
MySQL---数据库从入门走向大神系列(六)-事务处理与事务隔离(锁机制)
MySQL 事务处理简单介绍事务处理:MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!一个事务是一个连续的一组数据库操作,就好像它是一个单一的工作单元进行。换言之,永远不会是完整的事务,除非该组内的每个单独的操作是成功的。如果在事务的任
MySQL 事务处理
简单介绍事务处理:
MySQL 事务主要用于处理操作量大,复杂度高的数据。
比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
一个事务是一个连续的一组数据库操作,就好像它是一个单一的工作单元进行。换言之,永远不会是完整的事务,除非该组内的每个单独的操作是成功的。如果在事务的任何操作失败,则整个事务将失败。
事务处理可以用来维护数据库的完整性,保证成批的SQL语句要么全部执行,要么全部不执行
事务用来管理多条insert,update,delete语句
一般来说,事务是必须满足4个条件(ACID):
Atomicity(原子性)、Consistency(稳定性)、Isolation(隔离性)、Durability(可靠性)
1、事务的原子性:一组事务,要么成功;要么撤回。
2、稳定性 : 有非法数据(外键约束之类),事务撤回。
3、隔离性:事务独立运行。一个事务处理后的结果,影响了其他事务,那么其他事务会撤回。事务的100%隔离,需要牺牲速度。
4、可靠性:软、硬件崩溃后,InnoDB数据表驱动会利用日志文件重构修改。可靠性和高速度不可兼得, innodb_flush_log_at_trx_commit选项 决定什么时候把事务保存到日志里。
开始一个事务
start transaction在MySQL中,事务开始使用COMMIT或ROLLBACK语句开始工作和结束。开始和结束语句的SQL命令之间形成了大量的事务。
COMMIT & ROLLBACK:
这两个关键字提交和回滚(撤销事务)主要用于MySQL的事务。
当一个成功的事务完成后,发出COMMIT命令应使所有参与表的更改才会生效。
如果发生故障时,应发出一个ROLLBACK命令返回的事务中引用的每一个表到以前的状态。
可以控制的事务行为称为AUTOCOMMIT设置会话变量。如果AUTOCOMMIT设置为1(默认值),然后每一个SQL语句(在事务与否)被认为是一个完整的事务,并承诺在默认情况下,当它完成。 AUTOCOMMIT设置为0时,发出SET AUTOCOMMIT =0命令,在随后的一系列语句的作用就像一个事务,直到一个明确的COMMIT语句时,没有活动的提交。
Java中setAutoCommit(false)对应mysql中的“START TRANSACTION;”的功能
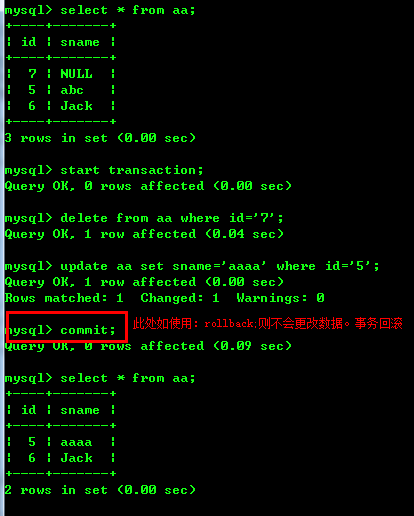
SQL代码演示说明:
start transaction;
delete from aa where id='7';
update aa set sname='aaaa' where id='5';
rollback;/*事务回滚-执行失败*/
/*commit;提交事务-执行成功*/说明:从”start transaction”开始 到 “bollback; 或 commit; ”,这中间的那么语句是一个整体,如果执行 “bollback”,那么这些动作都会回滚(撤消)。如果执行“commit”,就全部执行成功。
Java代码演示:
@Test
public void transactionDemo() throws ClassNotFoundException, SQLException{
//1、加载连接器(驱动) Driver
Class.forName("com.mysql.jdbc.Driver");
//2、建立连接
String url = "jdbc:mysql://127.0.0.1:3306/hncu?useUnicode=true&characterEncoding=utf-8";
Connection con = DriverManager.getConnection(url, "root", "1234");
//3、获取语句对象
Statement st = con.createStatement();
//4、下面为Java实现事务处理
try {
con.setAutoCommit(false);//从设置false开始,以下都是一个事务
String sql = "insert into aa values(1,'张三');";
st.execute(sql);//增
sql = "delete from aa where id = 5";
st.execute(sql);//删
sql = "update aa set sname='rose111' where id=6";
st.execute(sql);
con.commit();//提交
} catch (Exception e) {
con.rollback();//如果出现异常,我们就让事务回滚
} finally{
con.setAutoCommit(true);//再设置回去
con.close();
}
}事务隔离级别(加锁):
SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
查询事务隔离级别:
select @@tx_isolation;Read Uncommitted(读取未提交内容)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,被称之为脏读(Dirty Read)。
测试流程:
1、A设置read-uncommitted, start transaction
设置事务隔离级别(read-uncommitted):
set session transaction isolation level read uncommitted;
2、B执行start transaction,再修改一条记录,
3、A查询记录,得到了以为正确的记录
4、B回滚。
问题:A读到了B没有提交的记录,也就是脏读。 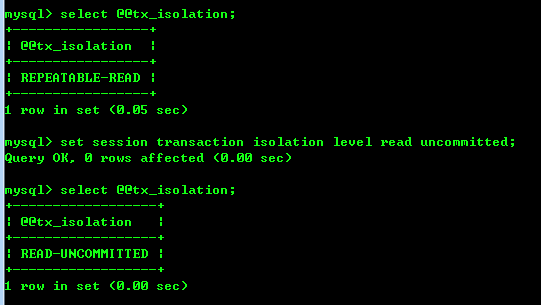
Read Committed(读取提交内容)
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。
这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
不可重复读(nonrepeatable read):
一个从开始直到提交之前所做的任何修改对其它事务都是不可见的。两次同样的查询可能会得到不一样的结果。
测试流程:
1、A设置read-committed, start transaction
设置事务隔离级别(read-committed):
set session transaction isolation level read committed;
2、B执行start transaction,修改一条记录,查询记录,记录已经修改成功
3、A查询记录,结果还是老的记录
4、B提交事务
5、A再次查询记录,结果是新的记录。
问题:两次查询结果不一致,也就是不可重复读问题。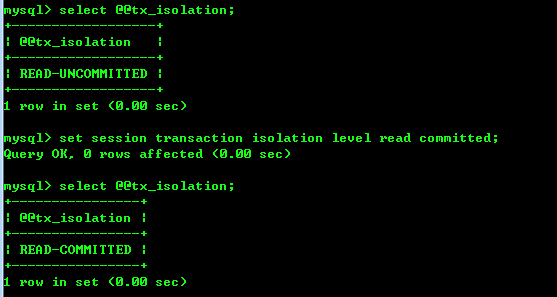
Repeatable Read(可重读)-MySQL的默认事务隔离级别
它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。
保证了在同一事务中多次读取结果是一致的。但会引起另外一个幻读问题,当某个事务在读取某个范围记录时,另外一个事务在该范围插入和新记录,当之前事务再次读取该范围记录时会产生幻行。
测试流程:
1、A设置repeatable-read, start transaction,查询记录,结果是老的记录
设置事务隔离级别(repeatable-read,MySQL默认):
set session transaction isolation level repeatable read;
2、B执行start transaction,修改一条记录,查询记录,记录已经修改成功
3、A查询记录,结果还是老的记录
4、B提交事务
5、A再次查询记录,结果还是老的记录。
问题:可以重复读,A在事务过程中,即使B修改了数据,并且commit,A读取的还是老的数据。即可重复读。
注意:这里可能会存在一个新的问题,A在事务过程中,B增加一条记录,并提交,导致A的两次读取不一致,会多一条记录,也就是幻影读。
InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。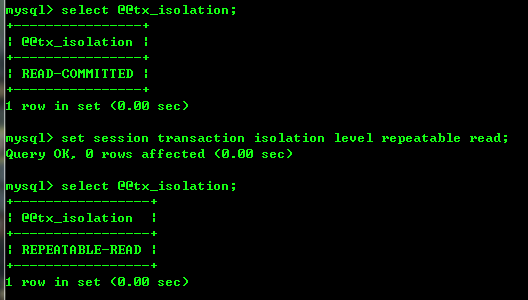
Serializable(可串行化)
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
测试流程:
1、A设置serializable, start transaction,查询记录,结果是老的记录
设置事务隔离级别(serializable,最高级别):
set session transaction isolation level serializable;
2、B执行start transaction,修改一条记录,B卡在这里,要等待A完成才行。
3、A查询记录,结果还是老的记录,A提交。
4、B的修改操作才进行下去。
注意:B在等待过程中,会出现lock超时。
小知识点:
共享锁:如果事务T对数据A加上共享锁后,则其他事务只能对A再加共享锁,不能加排他锁。获准共享锁的事务只能读数据,不能修改数据。
排他锁:如果事务T对数据A加上排他锁后,则其他事务不能再对A加任任何类型的封锁。获准排他锁的事务既能读数据,又能修改数据。查看当前隔离级别:
select @@tx_isolation;设置隔离级别语法:
set [session | global] transaction isolation level {read uncommitted | read committed | repeatable read | serializable}这四种隔离级别采取不同的锁类型来实现,若读取的是同一个数据的话,就容易发生问题。例如:
脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack(回滚)了操作,则后一个事务所读取的数据就会是不正确的。
不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。

快速构建 Web 应用程序
更多推荐
 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)