谈谈我对服务熔断、服务降级的理解
伴随着微服务架构被宣传得如火如荼,一些概念也被推到了我们面前(管你接受不接受),其实大多数概念以前就有,但很少被提的这么频繁(现在好像不提及都不好意思交流了)。想起有人总结的一句话,微服务架构的特点就是:“一解释就懂,一问就不知,一讨论就吵架”。其实对老外的总结能力一直特别崇拜,Kevin Kelly、Martin Fowler、Werner Vogels……,都是著名的“
·
伴随着微服务架构被宣传得如火如荼,一些概念也被推到了我们面前(管你接受不接受),其实大多数概念以前就有,但很少被提的这么频繁(现在好像不提及都不好意思交流了)。想起有人总结的一句话,微服务架构的特点就是:“一解释就懂,一问就不知,一讨论就吵架”。
其实对老外的总结能力一直特别崇拜,Kevin Kelly、Martin Fowler、Werner Vogels……,都是著名的“演讲家”。正好这段时间看了些微服务、容器的相关资料,也在我们新一代产品中进行了部分实践,回过头来,再来谈谈对一些概念的理解。
今天先来说说“服务熔断”和“服务降级”。为什么要说这个呢,因为我很长时间里都把这两个概念同质化了,不知道这两个词大家怎么理解,一个意思or有所不同?现在的我是这么来看的:
- 在股票市场,熔断这个词大家都不陌生,是指当股指波幅达到某个点后,交易所为控制风险采取的暂停交易措施。相应的,服务熔断一般是指软件系统中,由于某些原因使得服务出现了过载现象,为防止造成整个系统故障,从而采用的一种保护措施,所以很多地方把熔断亦称为过载保护。
- 大家都见过女生旅行吧,大号的旅行箱是必备物,平常走走近处绰绰有余,但一旦出个远门,再大的箱子都白搭了,怎么办呢?常见的情景就是把物品拿出来分分堆,比了又比,最后一些非必需品的就忍痛放下了,等到下次箱子够用了,再带上用一用。而服务降级,就是这么回事,整体资源快不够了,忍痛将某些服务先关掉,待渡过难关,再开启回来。
所以从上述分析来看,两者其实从有些角度看是有一定的类似性的:
- 目的很一致,都是从可用性可靠性着想,为防止系统的整体缓慢甚至崩溃,采用的技术手段;
- 最终表现类似,对于两者来说,最终让用户体验到的是某些功能暂时不可达或不可用;
- 粒度一般都是服务级别,当然,业界也有不少更细粒度的做法,比如做到数据持久层(允许查询,不允许增删改);
- 自治性要求很高,熔断模式一般都是服务基于策略的自动触发,降级虽说可人工干预,但在微服务架构下,完全靠人显然不可能,开关预置、配置中心都是必要手段;
而两者的区别也是明显的:
- 触发原因不太一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
- 管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务开始)
- 实现方式不太一样,这个区别后面会单独来说;
当然这只是我个人对两者的理解,外面把两者归为完全一致的也不在少数,或者把熔断机制理解为应对降级目标的一种实现也说的过去,可能“一讨论就吵架”也正是这个原因吧! 概念算是说完了,避免空谈,我再总结下对常用的实现方法的理解。对于这两个概念,号称支持的框架可不少,Hystrix当属其中的佼佼者。 先说说最裸的熔断器的设计思路,下面这张图大家应该不陌生(我只是参考着又画了画),简明扼要的给出了好的熔断器实现的三个状态机:
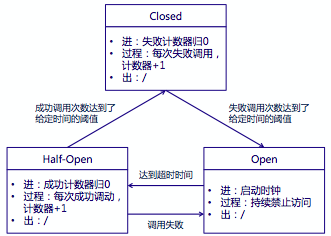
- Closed:熔断器关闭状态,调用失败次数积累,到了阈值(或一定比例)则启动熔断机制;
- Open:熔断器打开状态,此时对下游的调用都内部直接返回错误,不走网络,但设计了一个时钟选项,默认的时钟达到了一定时间(这个时间一般设置成平均故障处理时间,也就是MTTR),到了这个时间,进入半熔断状态;
- Half-Open:半熔断状态,允许定量的服务请求,如果调用都成功(或一定比例)则认为恢复了,关闭熔断器,否则认为还没好,又回到熔断器打开状态;
那Hystrix,作为Netflix开源框架中的最受喜爱组件之一,是怎么处理依赖隔离,实现熔断机制的呢,他的处理远比我上面说个实现机制复杂的多,一起来看看核心代码吧,我只保留了代码片段的关键部分:
public abstract class HystrixCommand<R> extends AbstractCommand<R> implements HystrixExecutable<R>, HystrixInvokableInfo<R>, HystrixObservable<R> {
protected abstract R run() throws Exception;
protected R getFallback() {
throw new UnsupportedOperationException("No fallback available.");
}
@Override
final protected Observable<R> getExecutionObservable() {
return Observable.defer(new Func0<Observable<R>>() {
@Override
public Observable<R> call() {
try {
return Observable.just(run());
} catch (Throwable ex) {
return Observable.error(ex);
}
}
});
}
@Override
final protected Observable<R> getFallbackObservable() {
return Observable.defer(new Func0<Observable<R>>() {
@Override
public Observable<R> call() {
try {
return Observable.just(getFallback());
} catch (Throwable ex) {
return Observable.error(ex);
}
}
});
}
public R execute() {
try {
return queue().get();
} catch (Exception e) {
throw decomposeException(e);
}
}HystrixCommand是重重之重,在Hystrix的整个机制中,涉及到依赖边界的地方,都是通过这个Command模式进行调用的,显然,这个Command负责了核心的服务熔断和降级的处理,子类要实现的方法主要有两个:
- run方法:实现依赖的逻辑,或者说是实现微服务之间的调用;
- getFallBack方法:实现服务降级处理逻辑,只做熔断处理的则可不实现;
使用时,可参考如下方式:
public class TestCommand extends HystrixCommand<String> {
protected TestCommand(HystrixCommandGroupKey group) {
super(group);
}
@Override
protected String run() throws Exception {
//这里需要做实际调用逻辑
return "Hello";
}
public static void main(String[] args) throws InterruptedException, ExecutionException, TimeoutException {
TestCommand command = new TestCommand(HystrixCommandGroupKey.Factory.asKey("TestGroup"));
//1.这个是同步调用
command.execute();
//2.这个是异步调用
command.queue().get(500, TimeUnit.MILLISECONDS);
//3.异步回调
command.observe().subscribe(new Action1<String>() {
public void call(String arg0) {
}
});
}
}细心的同学肯定发现Command机制里大量使用了Observable相关的API,这个是什么呢?原来其隶属于RxJava,这个框架就不多介绍了 --- 响应式开发,也是Netflix的作品之一,具体大家可参考这系列博客,我觉得作者写的很通俗:http://blog.csdn.net/lzyzsd/article/details/41833541/
接着呢,大家一定会问,那之前说的熔断阈值设置等,都在哪块做的呢?再来看看另一块核心代码:
public abstract class HystrixPropertiesStrategy {
public HystrixCommandProperties getCommandProperties(HystrixCommandKey commandKey, HystrixCommandProperties.Setter builder) {
return new HystrixPropertiesCommandDefault(commandKey, builder);
}
......
}这个类作为策略类,返回相关的属性配置,大家可重新实现。而在具体的策略中,主要包括以下几种策略属性配置:
- circuitBreakerEnabled:是否允许熔断,默认允许;
- circuitBreakerRequestVolumeThreshold:熔断器是否开启的阀值,也就是说单位时间超过了阀值请求数,熔断器才开;
- circuitBreakerSleepWindowInMilliseconds:熔断器默认工作时间,超过此时间会进入半开状态,即允许流量做尝试;
- circuitBreakerErrorThresholdPercentage:错误比例触发熔断;
- ......
属性很多,这里就不一一说明了,大家可参考HystrixCommandProperties类里的详细定义。还有一点要着重说明的,在熔断器的设计里,隔离采用了线程的方式(据说还有信号的方式,这两个区别我还没搞太明白),处理依赖并发和阻塞扩展,示意图如下:
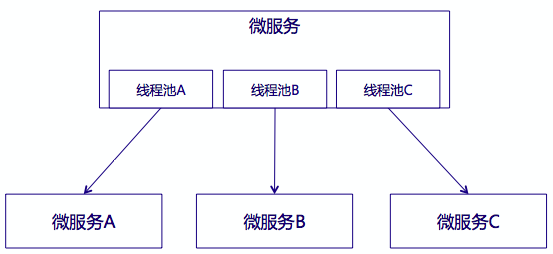
如上图,好处也很明显,对于每个依赖都有独立可控的线程池,当然高并发时,CPU切换较多,有一定的影响。
啰嗦了一堆,最后总结一下,我认为服务熔断和服务降级两者是有区别的,同时通过对Hystrix的简单学习,了解了其实现机制,会逐步引入到我们的产品研发中。当然还有好多概念:服务限流、分流,请求与依赖分离等,后面有时间一一与大家分享。 
云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 39
39 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)