数据挖掘案例分析(1)-Apriori算法
数据挖掘案例分析(1)-Apriori算法前言:由于单单学习算法太过于枯燥和乏味,所以我们采取的学习方法是练中学,本人也是之前一点关于数据挖掘的算法知识没有学习,因此可能在理解上还不是很到位,我会尽我最大的努力来进行阐述。我们一起共勉。学习资料来源,《数据挖掘十大算法》-清华大学和《数据挖掘实用案例分析》-机械工业出版社。案例:商业零售业中的购物篮分析一、挖掘目标的提出 零
数据挖掘案例分析(1)-Apriori算法
前言:由于单单学习算法太过于枯燥和乏味,所以我们采取的学习方法是练中学,本人也是之前一点关于数据挖掘的算法知识没有学习,因此可能在理解上还不是很到位,我会尽我最大的努力来进行阐述。我们一起共勉。学习资料来源,《数据挖掘十大算法》-清华大学和《数据挖掘实用案例分析》-机械工业出版社。
案例:商业零售业中的购物篮分析
一、挖掘目标的提出
零售商的问题:
销售什么样子的商品?
采取什么样的销售策略和促销方式?
商品在货架上的摆放位置?
针对以上的问题,我们需要分析客户的购买数据,才能发现顾客的购买规律。所以基于问题的分析,我们明确了数据来源。那么我们明确了数据的来源,对这些数据该采取什么样的分析方法才能达到我们想要完成的目标。
二、分析方法与过程
根据所要实现的目标,我们先来介绍一个经典的关联规则挖掘算法:Apriori算法。
Apriori算法:关联规则挖掘问题可以划分为两个子问题:第一是找出事务数据库中所有大于等于用户指定的最小支持度的数据项集;第二个是利用频繁项集生成所需要的关联规则。根据用户设定的最小置信度进行取舍,最后得到强关联规则。识别或发现所有频繁项目集是关联规则发现算法的核心。
主要步骤:
(1) 扫描全部数据,产生候选1-项集的集合.
(2) 根据最小支持度,由候选1-项集的集合产生频繁1-项集的集合.
(3) 对K>1,重复执行步骤(4)(5)(6)
(4) 由执行链接和剪枝操作,产生候选(K+1)-项集合。
(5) 根据最小支持度,由候选(K+1)-项集的集合产生频繁(k+1)-项集的集合。
(6) 若L,则k=k+1,跳往步骤(4):否则,跳往步骤(7)。
(7) 根据最小置信度,由频繁项集产生强关联规则,结束。
其中在这个算法中,为了达到用户的一定要求,需要指定规则必须满足的支持度和置信度阈值,此两个值称为最小支持度阈值(min_sup)和最小置信度阈值(min_conf)。其中min_sup描述了关联规则的最低重要度,min_conf规定了关联规则必须满足的最低可靠性。
具体的简单应用读者可以自己自行从网上找取资源。
下面我们来总结一下Apriori算法的优缺点:
| 优点 | 缺点 |
| 1Apriori是一个迭代算法 | 1多次扫描事务数据库,需要很大的I/Ofu负载 |
| 2数据采用水平组织方式 | 2可能产生庞大的候选集 |
| 3采用Apriori优化方法 | 3在频繁项目集长度变大的情况下,运算时间显著增加。 |
| 4适合事务数据库的关联规则挖掘 | |
| 5适合稀疏数据集 |
Apriori算法应用的领域多样,其中主要包括:商业、网络安全、高效管理和移动通信等领域的应用。
介绍完Apriori算法之后,我们回归我们的案例分析,基于关联规则的购物篮分析。那么关联规则的挖掘过程如图:
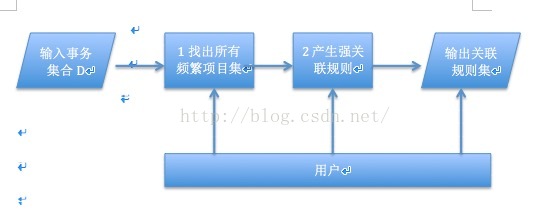
三、建模仿真
1模型输入
模型的输入包括两部分,一部分是建模专家样本数据的输入,另外一部分是建模参数的输入。
建模参数如下表:
| 序号 | 参数名称 | 参数描述 |
| 1 | 列索引 | 类别的属性选择,-1代表最后一个属性为类别属性 |
| 2 | 增量 | 支持度的变化量 |
| 3 | 最小置信度 | 设定最低的置信度值 |
| 4 | 规则条数 | 关联规则的条数 |
| 5 | 显著性水平 | 估计错误的概率 |
| 6 | 最小支持度下界 | 最小支持度的范围下限 |
| 7 | 最小支持度上界 | 最小支持度的范围上界 |
2具体的仿真过程:

经过上述的分析,我们可以发现,在彼此不同的属性之间,可以发现它们之间的关联规则,这有利于我们进行商品定价和商品的摆放。合理的制定消费策略。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)