Stanford CoreNLP 3.6.0 使用入门
Stanford CoreNLP由Java语言开发,是斯坦福大学自然语言处理小组的研究成果。包含自然语言处理的基本任务:分词、词性标注、依存句法分析、命名实体识别等等,支持多语言。项目地址:GitHub本文主要记录使用注意事项。Stage 1首先我们要下载 CoreNLP Java包。然后在Eclipse里面的Classpath里面引入jar文件。如下图红色框所示:CoreNLP只需
Stanford CoreNLP由Java语言开发,是斯坦福大学自然语言处理小组的研究成果。
包含自然语言处理的基本任务:分词、词性标注、依存句法分析、命名实体识别等等,支持多语言。项目地址:GitHub
本文主要记录使用注意事项。
##Stage 1
首先我们要下载 CoreNLP Java包。
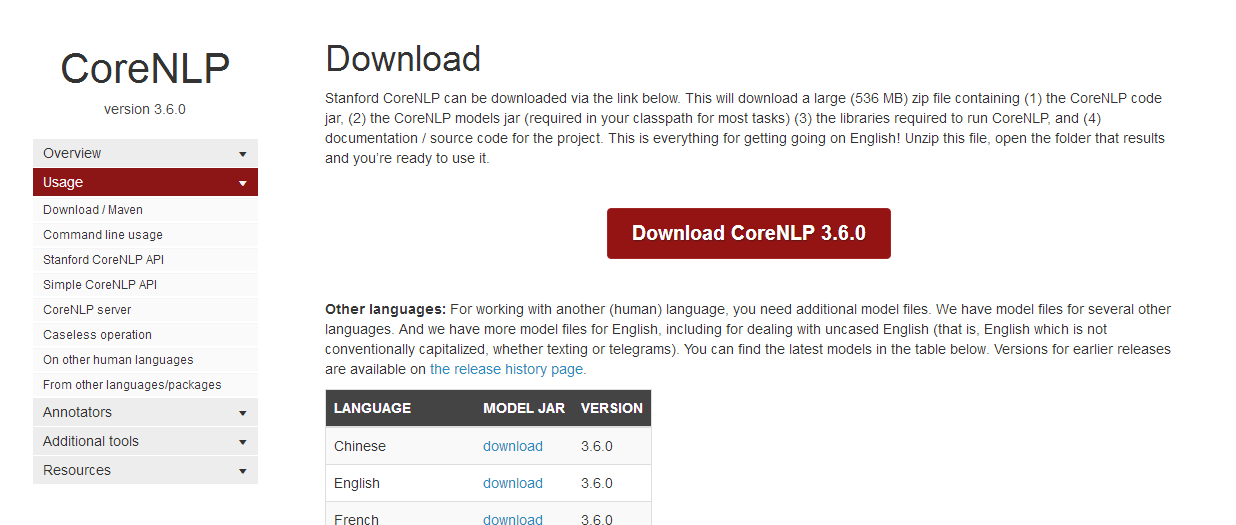
然后在Eclipse里面的Classpath里面引入jar文件。如下图红色框所示:
CoreNLP只需要引入jar文件就可以了,不用再引入其他文件。
然后代码送上:
package ...
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import edu.stanford.nlp.ling.CoreAnnotations.NamedEntityTagAnnotation;
import edu.stanford.nlp.ling.CoreAnnotations.PartOfSpeechAnnotation;
import edu.stanford.nlp.ling.CoreAnnotations.SentencesAnnotation;
import edu.stanford.nlp.ling.CoreAnnotations.TextAnnotation;
import edu.stanford.nlp.ling.CoreAnnotations.TokensAnnotation;
import edu.stanford.nlp.ling.CoreLabel;
import edu.stanford.nlp.pipeline.Annotation;
import edu.stanford.nlp.pipeline.StanfordCoreNLP;
import edu.stanford.nlp.util.CoreMap;
public class NlpUtil {
public static void main(String[] args) {
// creates a StanfordCoreNLP object, with POS tagging, lemmatization,
// NER, parsing, and coreference resolution
Properties props = new Properties();
props.setProperty("annotators", "tokenize, ssplit, pos, lemma, ner, parse, dcoref");
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
// read some text in the text variable
String text = "She went to America last week.";// Add your text here!
// create an empty Annotation just with the given text
Annotation document = new Annotation(text);
// run all Annotators on this text
pipeline.annotate(document);
// these are all the sentences in this document
// a CoreMap is essentially a Map that uses class objects as keys and
// has values with custom types
List<CoreMap> sentences = document.get(SentencesAnnotation.class);
List<String> words = new ArrayList<>();
List<String> posTags = new ArrayList<>();
List<String> nerTags = new ArrayList<>();
for (CoreMap sentence : sentences) {
// traversing the words in the current sentence
// a CoreLabel is a CoreMap with additional token-specific methods
for (CoreLabel token : sentence.get(TokensAnnotation.class)) {
// this is the text of the token
String word = token.get(TextAnnotation.class);
words.add(word);
// this is the POS tag of the token
String pos = token.get(PartOfSpeechAnnotation.class);
posTags.add(pos);
// this is the NER label of the token
String ne = token.get(NamedEntityTagAnnotation.class);
nerTags.add(ne);
}
}
System.out.println(words.toString());
System.out.println(posTags.toString());
System.out.println(nerTags.toString());
}
}
输出:
[She, went, to, America, last, week, .]
[PRP, VBD, TO, NNP, JJ, NN, .]
[O, O, O, LOCATION, DATE, DATE, O]
就这样愉快的搞定。
##Stage 2
然而…
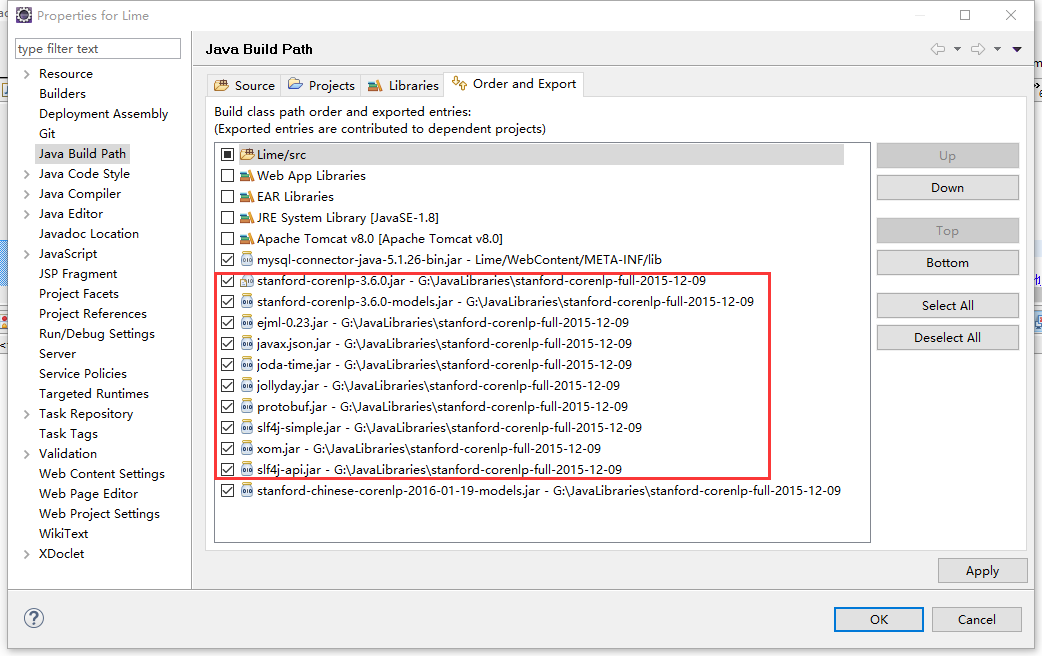
上面说的都是默认配置,默认是处理英文的,如果要进行中文处理,则还需要引入一个jar文件,下载stanford-chinese-corenlp-2016-01-19-models.jar:
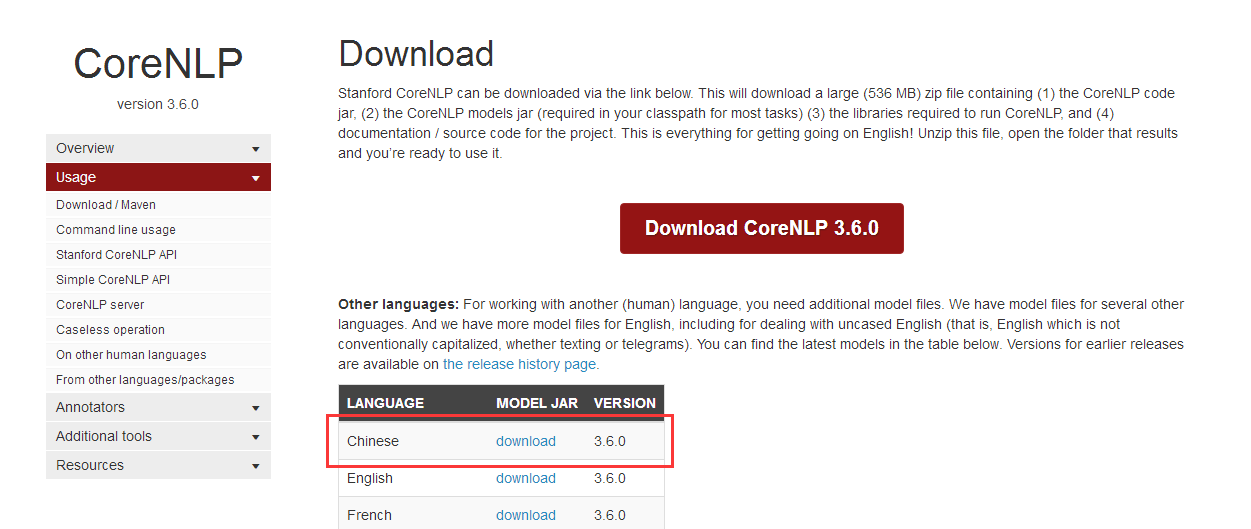
Classpath:

然后代码送上:
package ...
import edu.stanford.nlp.pipeline.Annotation;
import edu.stanford.nlp.pipeline.StanfordCoreNLP;
public class NlpUtil {
public static void main(String[] args) {
String text = "马飚向伦古转达了***主席的诚挚祝贺和良好祝愿。马飚表示,中国和赞比亚建交50多年来,双方始终真诚友好、平等相待,友好合作结出累累硕果,给两国人民带来了实实在在的利益。中方高度重视中赞关系发展,愿以落实两国元首共识和中非合作论坛约翰内斯堡峰会成果为契机,推动中赞关系再上新台阶。";
Annotation document = new Annotation(text);
StanfordCoreNLP corenlp = new StanfordCoreNLP("StanfordCoreNLP-chinese.properties");
corenlp.annotate(document);
corenlp.prettyPrint(document, System.out);
}
}
部分输出(新窗口打开可查看大图):

处理中文时经常出现OutOfMemoryError异常,设置运行时虚拟机堆大小就好了:
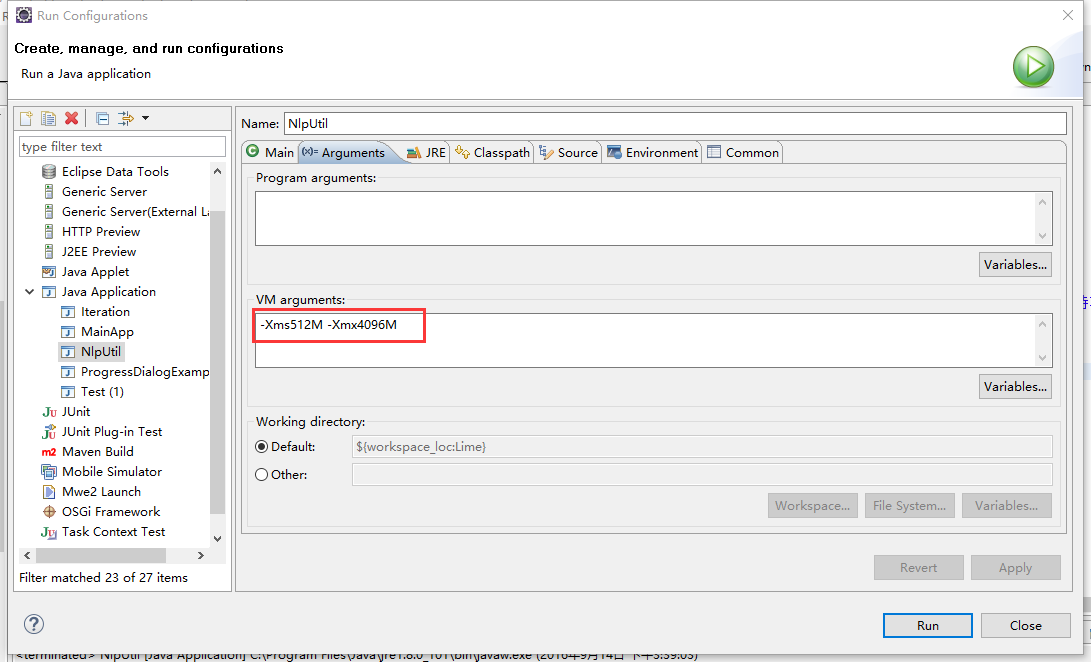
就这样,用Stanford CoreNLP处理中文也愉快地搞定了。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)