
java集合大家族之Collection(List、Queue、Set)
集合简介如果你想保存一组对象,数组是个很好的选择,但是数组具有固定的尺寸。在一般的情况中,你在写程序时并不知道将需要多个对象,或者是否需要更复杂的方式来存储对象,因此数组尺寸固定这一限制显得过于受限制了。java类库中提供了一套相当完整的容器类来解决这个问题,其中基本的类型是List、Set、Queue和Map,这些对象类型也称为集合类。java容器类都可以自动调整自己的尺寸。因此,与数组不同,在
集合简介
如果你想保存一组对象,数组是个很好的选择,但是数组具有固定的尺寸。在一般的情况中,你在写程序时并不知道将需要多个对象,或者是否需要更复杂的方式来存储对象,因此数组尺寸固定这一限制显得过于受限制了。
java类库中提供了一套相当完整的容器类来解决这个问题,其中基本的类型是List、Set、Queue和Map,这些对象类型也称为集合类。java容器类都可以自动调整自己的尺寸。因此,与数组不同,在编程时,你可以将任意数量的对象放置在容器中,并且不需要担心容器应该设置为多大。
java容器类类库的用途是“保存对象”,并将其划分为两个不同的概念:
- Collection。存储单一元素的序列,这些元素都服从一条或多条规则进行存储。如List必须按照插入的顺序保存元素,而Set不能有重复的元素等。
- Map。存储一组成对的“键值对”对象,允许你使用键来查找值。Map中有一张映射表允许我们使用一个对象来查找另一个对象。
以下是java集合框架图:

- 实线框是实现类,比如Vector,HashSet,LinkedHashSet等。其中常用的容器用粗线表示,比如ArrayList、LinkedList等。
- 虚线框是抽象类,名字都是以Abstract开头的,比如AbstractCollection,AbstractList,AbstractMap等。
- 点线框是接口,比如Collection,Iterator,List等。
- 空心箭头的点线表示一个特定的类实现了一个接口。比如List接口继承Collection接口,AbstractMap抽象类实现了Map接口。
- 空心箭头的实线表示类的继承关系,如果HashSet继承了AbstractSet,LinkedHashMap类继承HashMap类。
- 实心箭头的点线表示某个类可以生成箭头所指向类的对象。例如,任意的Collection可以生成Iterator,而List可以生成ListIterator。
- 被Legacy标记的容器表示这些容器有更好更完善的替代品,在新程序中你不应该继续使用这些容器,这些容器有:Vector、Stack、Hashtable。
从上图中我们也可以看出整个java集合框架被划分Collection和Map两个派系(Map和Collection没有直接的联系,但是Map会生成Collection类的对象),进行细分其实只有四种容器:Map、List、Set、Queue,它们各有两到三个实现版本。
Collection
Collection接口概括了序列的概念:一种存放一组对象的方式。Collection每个槽中只能保存一个元素。下面的表格中列出了可以通过Collection执行的所有操作:
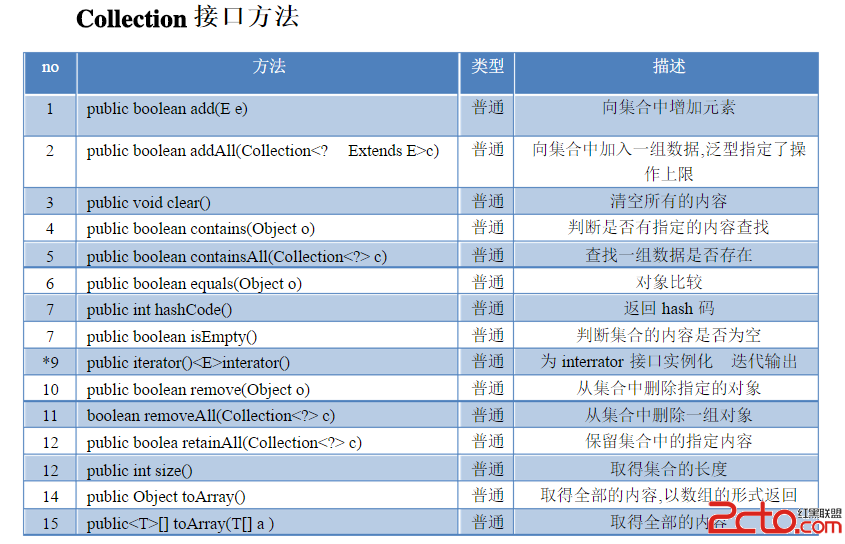
我们发现Collection中有add、remove等方法,但是并没有随机访问元素的get()方法。因为Collection是Set的父接口,Set用于存储不重复的元素,自己维护内部顺序,get方法就变得没有任何意义了。因此想获取Collection中的元素,就必须使用迭代器。
Collection以功能划分成三个继承它的子接口:List、Set、Queue
List
List接口的特点是以插入的顺序保存元素,保存的元素允许重复。List接口在Collection的基础上添加了大量的方法,使得可以在List**中间插入和移除元素**。如void add(int index, E element); 和E remove(int index);等。有常用两种类型的List-——ArrayList和LinkedList,它们都是按照被插入的顺序保存元素:
- ArrayList:底层是利用数组存储元素,它优点在于随机访问元素的速度快,缺点在于在List的中间插入和移除元素时较慢。
- LinkedList:底层是利用链表存储元素,它的优缺点正好和ArrayList相反,优点在于可以在任何位置进行高效地插入和删除操作,缺点在随机访问方面相对比较慢。但是它的特性集较ArrayList更大,LinkedList包含的操作多于ArrayList,添加了可以使其用作栈、队列或双端队列的方法。
- CopyOnWriteArrayList:一个线程安全的随机访问容器,专门用于并发编程,底层也是利用数组存储元素。
ArrayList相信已经被大家用得滚瓜烂熟了,这里就不再演示其使用方法了。但是说到LinkedList就必须先介绍下Queue容器。因为LinkedList 不仅实现了List的接口而且还实现Queue的接口,所以LinkedList也可以作为队列容器使用。
Queue
Queue(队列)接口在java SE5中出现,是一个典型的先进先出(FIFO)的容器。即从容器的一端放入对象,从另一端取出,并且对象放入容器的顺序与取出的顺序是相同的。队列在并发编程中特别重要,因为它们可以安全地将对象从一个任务传输给另一个任务。
虽然Queue接口继承Collection接口,但是Queue接口中的方法都是独立的,在创建具有Queue功能的实现时,不需要使用Collection方法。Queue对插入、移除、获取元素等操作加入了额外的方法:
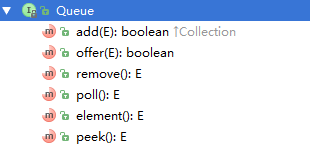
在FIFO队列中,所有的新元素都被插入队列的尾部,add和offer方法表示往队尾加入元素,remove和poll方法表示获取并移除队列第一个元素、而element和peek()表示获取队列第一个元素但并不移除。我们发现相同的操作都存在两种方法,这两种方法分别对应了两种表现形式:1.操作失败则抛出移除、2.操作失败则返回null或false,如下表所示:
| Throws exception | Returns special value | |
|---|---|---|
| Insert | add(e) | offer(e) |
| Remove | remove() | poll() |
| Examine | element() | peek() |
··
··
除了并发应用,Queue接口常用的实现类有两个LinkedList和PropertyQueue。
LinkedList
LinkedList我们在List中已经有简单的说明了下,它不仅可以作为随机存储的List容器,而且可以作为队列使用(其实ArrayList也可以作为队列只是插入和删除的效率不如LinkedList高)。既然具有随机存储和访问的特点,那么LinkedList不仅可以作为普通队列使用还可以作为双端队列使用,你可以在任何一端添加或移除元素。LinkeList并不是直接实现Queue接口,而是继承了Deque接口:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.SerializableDeque(double ended queue)接口是Java SE6才出现的,Deque接口继承Queue接口,表示双端队列的接口。该接口定义了操作队列两端元素的方法:
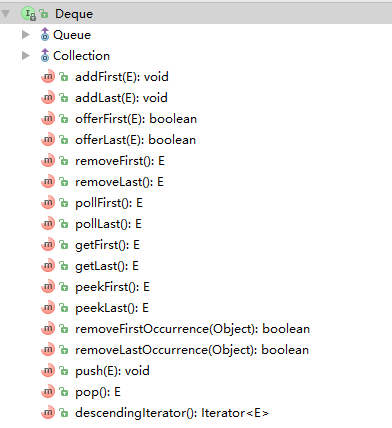
上面方法中带有First的方法表示对队列头元素进行操作,带有Last的方法则表示对队列末尾元素进行操作。与Queue接口一样,这些方法都存在两种表现形式:1.操作失败则抛出移除、2.操作失败则返回null或false,如下表所示:
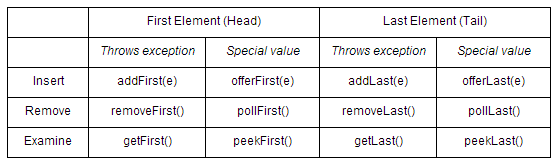
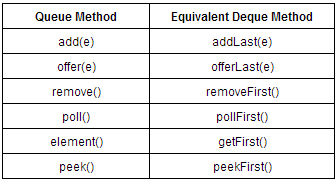
Deque接口继承Queue接口,那么当作为一个FIFO的普通队列时,这两个接口中的部分方法是等价的,如下表所示:
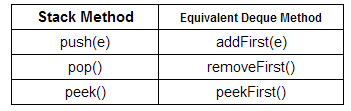
Deque也可以作为一个后进先出(LIFO)的容器,我们把LIFO的容器称”栈“,栈容器有个特点最后放进去的元素,总是最先被拿出来。java类库中有个栈类Stack就是用来实现LIFO功能的,其中Stack类的push方法用于往栈顶放入元素,pop方法用于返回并移除栈顶元素,peek方法用于获取栈顶元素但并不被移除。其实Stack类的功能用Deque中的方法就可以实现,下面显示Deque接口中可以代替Stack类中的方法:
在Stack类的文档中也提到推荐使用功能更完整的Deque作为栈类,其中实现Deque接口的ArrayDeque类就是替代Stack类的一个很好选择,而且作为栈来使用的ArrayDeque比Stack更快,这里就不介绍ArrayDeque类了。可以说Deque接口提供了丰富的方法定义满足需要实现队列、双端队列、栈特性的容器需求。
介绍Deque其实也是为了让大家更了解LinkedList,LinkedList不仅属于List也属于Queue,甚至可以作为Stack来使用,下面是LinkedList方法基本的使用:
public static void main(String[] args) {
LinkedList<String> ll = new LinkedList<>();
Collections.addAll(ll, "Hello", "World", "Java", "Welcome","Are","You","OK");
//插入的顺序和存储的顺序相同
System.out.println("LinkedList:" + ll);
System.out.println("================================");
//获取列表中的第一个元素
System.out.println("ll.getFirst() :" + ll.getFirst());
System.out.println("ll.element() :" + ll.element());
System.out.println("ll.peek() :" + ll.peek());
System.out.println("================================");
//移除并返回列表中的第一个元素
System.out.println("ll.remove() :" + ll.remove());
System.out.println("ll.removeFirst() :" + ll.removeFirst());
System.out.println("ll.poll() :" + ll.poll());
System.out.println("remove after "+ll);
//移除并返回列表中最后一个元素
System.out.println("ll.removeLast() :" + ll.removeLast());
System.out.println("remove after "+ll);
System.out.println("================================");
//往列表头部加入一个元素
ll.addFirst("new1");
System.out.println("after add :" + ll);
//往列表尾部加入一个元素
ll.add("new2");
System.out.println("after add :" + ll);
ll.offer("new3");
System.out.println("after add :" + ll);
ll.addLast("new4");
System.out.println("after add :" + ll);
}
/*Output:
LinkedList:[Hello, World, Java, Welcome, Are, You, OK]
================================
ll.getFirst() :Hello
ll.element() :Hello
ll.peek() :Hello
================================
ll.remove() :Hello
ll.removeFirst() :World
ll.poll() :Java
remove after [Welcome, Are, You, OK]
ll.removeLast() :OK
remove after [Welcome, Are, You]
================================
after add :[new1, Welcome, Are, You]
after add :[new1, Welcome, Are, You, new2]
after add :[new1, Welcome, Are, You, new2, new3]
after add :[new1, Welcome, Are, You, new2, new3, new4]
*/PriorityQueue
先进先出描述了最典型的队列规则,下一个取出的元素应该是等待时间最长的元素。这里我们介绍另一种非FIFO类型的队列:PriorityQueue(优先级队列),它是在java SE5中出现的,优先级队中下一个取出的元素是具有最高优先级的元素。在调用offer()方法来插入一个对象时,这个对象会在队列中被排序。默认的排序方式是自然顺序,但是你可以通过提供自己的Comparator来修改这个排序。PriorityQueue可以确保当你调用peek()、poll()和remove()方法时,获取的元素将是队列中优先级最高的元素。使用方法如下:
public static void main(String[] args) {
List<Integer> ll = Arrays.asList(45, 87, 1, 87, 95, -4, 18, 97, 484, 97891, -158);
PriorityQueue<Integer> pq = new PriorityQueue<>(ll);
System.out.println(pq);
printQ(pq);
pq = new PriorityQueue<>(Collections.reverseOrder());//使用反序列的Comparotr
pq.addAll(ll);
printQ(pq);
}
public static void printQ(Queue queue) {
while (queue.peek() != null) {
System.out.print(queue.remove() + " ");
}
System.out.println();
}
/*Output:
[-158, 45, -4, 87, 87, 1, 18, 97, 484, 97891, 95]
-158 -4 1 18 45 87 87 95 97 484 97891
97891 484 97 95 87 87 45 18 1 -4 -158
*/当把元素放到PriorityQueue中后,直接打印队列中的元素,发现元素在队列中不是已经排序好的,而是按照某种方式进行排列。上面说过只有调用peek()、poll()和remove()方法时,获取的元素才是队列中优先级最高的。我们也可以看到队列中的元素是允许重复的。还可以构建排序器定义自己的排序规则,就如上面使用系统提供的反向排序器Collections.reverseOrder()。还有必须注意一点:优先级队列的元素不能为null。
public static void main(String[] args) {
List<String> ll = Arrays.asList("vv", "vedre", "de", "abb", "ber", null, "vv");
LinkedList<String> li = new LinkedList<>(ll);
System.out.println(li);
PriorityQueue<String> pq = new PriorityQueue<>(ll);
System.out.println(pq);
}
/*Output:
[vv, vedre, de, abb, ber, null, vv]
Exception in thread "main" java.lang.NullPointerException
at java.util.PriorityQueue.siftDownComparable(PriorityQueue.java:701)
at java.util.PriorityQueue.siftDown(PriorityQueue.java:689)
at java.util.PriorityQueue.heapify(PriorityQueue.java:736)
at java.util.PriorityQueue.initFromCollection(PriorityQueue.java:275)
at java.util.PriorityQueue.<init>(PriorityQueue.java:202)
at Xx.main(Xx.java:12)
*/因为优先级队列需要使用排序器进行排序,遇到空元素无法比较则直接抛异常。
Set:
Set接口的特点是用于保存不重复的元素。如果你试图将相同对象的多个实例添加到Set中,那么它就会阻止这种重复现象。Set接口和Collection接口完全一样,没有任何额外的功能,不像前面的List。实际上Set就是Collection,只是行为不同。常用的有三种类型的Set:HashSet、LinkedHashSet、TreeSet:
- HashSet:因为Set用于保存不重复的元素,那么快速查找成为了Set中的重要操作。而HashSet专门对快速查找进行了优化,它使用了散列,可以对元素进行快速的查找。HashSet元素存储的顺序是没有任何规律的。
- LinkedHashSet:它可以按照被添加的顺序保存元素,同时为了查询速度的原因也使用了散列。使用了链表来维护元素的插入顺序。
- TreeSet:如果你想对存储的元素进行排序,你可以使用TreeSet,它按照比较的结果的升序保存对象。TreeSet将元素存储在红-黑树数据结构中。
下面是使用存放Integer对象的Set的示例:
public static void main(String[] args) {
List<Integer> list = Arrays.asList(74, 84, 65, 1, 87, 98, 10, 4, 1, 68, 10, 77,null,null);
Set<Integer> set = new HashSet<>(list);
System.out.println(set);
set = new LinkedHashSet<>(list);
System.out.println(set);
set = new TreeSet<>(list.subList(0,list.size()-2));
System.out.println(set);
}打印如下:
[null, 65, 1, 98, 4, 68, 74, 10, 77, 84, 87]
[74, 84, 65, 1, 87, 98, 10, 4, 68, 77, null]
[1, 4, 10, 65, 68, 74, 77, 84, 87, 98]
HashSet、LinkedHashSet都可以存放nul元素,而TreeSet使用了比较器的原因,无法存放null元素。HashSet不维护元素的插入次序,LinkedHashSet则维护了元素的插入次序。TreeSet默认使用自然顺序进行排序,当然我们也可以定义自己的比较器。
set中元素的存储规则
java有很多预定义的类型如String,Double,Integer等,这些类型都被设计为可以在容器内部使用。当你创建自己的类型时,要意识到Set需要一种方式来维护存储的序列,而存储序列如何维护,则是在Set的不同实现之间会有所变化。因此,不同的Set实现不仅具有不同的行为,而且它们对于可以在特定的Set中放置的类型也有不同的要求:
java有很多预定义的类型如String,Double,Integer等,这些类型都被设计为可以在容器内部使用。当你创建自己的类型时,要意识到Set需要一种方式来维护存储的序列,而存储序列如何维护,则是在Set的不同实现之间会有所变化。因此,不同的Set实现不仅具有不同的行为,而且它们对于可以在特定的Set中放置的类型也有不同的要求:
- Set接口:存入Set的每个元素都必须是唯一的,Set不保存重复元素。因此加入Set的元素必须定义equals()方法以确保对象的唯一性。Set接口不保证维护元素的次序。
- HashSet 、 LinkedHashSet:都是具有快速查找功能的Set,底层都是利用哈希表进行查找,因此被存入的元素必须定义hasCode()方法。
- TreeSet:底层是红黑树结构,在插入的时候根据元素的比较器来进行插入,所以元素必须实现Comparable接口,底层不是利用哈希表来查找的,所以不必定义hasCode()方法。
HashSet和LinkedHashSet都属于散列存储,所以如果我们覆盖equals()方法时,务必同时覆盖hashCode()方法。为什么呢? 我们先简单说说HashSet是如何利用hashCode()和equals()来存储值的:
当集合要添加新的对象时,会先调用这个对象的hashCode方法,得到对应的hashcode值,实际上在HashSet的具体实现中会用一个table保存已经存进去的对象的hashcode值,如果table中没有该hashcode值,它就可以直接存进去,不用再进行任何比较了;如果存在该hashcode值, 就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址,所以这里存在一个冲突解决的问题,这样一来实际调用equals方法的次数就大大降低了。
从上面我们可以看出HashCode方法主要是是用于查找使用,equals是用于比较两个对象的是否相等。而当Set中保证元素不重复的equals方法被覆盖后,如果不覆盖hashcode方法,则会导致存入相同的元素,就如下:
class People{
private String name;
private int age;
public People(String name,int age) {
this.name = name;
this.age = age;
}
public void setAge(int age){
this.age = age;
}
@Override
public boolean equals(Object obj) {
return this.name.equals(((People)obj).name) && this.age== ((People)obj).age;
}
}
public class HashTest {
public static void main(String[] args) {
People p1 = new People("Jack", 12);
People p2 = new People("Jack", 12);
HashSet<People> hashMap = new HashSet<>();
hashMap.add(p1);
hashMap.add(p2);
System.out.println(hashMap);
}
}输出: [People@7d4991ad, People@28d93b30]
上面我们重新定义了People类型的equals的判断标准,只要姓名和年龄一致,则认为两个对象是一样的。但是由于我们没覆盖hashCode方法,导致存入HashSet时会先判断hashCode是否一致,如果不一致就进行存储。因为我们默认调用的是Object的hashCode方法,所以这两个对象的哈希值不同,则被HashSet的存入了,就不会再去判断equals方法了。因此当我们需要存储在Hash类型的容器中,如果有对元素重写equals方法,请务必重写hashCode方法。在上面的例子中,我们对People类添加hashCode方法(复写):
@Override
public int hashCode() {
return age+name.hashCode();
}此时打印的结果只有一个元素:[People@231c0b]
TreeSet底层则是利用红黑树进行存储,所以不会使用hashCode方法 ,但是存入该容器的元素必须实现Comparable接口,否则会抛异常:
class People implements Comparable<People> {
private int age;
public People(int age) {
this.age = age;
}
@Override
public int compareTo(People o) {
return (o.age < age ? -1 : (o.age == age ? 0 : 1));
}
@Override
public String toString() {
return age+"";
}
}
public class TreeSetTest {
public static void main(String[] args) {
List<People> list = Arrays.asList(
new People(78), new People(33),
new People(43), new People(20),
new People(33), new People(47));
TreeSet<People> treeSet = new TreeSet<>(list);
System.out.println(treeSet);
}
}输出的结果为[78, 47, 43, 33, 20]。
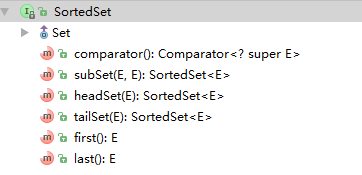
TreeSet并没有直接实现Set接口,而是作为SortedSet接口的一个实现类,SortedSet接口定义了容器中元素处于排序状态。SortedSet接口提供了附加功能,帮助我们便于处理排序型Set:
public static void main(String[] args) {
TreeSet<String> tree = new TreeSet<>();
Collections.addAll(tree, "one", "two", "three", "four", "five", "six", "seven", "eight");
System.out.println(tree);//[eight, five, four, one, seven, six, three, two]
//返回容器中第一个元素
System.out.println(tree.first());//eight
//返回容器中最后一个元素
System.out.println(tree.last());//two
//生成范围从fromElement(包含)到toElement(不包含)的TreeSet子集
System.out.println( tree.subSet("one","three"));//[one, seven, six]
//生成toElement(不包括)到容器头部的TreeSet子集
System.out.println(tree.headSet("four"));//[eight, five]
//生成fromElement(包括)到容器尾部的TreeSet子集
System.out.println(tree.tailSet("four"));//[four, one, seven, six, three, two]
}参考
《Thinking in Java》

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)