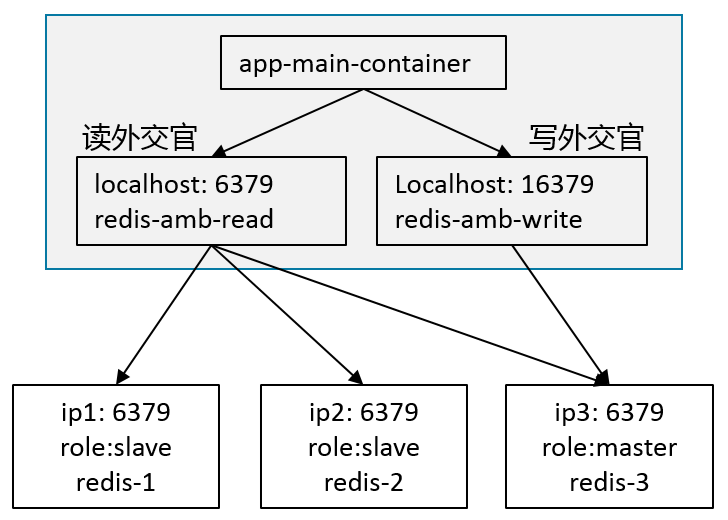
emptyDir: {}在这个Pod中,我们用一个CentOS容器作为应用的主容器来使用Ambassador工具容器,当然也可以用实际的应用容器Tomcat、Node.js、PHP等等,因为这里只是为了演示测试Ambassador代理,我们用CentOS作为应用容器。其中我们有两个外交官容器,一个用来从Redis集群读数据,容器的名字为redis-amb-read,它将发向本地6379端口的请求转发到redis服务的CLUSTER-IP,最终会轮训地发送给任意一个redis实例;另一个用来向Redis集群写数据,容器的名字为redis-amb-write,它将发向本地16379端口的请求转发到redis master Pod的IP。
2.11 测试一个使用Ambassador模式的pod
创建一个使用Ambassador代理的Pod,并登陆到主容器进行测试
# kubectl create -f /home/centos/worktemp/redis/demo-redis-amb-centos.yaml
# kubectl exec -it demo-redis-amb-centos /bin/bash测试对读容器本地Ambassador的访问。
# echo -e "SET test1 10\r\nQUIT\r\n" | curl telnet://localhost:6379
-READONLY You can't write against a read only slave.
+OK
# echo -e "SET test1 10\r\nQUIT\r\n" | curl telnet://localhost:6379
-READONLY You can't write against a read only slave.
+OK
# echo -e "SET test1 10\r\nQUIT\r\n" | curl telnet://localhost:6379
+OK
+OK
# echo -e "GET test1\r\nQUIT\r\n" | curl telnet://localhost:6379
$2
10
+OK
# echo -e "GET test1\r\nQUIT\r\n" | curl telnet://localhost:6379
$2
10
+OK
# echo -e "GET test1\r\nQUIT\r\n" | curl telnet://localhost:6379
$2
10
+OK从测试结果可以发现,对读容器执行GET操作时,操作总是成功的,说明3个redis pod都可以读取数据。而对读容器执行SET操作时,3个操作只有一个是成功的,也就是说只有负载均衡将请求发给redis master pod时,操作能够成功。
测试对写容器本地Ambassador的访问。
# echo -e "SET test1 10\r\nQUIT\r\n" | curl telnet://localhost:16379
+OK
+OK
# echo -e "SET test1 10\r\nQUIT\r\n" | curl telnet://localhost:16379
+OK
+OK
# echo -e "SET test1 10\r\nQUIT\r\n" | curl telnet://localhost:16379
+OK
+OK从测试结果可以发现,对写容器执行SET操作时,操作总是成功的,说明redis-amb-write容器将所有请求都转发给了redis master pod。
3.适配器模式(Adapter pattern)
这种模式对于监控和管理分布式系统尤为重要。对分布式系统的一种理想设计目标,就是能够实现“分布地执行和存储,统一的监控和管理”。要想实现“统一的监控和管理”,应用和监控管理交互的接口需要是统一的,而且其接口是依照“统一的监控服务”的接口模式来实现。这和面向对象设计模式中的“适配器模式”也非常相似。
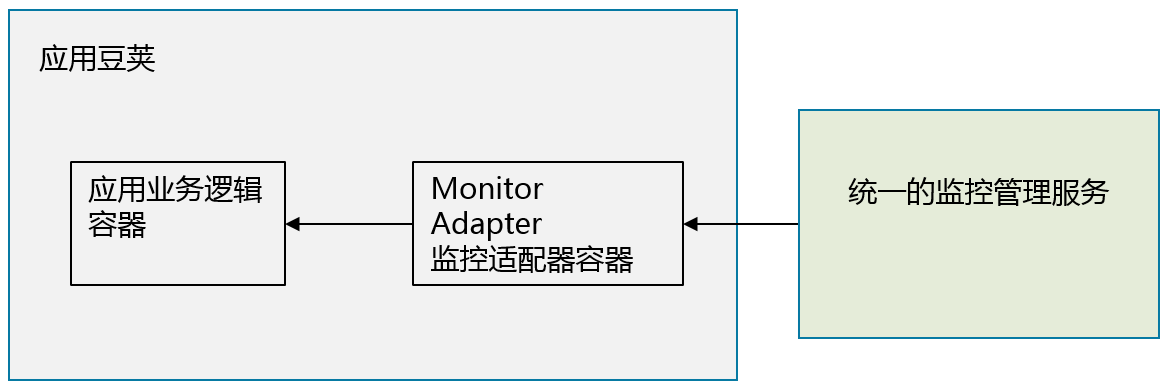
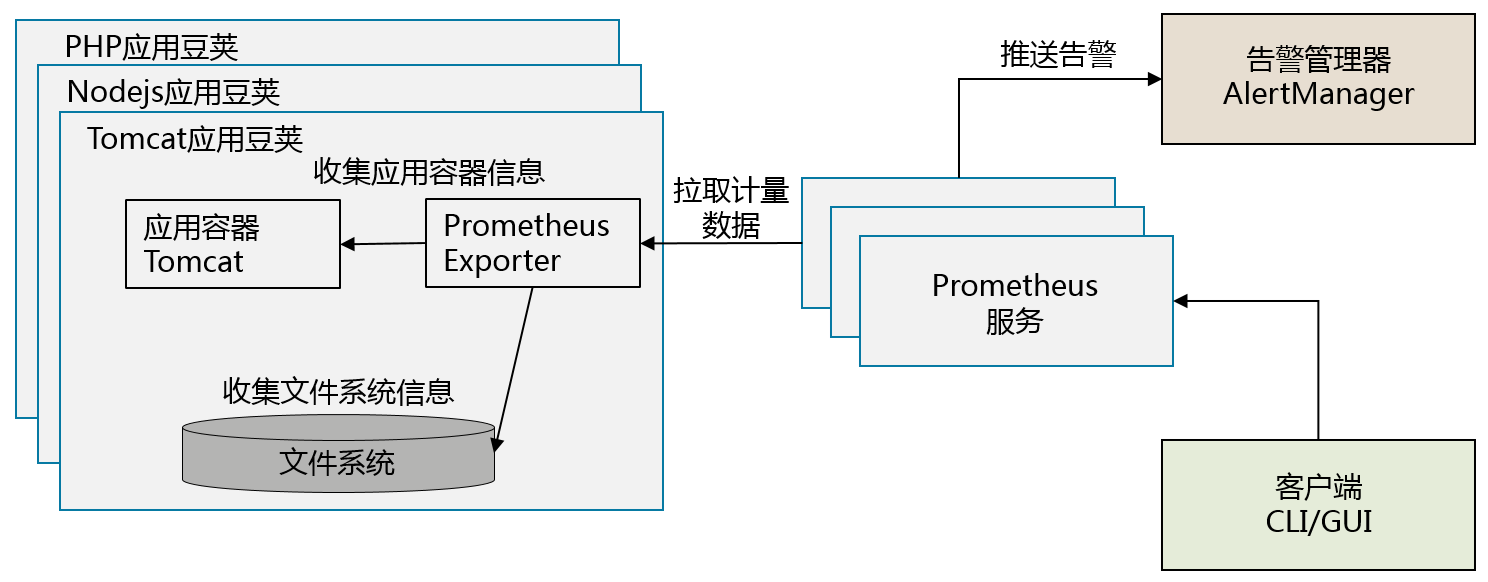
一个典型的可以采用适配器模式的系统,是利用Prometheus作为监控服务的分布式系统。在Prometheus周边项目中,有诸多适用于不同应用系统的监控数据输出器(Exporter),负责收集跟特定应用相关的监控数据,使得Prometheus服务可以以统一的数据模式收集不同应用系统的监控数据,每个Exporter同时也都是一个适配器模式的实现。
总结
本文主要介绍了K8s集群中,单节点单容器模式和基于Pod模型所支持的几种单节点多容器模式,包括挎斗模式、外交官模式和适配器模式。并且对于外交官模式,利用一个redis集群案例演示了如何利用外交官模式以访问本地服务的模式访问网络服务。
后续,K8s社区肯定还会发展出其他的容器设计模式,但不论如何,单节点多容器模式主要是利用同一Pod中的容器可以共享存储空间和网络地址空间的特点。本文案例中的代码只能用来演示,还比较简单,有很多的地方可以增强。例如:用Replication Controller的地方,可以用Deployment或Replica Set来部署,这是K8s社区更为推荐的方式;对于案例中的外交官容器,Master Pod的IP和Redis服务的IP未必需要写死,而是可以通过脚本从指定的服务读取;此外,演示中所用的代理服务器容器也可以增强为支持多个端口映射的代理服务器。
FA&Q
问:考虑到性能,分布式文件存储可能不会适合,K8s有没有针对database的略微完美的部署方案?
王昕:完美的应该没有。有两个K8s功能可能跟database的存储有关,一个是nodeAffinity一个是PetSet。
nodeAffinity的作用是让你可以为Pod选定特定的节点运行,例如你想要的高性能的挂载了SSD的节点。PetSet的作用是让Pod可用于有状态服务,可以固定跟某个存储绑定。这两个功能都处于非常早的阶段还很不成熟,但可以肯定这些功能是K8s社区专门解决有状态服务和存储问题的方案。
在nodeAffinity和PetSet设计稳定之前,还有一个nodeSelector也是可以利用的。它可以让用户选定特定的node部署Pod,同样,你可以选定挂有高性能存储的节点。
问:希望更深层次了解一下Overlay的网络原理,能否介绍一下?
王昕:Overlay也就是覆盖网络,跟隧道技术是紧密相关的,通过网络封装技术模拟二层网络,跟VPN所采用的技术是类似的。
简单说,比如A和B之间是没有网络直接用以太网连接的,就是所谓的二层不连通。但是通过三层的IP层可以连通,也就可以建立四层的连接,比如UDP可以连通,也就是四层连通,二层不连通。但是我可以,通过四层的连通传输二层以太网的数据包,模拟出一个二层连通的以太网来。这个模拟出来的连通的二层网络就叫Overlay,下面真实的物理网络叫做Underlay。
所以说,Overlay的技术每一层封装会增加一些开销,会影响一定性能。此外,各个层次对网络丢包延迟的问题处理不好,也会影响性能。K8s比较流行的基于Overlay的组网技术有Flannel和Weave,Weave目前看性能是比较差的。Flannel有两种隧道封装技术,UDP和VxLAN,一般来说VxLAN性能比UDP好很多。Overlay有一定的性能劣势,也有优势,主要是降低对下面物理网络的依赖,很容易搭建。

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)