
Mesos容器网络解决方案
CNUTCon2016已经落下帷幕,但是其精彩内容我们还在久久回味。今天小数为大家带来的是数人云CTO肖德时在容器大会上的演讲实录,从理论说起,将实践进行到底,让我们一起来探讨容器网络的问题以及解决Mesos是数人云的主要的技术栈之一,并且我们很早就开始在实践Mesos应用。从数人云的角度,我们希望容器的快速分发能够帮助客户实现快速交付。现在Mesos社区的发展非常快,Mesos有一个
CNUTCon2016已经落下帷幕,但是其精彩内容我们还在久久回味。今天小数为大家带来的是数人云CTO肖德时在容器大会上的演讲实录,从理论说起,将实践进行到底,让我们一起来探讨容器网络的问题以及解决
Mesos是数人云的主要的技术栈之一,并且我们很早就开始在实践Mesos应用。从数人云的角度,我们希望容器的快速分发能够帮助客户实现快速交付。现在Mesos社区的发展非常快,Mesos有一个重要的特性Unified Container,让Mesos可以交付容器。而接下来有一个更热的话题—— 一容器一IP,在当前容器圈用网络方案如何解决这个问题,大家各显神通,但是真正能把网络和容器说清楚的并不是特别多,结合数人云长时间的积累和实践,在这里我想跟大家一起探讨容器的网络以及Mesos的解决方案,为大家提供一个参考。
Mesos的网络问题
Mesos 1.0其实已经有了一个完整的容器Interface的规范, CNCF(Cloud Native Computing Foundation)提供了Container Network Interface的接口,希望在Mesos社区里规范网络的使用,让大家有一个接口能够复用网络。刚刚发布的Mesos 1.0会遇到一些问题。最常见的就是我们无法逾越的一容器一IP,对于这个问题大家都有各自的看法,但是Mesos的过程里面是sandbox,是没有IP的概念的,所以要思考如何用容器的方式获得IP。
第二,有了IP接着会出现服务发现的问题,什么是服务发现?最简单的是DNS,一个名字对多个IP。第三,有了网络之后,所有的数据之间有了联系,它们之间如何隔离是一个问题。例如,有一个数据库专门为业务A使用,另外一个数据库供业务B使用,就有两个Wordpress,这两个多租户之间没有任何的联系,我们希望它们之间的网络是隔离的, Mesos有一个可以让大家立即使用的解决方案是Calico这个项目,虽然也有商业的公司在做这个项目,但是它的源码和思想是可以被复用的,所以我这次主要是与大家分享一容器一IP实现的方式。
实现一容器一IP为什么选择Calico?
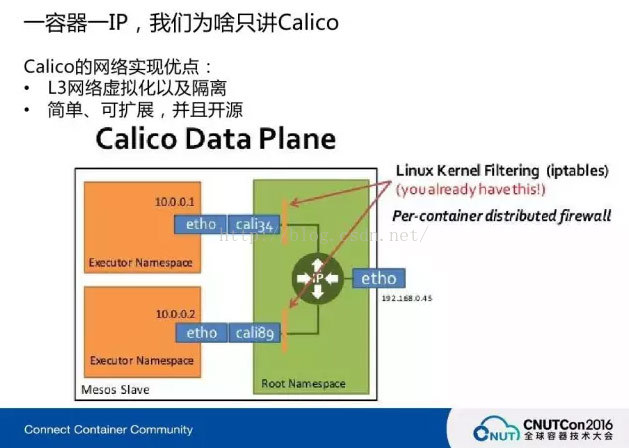
一台机器有自己的MAC地址,常规的主机上有自己的IP,MAC地址跟IP之间是有关联的,也有三层的概念在里边,但是这是主机的网络,容器起来以后也是有MAC地址的,但是它是一个虚拟的MAC地址,如何获得一个真实的IP或者想要给它分配的IP,就引出了一个概念——L3的虚拟网络,可以在没有真实MAC地址或者MAC地址是一样的情况下能给它分配不同的IP。Linux的Kernel有Filter的概念,可以对数据流进行转换,在前面可以打包头,我们就可以在Linux完整的基础之上在路由的规则上做判断, Linux Bridge模式的话是可以造IP的, Calico项目源码的基础就是Linux的这个能力。之所以每个容器之间有隔离的作用,是因为它可以对每一个容器分不同的网段,网段之间是隔离的,本来两个网段之间就没有路由规则,无法相通。

Mesos有一个CNI的支持为什么非常重要?之前使用Mesos和Doker的时候,我们有很多方式可以获得IP,但这些方式对于Mesos生态圈里面来说很难有规范, Mesos发展到如今已经把Doker去掉,对于网络这部分它需要一个规范,这个规范就是CNI规范。CNI规范是一个Json,这个Json非常简单是一个很好的语义,而且它可以支持IPV4,以及之后的IPV6。一个配置文件能够描述整个网络结构已经足够,有了CNI之后有很多种实现,Calico只是其中一种,大家会看到有硬件的、有Contive、有Weave,有Vxlan的模式等等,它们内部其实都有Overlay的模式。

Mesos本身是为数据中心设计的一套集群,需要了解数据中心的网络结构有两个非常关键的指标——南北的数据流和东西的数据流,南北的数据流就是从数据中心外面到数据中心内部的数据流。网络结构可能有路由器,网关,下面可能有LoadBalance,但它跟容器相关的网络是没有关系的。我们通过容器的方式,类似于是想水平扩展的,基于这个网络的概念,我们提出想要一个比较复杂的网络结构。
互联网公司普遍是内存比较小但机器比较多,常常一两千台机器;但有的传统企业用的是大型机或者用的机器都比较大,他们的机器四五台机就能组成一个网络,内存比较多,一台机器可以跑两三百个容器,四五台机器能跑几千个容器,这就是Clico和一些第三方的解决方案要解决的问题——管理IP的网段,因为IP地址是有限的,并且真实的网段是一套,而所有的这些分的IP的网段也是真实的,要去管理它的冲突。现在大家想到的是自己搞一个IP的管理界面,对IP进行管理把它固定住,但当容器越来越多的时候,就会有很多问题。
针对数据中心东西向的解决方案,Calico提出的一种方法是基于BGP协议。BGP协议是对路由规则进行控制,也就是说在没有MAC地址的情况下,路由有路由表,路由表多了以后有两件事,第一是要广播,第二是这个路由表大了,软件模拟的方式会有性能瓶颈,并且还要做精细化的访问控制。因为两个网段之间用的虚拟网段,有可能会冲突,一两个网段的时候可能没有问题,当几十个APP之间隔离的时候两个虚拟网段用的可能是同样的IP地址,要保证它们两个不通,如果通的话还要保证两个IP不能冲突。那么有没有更好的方式?有,就是MAC Vlan——用主机的方式管理虚机。
这与Host的模式(不用自己的虚拟网络,用原生的主机模式网络)相比,只是加了一层MAC地址的管理。但是它有一个比较大的问题是对硬件有依赖,因为MAC是要转IP的,而IP地址一定是有限的,MAC地址也是有限的,如果有冲突都是靠硬件来控制的,它并不能很轻易地上云,云端MAC地址不受控制,基本上是在私有云的基础上用MAC Vlan的方法去做。对于Mesos的解决方案我们希望的是通用型的,有一个网络标准CNI, Calico是比较灵活的而有保障的。这是今天推荐这样一个方案的原由。

在学习网络的过程中,有几个知识比较重要。首先,什么是三层网络?其实就是二层交换,三层路由。当前的路由器已经非常先进, Overlay最大的一个特点就是利用了路由这样一个基本的知识点。大家会看到从S0这一块进来以后一定是一个路由表,路由表之后会制定一些policy,然后到每一个网卡上再去劫持,去做一个路由表和一些规则,到机器上以后这个Brige有了一个新的网卡,是不依赖于MAC地址的,它的好处在于可以连接一个非常大的网,容器可以随意的起,起几百个容器都能连起来,我们只需把网配好就可以了。
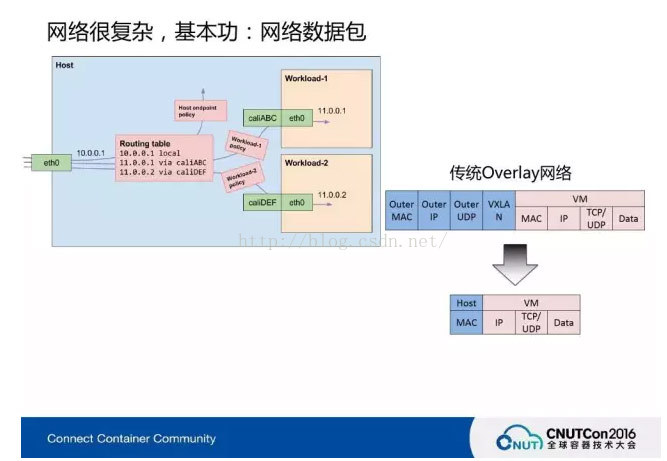
但是传统Overlay因为功能太强、太先进,一定要打无数个包头才能从最远端到里边。Vxlan以最新代表的SDN的网络非常先进,但是软件模拟这种网络是非常脆弱的,规模越大效率越低,因为最简单的问题就要解包、拆包,拆到最后拆到MAC地址和IP。网络数据包有拆包、解包的过程,只有让它少一点拆包解包的能力,这样速率才会高。通俗地说,当前所有用Doker网络的解决方案都是有损耗的,除非不使用或者使用Vxlan,Vxlan也没有用虚拟网络,所有的虚拟网络都是有损耗的,所以目前无损耗的方式是不可能做到的。
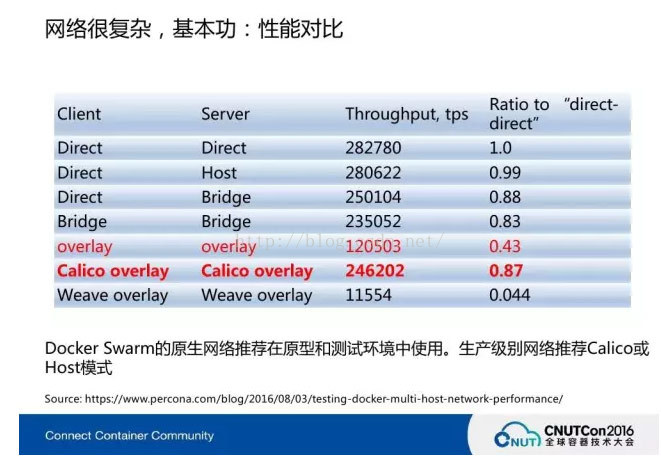
这个包头或者路由表在规则少、规模小的时候,效率还是很高的。上图两行红字,第一个是Overlay对Overlay的,这是纯的Vxlan的网络,像Docker的Swarm就用这种原生的网络创建,它的问题就在于它是虚拟的去转换,所以整个网络非常弱,损耗只能到40%,60%都损耗掉了。并不是说网络不先进,瓶颈在于它实现的是一个参考,如果用硬件或第三方的结构,用Docker Swarm解决不了,那么网络基本上是不可用的。第二个是Calico的Overlay,损耗差不多也是百分之十几,是目前为止我们看到的一个最好的方式。这个基础数据来自Percona这个公司,它做的MySQL发行版,在Master和Slave之间做同步,数据量增大这个瓶颈才能压测出来,从而得到这个基础数据报告。
Doker非常好用,但是Doker内置Swarm的特性,Doker Swarm就是两行命令就能创建的网络,非常简单。这个网络非常适合在测试环境和在单机的模式下调试网络,它有自己的DNS、名字、网络IP,也可以自己管理,非常方便。但是到了生产级别用网络Mesos容器方案的时候,Calico这个方案可以帮助大家更好地理解和解决这个问题。
Calico是如何做的?
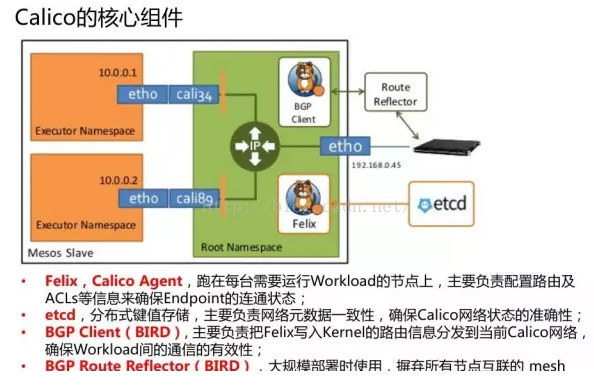
在上图中,它的原理是IP Table,使用了Calico的组件,用BGP去做,其中一个关键点就是它要保存这个路由规则,还要刷每台机器的路由。它首先要用etcd保存这些信息,因为本地无法存储,要保证一致性。第二,它的路由表要刷给别的机器,每台机器都要去传,所以每台机器都是跟etcd有关联的,触发BGP去刷。它是无中心的,每台机器刷完以后,这边路由表规则一变,Mesos所有机器的路由表就变了,看起来好像网是通了。因为每台机器出来的时候走的是S0的IP,到那边的时候也是S0,但是路由做了规则转换,所以两边都是通的,能跨主机的IP实现了这样的过程。
这里它做了一个小小的手术,因为网络结构越复杂,要对封包做的越多,在这个网段里面跳一下的时候需要给消息包头打个标签,IP要打不同的标签,才能到那个网络里面。它做了一个权衡,认为网络不要太多,可能就是一百台机器的规模,因为有ARP广播,广播风暴在网络里面非常常见,Mesos本身又不管网络。 Calico现在的做法就是在中间加了一个Route Reflector。BIRD也是第三方的,是Linux路由表的一个存储,它利用第三方的存储来存储自己的路由规则,然后保证这个路由规则能够被其它方主动去抓,这样就从原来推的方式变成抓的方式,简单地解决了这个问题。Mesosphere就是参考这个实现了一套类似于Calico的网络方案,叫Minuteman,也是开源的,在open dcos上面有这样一个方案,大家可以去参考。这个就是Calico具体的实现。
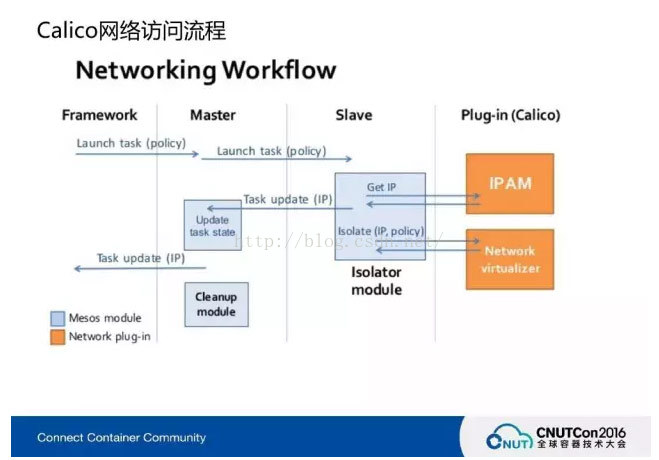
对于Mesos的网络结构,要有Framework的概念,也要有Slave、Executer的概念。Launch Calico做了一个插件安装在每台机器上,之后Framework调用、起一个任务的时候会劫持和触发IP规则的启用,Calico自己有IP management,下发到Slave那有一个隔离模块,做策略的隔离,获得IP做一个Policy,然后做一个隔离。这一块就是调用IP Table、IP Set去做,做完以后再去更新Master信息放到Zookeeper里面。然后获得了一个Task的IP。尤其像现在没有Doker的情况下,UnifiedContainerize 更是这种模型了。其实安装的组件就是一个Calico的BGP Agent,以及一个Felix,Agent刷本地的,Felix去刷别人的。
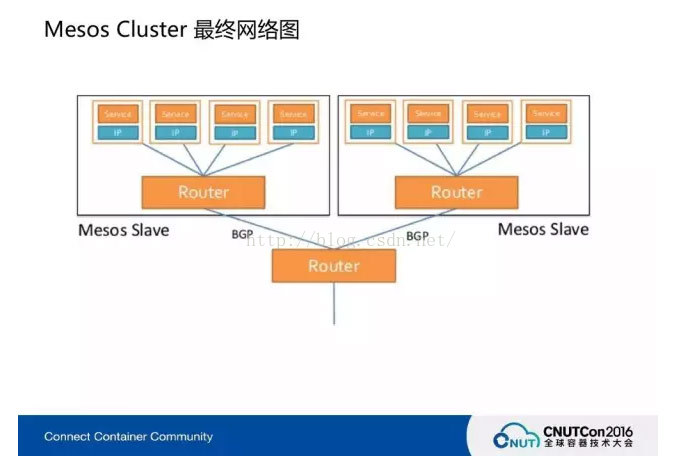
最终,Mesos目前真实的IP网络结构就是这样一个模型:每台机器上面有一个小路由器,我把它定义为是一个路由器,其实就是路由规则,它保存完以后每台机器里的容器的IP是可以不一样的,也可以一样的,但是左边的这台机器的IP跟右边这台机器的IP是不通的,路由表虽然刷了但是不通的。它可以通过广播的方式告诉右边的,右边再刷一下自己的路由规则,这边一访问的时候,因为用IP Table把它的Package切了,就类似于Router把它改了,destination也改了,传到另外一台机器上,那边也因为路由规则相应的做了转换,所以相应的加了路由的包到里边,容器知道这个数据包了就可以接通。Router这边它是模拟的、虚拟的,机器越多,由于它要主动去推,其性能就会下降。Calico的方式就是在外面再架一个中央路由器,然后让用户刷,再从中央路由器去取,这样就减少广播的节点。
Mesosphere最新的做法,是用的Erlang的模型做了一个P2P的网络结构。好处在于可以点对点地刷路由,也就是说这两台机器的应用之间有关联才去刷,如果没有关联,像Calico就刷一次,每个表都要刷,因为它不知道用户会不会在下一秒去启动新的容器,所以这种结构是传统的网络结构。但是Mesosphere的Minuteman做法就更先进一点,它的做法就是点对点地去刷,容器起来的时候去刷,局限性是只能在一个数据中心里面做这件事,因为它是一个实验型的项目,我们尚不清楚它的性能和规模,仅在此与大家分享一下。谢谢大家。

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)