
Python对中文字符的处理(utf-8/ gbk/ unicode)
现在在做分词的时候会处理大量有关中文字符的处理,经常输出乱码,老大让我暂时不考虑字符编码,但是为了看着爽不得不研究一下。分词系统:NLPIR因为不同的编译环境默认的汉字编码可能不一样,我的环境是OSX10.11 + Pycharm + python2.7文件第一行永远默认# coding: utf-8数据集我用的是“tc-corpus-train”这个是数据,百度一
现在在做分词的时候会处理大量有关中文字符的处理,经常输出乱码,老大让我暂时不考虑字符编码,但是为了看着爽不得不研究一下。
分词系统:NLPIR
因为不同的编译环境默认的汉字编码可能不一样,我的环境是OSX10.11 + Pycharm + python2.7
文件第一行永远默认
# coding: utf-8
数据集我用的是“tc-corpus-train”这个是数据,百度一下就能搜到,里面有20种文档,每个文档都是关于这个方面的小新闻,挺好用的。
#--------------------------------------------我是分割线--------------------------------------------#
环境说完了下面从我遇到的问题逐渐说说是怎么解决的:
1.什么是utf-8/ gbk/ unicode编码
我就通俗易懂的讲解一下吧,讲的复杂了肯定是没人看的
utf-8是Unix下的一种通用编码,可以对汉字编码,应该是Unix环境下能打开看到汉字的唯一编码(gbk试过,乱码,不知有没有人反驳我)
gbk是win环境下的一种汉字编码,其中GB2312编码也算是gbk编码,这种编码在Unix环境中打开是乱码,大概是这个样子:
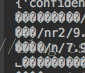
可以看到,英文正常显示,但是汉字呢就gg了,一般看到这种跟个蛋一样的字符就是gbk汉字(只在mac中试过,别的Unix不知道是不是个蛋)
unicode是一种二进制编码,所有的utf-8和gbk编码都得通过unicode编码进行转译,说的直白一点,utf-8和gbk编码之间不能之间转换,要在unicode之间过个场才能转换。下面我图解一下,方便理解:
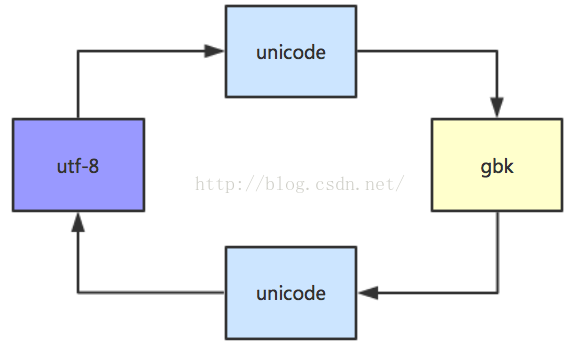
而在mac环境下pycharm只能显示来自unicode的汉字,举个例子:
# coding:utf-8
s = '我是一串汉字'
print s首先,s是一串utf-8编码的汉字,在print的时候,先把utf-8转化成unicode再输出成正产显示的汉字。
如果打开一个文档,怎么看里面是什么编码的字呢?乱码是不是蛋已经无法满足一个有逼格程序员的要求了,请看下面:
2.如何查看文档、字符串编码格式
不废话,下面几行代码搞定:
# coding:utf-8
import chardet
s = '哈哈哈我就是一段测试的汉字呀'
print chardet.detect(s)输出:{'confidence': 0.99, 'encoding': 'utf-8'}
这个办法只能输出这段字符可能的编码格式,我们看到0.99的可能是utf-8,其实也就是utf-8编码了,只要字符串够长,后面的置信度都是0.99
3.各种编码之间如何转换
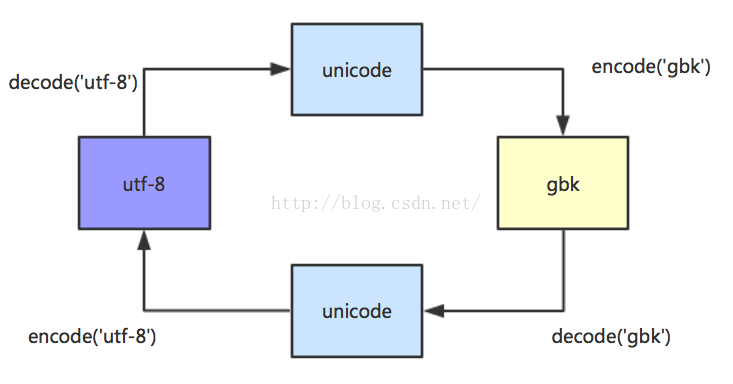
python中有两个很好用的函数 decode() 和 encode()
decode(‘utf-8’) 是从utf-8编码转换成unicode编码,当然括号里也可以写'gbk'
encode('gbk') 是将unicode编码编译成gbk编码,当然括号里也可以写'utf-8'
假如我知道一串编码是用utf-8编写的,怎么转成gbk呢
s.decode('utf-8').encode('gbk')图解一下:
4.我为什么要把编码转来转去
在使用NLPIR分词的时候,对输入文档的编码格式是有严格要求的,在函数初始化的时候可以设置输入源文档的编码格式。
但是源文档的编码可能一会儿是utf-8一会儿是gbk,这就要求统一一下格式,不能格式一乱就报错了,
具体操作我后面会写一篇python调用NLPIR的说明

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 40
40 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)