学习笔记:Deep Learning(一)入门
学习笔记:Deep Learning学习资料:优达学院课程《Deep Learning》,Google首席科学家Vincent Vanhoucke讲解视频。下文的大部分内容,我会按照课程分享,也会加上自己的理解。学习笔记Deep Learning从机器学习到深度学习softmax functionone-hot编码cross entropy交叉熵multinomial logistic分类
学习笔记:Deep Learning
学习资料:优达学院课程《Deep Learning》,Google首席科学家Vincent Vanhoucke讲解视频。
下文的大部分内容,我会按照课程分享,也会加上自己的理解。
从机器学习到深度学习
机器学习的分类算法我们都比较熟悉,对于监督学习,最简单的分类器是线性分类器,公式如下:
X表示输入,y表示label,W表示weigh,b表示bias,W和b是参数。我们说要训练分类器,就是要找到合适的W和b,使得y的表现很好。
接下来介绍三个需要理解的知识点,了解了这三点,就可以构建一个简单的多项逻辑分类器了。
1. softmax function
假如现在有个输入X,带入我们的分类器得到的结果如下:
我们想要将y的得分转化为概率表示: ⎡⎣⎢0.70.20.1⎤⎦⎥
这时,就需要用到softmax函数。它的表现形式如下:
softmax函数经常用于神经网络的最后一层,作为输出层,进行多分类。
softmax和logistic的关系:logistic函数是softmax函数的一种特殊表现,当分类数为2的时候,softmax就是logistic函数,推导过程略。
代码
import numpy as np
def softmax(x):
return np.exp(x) / np.sum(nu.exp(x), axis=0)
print softmax([2.0, 1.0, 0.1])
详细内容移步:
logistic函数和softmax函数
UFLDL教程之softmax回归
2. one-hot编码
one-hot编码很好理解,就是将概率最大的类别设为1,其他类别设为0,这样每个label表示为一个向量。
可以这样理解,对于每一个特征,如果它有m个可能值,那么经过one-hot编码后,就变成了m个二元特征。并且,这些特征互斥,每次只有一个激活。因此,数据会变成稀疏的。
这样做的好处主要有:
1. 解决了分类器不好处理属性数据的问题
2. 在一定程度上也起到了扩充特征的作用
3. cross entropy交叉熵
交叉熵一般在神经网络中作为损失函数使用,用D(p,q)表示交叉熵,意思是用预测分布q来表示真实分布p的平均编码长度。p和q之间差异越大,交叉熵越大,反之越小。
其中,S表示softmax函数得到的得分,L表示one-hot label的结果。
参考博客:
交叉熵代价函数
multinomial logistic分类器
这样,我们就得到了最简单的线性分类器网络:
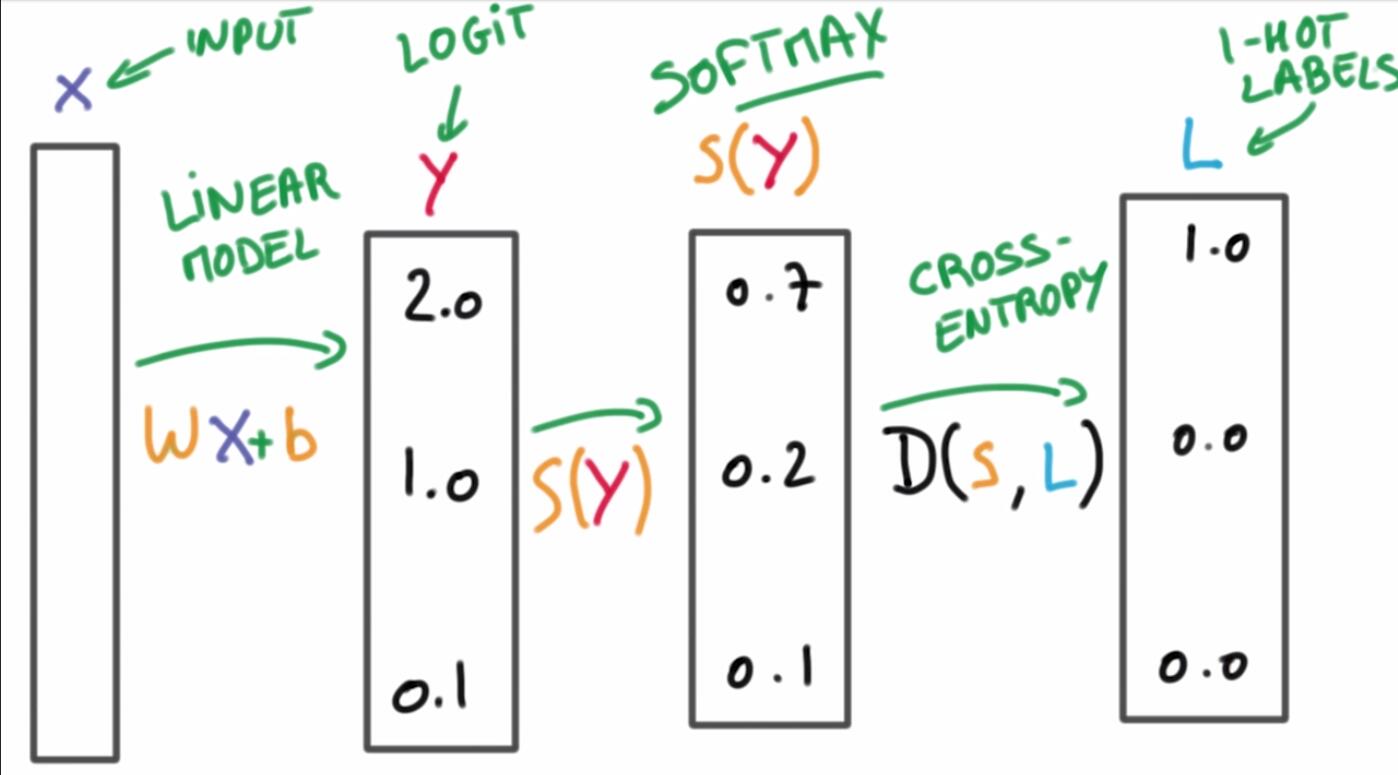
问题来了,如何得到W和b两个参数呢?
方法之一是通过计算训练集的loss,是的L最小:
优化方法有:
1. 梯度下降GD
2. 随机梯度下降SGD(SGD是深度学习的核心)
3. AdaGrad
深度神经网络以及正则优化方法
卷积神经网络CNN(Convlutional Network)
循环神经网络RNN(Recurrent Network)

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)