模式识别(Pattern Recognition)学习笔记(二十三)-- SVM的两大思想:大间隔与核函数
0.引言上节讲到广义线性判别函数,它是从任意阶非线性判别函数到线性判别函数的一种有效变换,但是这种变换是以牺牲特征空间维数为代价的,如果能很好地处理这种维数灾难,那么上述变换也是极好的,有没有可能在特征空间上作变换呢,从而将原空间中的非线性问题转化为新空间中的线性问题,答案是肯定的,今天我们来学习如何构造这种非线性的支持向量机,因为它就是采用引入特征变化这一思路来实现的,但是值得注意的是,支持
0.引言
上节讲到广义线性判别函数,它是从任意阶非线性判别函数到线性判别函数的一种有效变换,但是这种变换是以牺牲特征空间维数为代价的,如果能很好地处理这种维数灾难,那么上述变换也是极好的,有没有可能在特征空间上作变换呢,从而将原空间中的非线性问题转化为新空间中的线性问题,答案是肯定的,今天我们来学习如何构造这种非线性的支持向量机,因为它就是采用引入特征变换这一思路来实现的,但是值得注意的是,支持向量机并非直接计算这种复杂的非线性变换,而是采用了一种独特而又巧妙的迂回策略来间接实现的。
1.回顾线性SVM的求解过程
在线性的支持向量机中,其要求解的决策函数为:
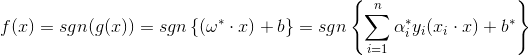
如果对上述原特征x进行某种非线性的特征变换,并将变换后的新特征记为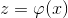
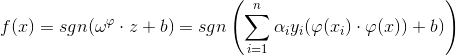
同样是一个带有约束的优化问题(对分类间隔求最大,关于“大间隔”不明白的可以回到线性的SVM中查看),对拉格朗日泛函求解,得到的等价解为(具体的求解方法同线性一样,不懂得请回头查看):
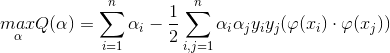
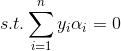
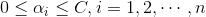
支持向量的定义变为:
(3)
如果你已经对前面线性SVM的求解很熟悉了,就会发现,上面三个公式跟在线性里是很相似的,不同的只是特征发生了变换,但是再仔细看,你又会发现,无论变换是以何种形式进行,它对支持向量或边界向量的影响只是把两个样本在原特征空间中的内积变成了在新特征空间中的内积
,但是后面的这个内积仍然是原特征的函数,将其记为:
(4)
上式被称为所谓的核函数;于是可以将公式(1)和公式(3)中的都替换成
;
与线性的SVM对比发现,两者之前的差别是:原来的内积运算变成了现在的核函数
;
因此在这一变化之后,新的特征不论维数有多高,我们都仍然可以在原特征空间利用核函数
进行求解,从而避免了高维的计算量。
2.Mercer条件
从上面的分析中可能有人大开脑洞了,他可能会这样想:我想要求解非线性的SVM,其实我们无需考虑特征变换是什么样的啊,即无需设计这样一个非线性的特征变换,而只需要知道具体的核函数就够了呀,那么我们能不能这样做呢?当然可以辣,只要核函数满足Mercer条件就行。
关于Mercer条件,是这样的:
对于任意的对称函数,它是某个特征空间中的内积运算的充要条件是,对于任意的
且
,则有:
(5)
只要满足这一条件的核函数,就可以用它来构造非线性的SVM;
另外,还有人进一步证明,上述条件可以放松至满足如下条件的正定核(Positive Definite Kernels):是定义在X空间的对称函数,且对X中任意的训练样本xi和任意的实系数ai都有:
(6)
对于满足正定条件的核函数,必然存在一个从X空间到内积空间K的变换,使得
,这里变换后的空间被称作可再生核希尔伯特空间(Reproducing Kernel Hilbert Space),简称RKHS。
3.常用核函数形式
3.1多项式核
形式为:
采用这种核的SVM可以实现q阶的多项式判别函数;
3.2RBF核
形式为:
采用这种核可实现与RBF网络相同的分类决策,但是注意两者仍然有很大区别;RBF网络需要利用先验知识来决定径向基的个数、每个径向基的中心、径向基函数的宽度等,而只有连接的权系数是需要BP学习得来的;而采用了RBF核的SVM,每一个支持向量构成一个径向基函数的中心,其径向基的个数、宽度等都需要学习得到。
3.3Sigmoid核
形式为:
采用这种核,当v和c为一定取值时,可实现一个三层的MLP,且隐层节点数就是支持向量的个数,因此它其实就是实现了隐层节点数的自动选取;
4.核函数及其参数的选择
选取不同的核函数时,SVM就可以实现不同形式的非线性分类器,如果核函数是线性的内积函数,就是线性的SVM。
关于核函数的选取,也需要针对具体问题来具体选择,很难有一个通用性的准则。
关于参数的选取,针对上述三种核,参数主要有阶数q,宽度,v和c。它们的选择依然是针对具体问题具体选择,更多的是采用启发式或累试的方法来选择,通常来说,核函数参数的选择并不是十分困难,人们往往人工尝试几种选择便能够找到比较合适的参数。一条前辈们留下的基本经验是:首先尝试简单的选择,比如首先尝试线性核,结果不满意再考虑用非线性核;对于用RBF核来说,应该首先选取宽度比较大的核,因为宽度越大越接近线性核,然后再尝试减小宽度,增加非线性程度。
5.核函数与相似性度量
SVM的基本思想可以概括为,首先通过非线性变换将输入空间变换到一个高维空间,然后在这个新的特征空间中求解最优分类超平面或最大间隔分类面,而其中这种非线性变换又是通过合适的内积核来实现。SVM的决策分类函数在形式上跟NN比较像,输出是若干中间层节点输出的线性组合,而中间层的每一个节点的输出是输入样本与一个支持向量的内积,因此早期也被人们叫做支持向量网络,如图:
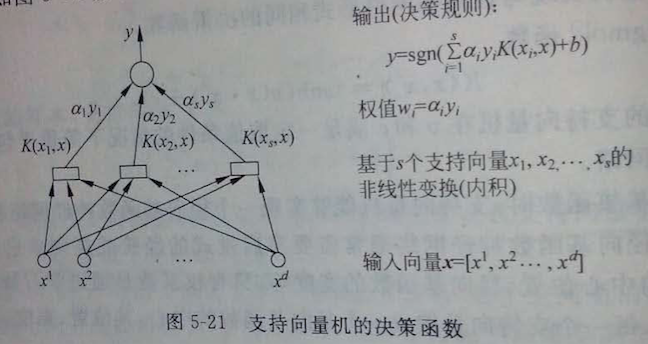
上图中的决策过程其实也可以看作是一种相似性比较,为什么呢,可以来看一下它的决策过程:
首先,输入样本与一系列模板样本进行相似性比较,其中模板样本就是训练过程中确定的支持向量,而采用的相似性度量就是我们的核函数;
其次,样本与各支持向量比较后的得分进行加权求和,权值就是训练时得到的各支持向量的系数与类别标签y的乘积;
最后,根据需要对加权求和值得大小做出决策;
另外,不同的核函数就代表着不同的相似性度量,线性的SVM采用的是欧式空间中的内积作为相似性度量,因此在一些实际问题中(如进行DNA序列的分类)还可以根据领域内的专业知识来定义自己的核函数,这种与专业知识相结合的方法往往能取得更好的效果。
另外,值得注意的是,在选用一个核函数时或者自己定义新的核函数时,一定要检验该核函数是否满足Mercer条件,若不满足,就会导致SVM的目标函数失去了凸函数的性质,从而造成目标函数的解不唯一。
6.维数与推广能力
尽管我们知道了SVM用核函数作为内积函数,避开了高维计算,但是即使如此,核函数的本质作用仍然是把样本的特征映射到高维,比如采用RBF核,映射后的空间就会是无穷多维,这样一来,当样本有限的情况下,在无穷多维的高维空间构造非线性分类器,推广能力可能会让你抓狂;但是捏,根据SVM自身的性质特点,我们知道它其实是通过最大化分类间隔来控制学习机器(函数集)的VC维(机器的复杂度),使得学习机器即使在高维空间,其VC维也会比特征空间的维数要低很多,从而保证了较好的推广能力,因为在训练误差差不多的情况下,VC维越低,期望风险与经验风险的差距就会越小,学习机器的推广能力也就越好。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)