深度学习之六,基于RNN(GRU,LSTM)的语言模型分析与theano代码实现
引言前面已经介绍过RNN的基本结构,最基本的RNN在传统的BP神经网络上,增加了时序信息,也使得神经网络不再局限于固定维度的输入和输出这个束缚,但是从RNN的BPTT推导过程中,可以看到,传统RNN在求解梯度的过程中对long-term会产生梯度消失或者梯度爆炸的现象,这个在这篇文章中已经介绍了原因,对于此,在1997年的Grave大作[1]中提出了新的新的RNN结构:Long Short Te
引言
前面已经介绍过RNN的基本结构,最基本的RNN在传统的BP神经网络上,增加了时序信息,也使得神经网络不再局限于固定维度的输入和输出这个束缚,但是从RNN的BPTT推导过程中,可以看到,传统RNN在求解梯度的过程中对long-term会产生梯度消失或者梯度爆炸的现象,这个在这篇文章中已经介绍了原因,对于此,在1997年
的Grave大作[1]中提出了新的新的RNN结构:Long Short Term Dependency。LSTM在传统RNN的基础上加了许多的“门”,如input gate、forget gate、output gate等,因为这些门的引入,使得LSTM在BPTT的过程中避免了梯度爆炸或者消失的缺点,主要原因是LSTM在链式求导过程中从原来RNN的连乘改进到了连加。介绍LSTM的比较详细的博文见[2],关于LSTM的推导可以参看[3],或者看博文[4] GRU(Gated Rucurrent Unit)是2014年年首先被应用[5].GRU和LSTM差不多,不过是“门”不同罢了,基本思想差不多。关于GRU和LSTM孰好孰坏这个问题,也没有明确的答案,在不同的数据集上双方各有优劣吧。另外LSTM在这么多年的进展过程中,产生了很多的变体,这里不一而足,只是希望读者在看到不同的LSTM网络之后不要惊呼跟之前看到的LSTM网络结构不一样。PS:一入机器学习深似海,从此时间似路人…
语言模型
语言模型在NLP领域中有着重要的应用,传统的N-Gram语言模型虽然在一些方法中得到了应用,但是N-Gram存在着计算复杂度大且只能学习到N个word的上下文,对长序列文本建模效果并不好。神经网络语言模型(Neutral NetWork Language Model)最早在[6]被提出,从此神经网络语言模型呈星火燎原之势,在NLP领域大展身手,尤其是在机器翻译领域。后来RNN神经语言模型被提出来,RNN能够学习序列的特征被应用到语言建模中,而其中以LSTM和GRU应用的最为广泛,本文着重就对LSTM为基本结构来对语言进行建模。
LSTM语言模型构建
如果对LSTM不熟悉的话可以先看看[2],LSTM的变体很多,光[2]里面提到的就有好几个,但是对于选用什么结构的LSTM,因为没有实验依据,所以我就是随便选一个进行实验,本次实验选取的LSTM的单元cell结构如下:
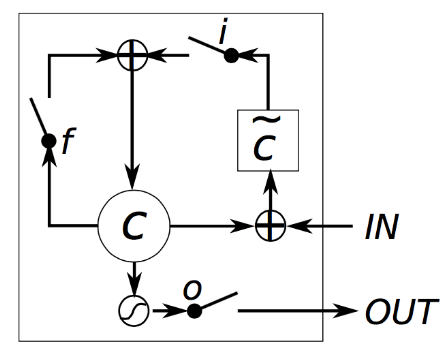
而根据上面的LSTM单元结构,其计算公式如下:
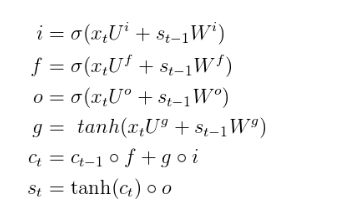
然后我们回到语言建模上,明确LSTM的输入输出。
所谓语言建模,也就是在给定一个单词序列之后,预测下一个词产生的概率,比如在进行训练之后,给定一句话”I Love“,那么这句话下个词的概率分布可能是[“you”:0.6, “China”:0.05, “Food”:0.1 ,”NewYork”:0.05, “Mom”:0.1, “game”:0.1] (当然这是一个假设)。根据概率分布,那么这句话下个词很可能是“You”。了解到这点之后就可以进一步明白LSTM的输入输出了。
假设现有的词表大小vocab_size是2000个,将每句话的前面加上特殊的单词“SENTENCE_START_TOKEN”以及在结尾加上”SENTENCE_END_TOKEN”,然后将句子的每个单词转换成词向量,也就是word embedding,我们可以得到下面的输入输出:
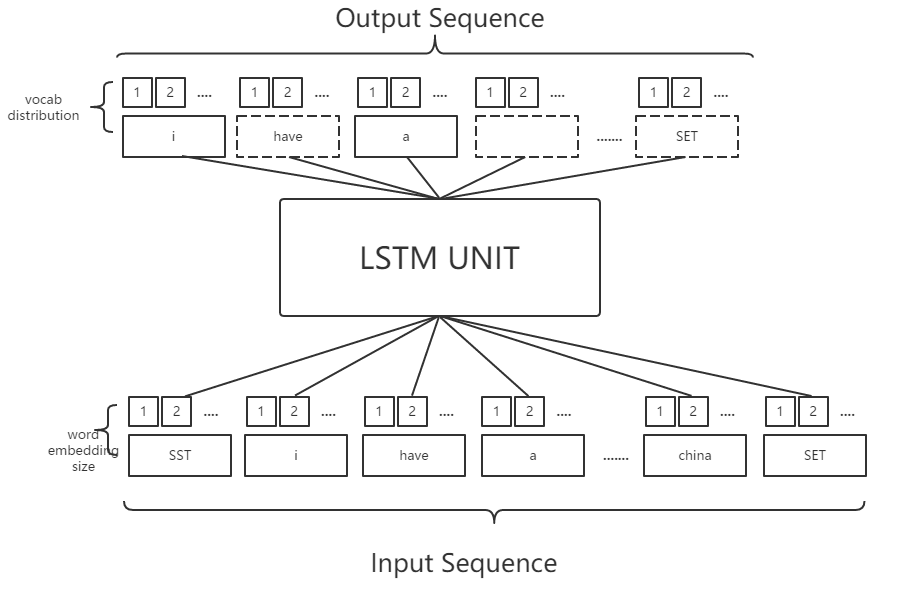
注:SST为SENTENCE_START_TOKEN
SET为SENTENCE_END_TOKEN
从上面的图中可以看出,输入序列中,每个单词都做了word_embedding,也就是转换成了向量,这个过程可以随机初始化,亦可以使用Google的word2vec这个开源工具进行提前训练。转换成词向量之后,经过LSTM运算,以”i”这个词为例,得到的是i的下一个词的分布情况,如果正确的话,其词分布应该是“have”这个词的概率最高。我们亦可以知道输出层的维度应该是词表的维度。
明白了这个就很好理解了下面的程序代码了。
实验
实验基于博文[7]稍加改进的,需要说明的是,原文中使用的是GRU结构,我改成了LSTM结构。
实验数据:15000条 Google’s BigQuery数据集上的Reddit Comment
实验系统:windows7
语言:python
工具:theano等
GPU型号:GT720
LSTM主要代码:
# -*- coding:utf-8 -*-
import numpy as np
import theano
import theano.tensor as T
import operator
import time
class LSTM_Theano:
def __init__(self, word_dim, hidden_dim=128, bptt_truncate=-1):
#初始化参数
self.word_dim=word_dim
self.hidden_dim=hidden_dim
self.bptt_truncate=bptt_truncate
E=np.random.uniform(-np.sqrt(1./word_dim), np.sqrt(1./word_dim), (hidden_dim, word_dim))
U = np.random.uniform(-np.sqrt(1./hidden_dim), np.sqrt(1./hidden_dim), (4, hidden_dim, hidden_dim))
W = np.random.uniform(-np.sqrt(1./hidden_dim), np.sqrt(1./hidden_dim), (4, hidden_dim, hidden_dim))
V = np.random.uniform(-np.sqrt(1./hidden_dim), np.sqrt(1./hidden_dim), (word_dim, hidden_dim))
b = np.zeros((4, hidden_dim))
c = np.zeros( word_dim)
# Theano: 产生 shared variables
self.E = theano.shared(name='E', value=E.astype(theano.config.floatX))
self.U = theano.shared(name='U', value=U.astype(theano.config.floatX))
self.W = theano.shared(name='W', value=W.astype(theano.config.floatX))
self.V = theano.shared(name='V', value=V.astype(theano.config.floatX))
self.b = theano.shared(name='b', value=b.astype(theano.config.floatX))
self.c = theano.shared(name='c', value=c.astype(theano.config.floatX))
# SGD / 使用rmsprop提供的参数
self.mE = theano.shared(name='mE', value=np.zeros(E.shape).astype(theano.config.floatX))
self.mU = theano.shared(name='mU', value=np.zeros(U.shape).astype(theano.config.floatX))
self.mV = theano.shared(name='mV', value=np.zeros(V.shape).astype(theano.config.floatX))
self.mW = theano.shared(name='mW', value=np.zeros(W.shape).astype(theano.config.floatX))
self.mb = theano.shared(name='mb', value=np.zeros(b.shape).astype(theano.config.floatX))
self.mc = theano.shared(name='mc', value=np.zeros(c.shape).astype(theano.config.floatX))
self.theano = {}
self.__theano_build__()
def __theano_build__(self):
E, U, W, V , b, c = self.E, self.U, self.W, self.V, self.b, self.c
x = T.ivector('x')
y = T.ivector('y')
#前馈神经网络
def forward_prop_step(x_t, s_prev,c_prev):
#word embedding层
x_e = E[:,x_t]
#LSTM_layer
i=T.nnet.hard_sigmoid(U[0].dot(x_e)+W[0].dot(s_prev)+b[0])
f=T.nnet.hard_sigmoid(U[1].dot(x_e)+W[1].dot(s_prev)+b[1])
o=T.nnet.hard_sigmoid(U[2].dot(x_e)+W[2].dot(s_prev)+b[2])
g=T.tanh(U[3].dot(x_e)+W[3].dot(s_prev)+b[3])
c_t=c_prev*f+g*i
s_t=T.tanh(c_t)*o
#计算输出层结果
o_t = T.nnet.softmax(V.dot(s_t) + c)[0]
return [o_t,s_t,c_t]
[o,s,c_o],updates=theano.scan(
forward_prop_step,
sequences=x,
truncate_gradient=self.bptt_truncate,
outputs_info=[None,
dict(initial=T.zeros(self.hidden_dim)),
dict(initial=T.zeros(self.hidden_dim))]
)
prediction = T.argmax(o, axis=1)
o_error = T.sum(T.nnet.categorical_crossentropy(o, y))
#计算总代价(当然可以加上规范化因子)
cost = o_error
#计算梯度
dE = T.grad(cost, E)
dU = T.grad(cost, U)
dW = T.grad(cost, W)
db = T.grad(cost, b)
dV = T.grad(cost, V)
dc = T.grad(cost, c)
self.predict = theano.function([x], o)
self.predict_class = theano.function([x], prediction)
self.ce_error = theano.function([x, y], cost)
self.bptt = theano.function([x, y], [dE, dU, dW, db, dV, dc])
# 随机梯度下降参数
learning_rate = T.scalar('learning_rate')
decay = T.scalar('decay')
# rmsprop cache 更新
mE = decay * self.mE + (1 - decay) * dE ** 2
mU = decay * self.mU + (1 - decay) * dU ** 2
mW = decay * self.mW + (1 - decay) * dW ** 2
mV = decay * self.mV + (1 - decay) * dV ** 2
mb = decay * self.mb + (1 - decay) * db ** 2
mc = decay * self.mc + (1 - decay) * dc ** 2
#梯度下降更新参数
self.sgd_step = theano.function(
[x, y, learning_rate, theano.Param(decay, default=0.9)],
[],
updates=[(E, E - learning_rate * dE / T.sqrt(mE + 1e-6)),
(U, U - learning_rate * dU / T.sqrt(mU + 1e-6)),
(W, W - learning_rate * dW / T.sqrt(mW + 1e-6)),
(V, V - learning_rate * dV / T.sqrt(mV + 1e-6)),
(b, b - learning_rate * db / T.sqrt(mb + 1e-6)),
(c, c - learning_rate * dc / T.sqrt(mc + 1e-6)),
(self.mE, mE),
(self.mU, mU),
(self.mW, mW),
(self.mV, mV),
(self.mb, mb),
(self.mc, mc)
])
def calculate_total_loss(self, X, Y):
return np.sum([self.ce_error(x,y) for x,y in zip(X,Y)])
def calculate_loss(self, X, Y):
# Divide calculate_loss by the number of words
num_words = np.sum([len(y) for y in Y])
return self.calculate_total_loss(X,Y)/float(num_words)
上面的计算过程是和之前提到的LSTM计算公式是一致的,我也是Theano新手,所以不会解释具体的代码意思,但是主要的步骤注释还是给出了,Theano基本还算是简洁,只不过是我还是有点欠熟练。
实验结果:
由于我的GPU不太给力,因此代码还在跑,可以展示一些中间成果,中间成果是利用训练出来的模型自动生成语句,给出10个机器生成的例子:
2016-05-26T18:06:21.331000 (25000)
--------------------------------------------------
Loss: 4.671137
SENTENCE_START UNKNOWN_TOKEN on thought how you can be much time i do n't think you over to . SENTENCE_END
SENTENCE_START i ca n't UNKNOWN_TOKEN only UNKNOWN_TOKEN . SENTENCE_END
SENTENCE_START if you can you , . SENTENCE_END
SENTENCE_START so they can UNKNOWN_TOKEN countries of UNKNOWN_TOKEN him back if you you sister '' would is n't . SENTENCE_END
SENTENCE_START it like her by sitting to you can UNKNOWN_TOKEN been be ... SENTENCE_END
SENTENCE_START UNKNOWN_TOKEN UNKNOWN_TOKEN UNKNOWN_TOKEN my UNKNOWN_TOKEN : already with a UNKNOWN_TOKEN right for ) UNKNOWN_TOKEN . SENTENCE_END
SENTENCE_START ( only ) SENTENCE_END
SENTENCE_START i 'm not . SENTENCE_END
SENTENCE_START `` so i have , i would have much ... when i 'm of to for UNKNOWN_TOKEN when UNKNOWN_TOKEN : much that is the they would this as good , edit not i read a UNKNOWN_TOKEN ! SENTENCE_END
SENTENCE_START & gt ; is it with the UNKNOWN_TOKEN way over that one as you do n't ) , not like you could for to UNKNOWN_TOKEN than UNKNOWN_TOKEN . SENTENCE_END
保存模型参数至于 LSTM-2016-05-26-17-05-2000-48-128.dat.其中SENTENCE_START_TOKEN和SENTENCE_END_TOKEN是句子的开头和结尾。当前看来,其结果还不是很好,这个实验主要是为了学习LSTM的结构和学习神经网络语言模型,得到了这个效果也还算欣慰,毕竟不是正儿八经的论文实验。
后记
从接触RNN,到LSTM和GRU,其实我内心是拒绝的,因为作为一个数学功底薄弱的渣硕,看到复杂的公式也确实是头大,不过慢慢接触下来,谈不上有多精通,也算能够慢慢的跟上节奏吧,还是收获颇丰的。
转瞬就要奔研究生二年级去了,心中还是没有什么底,见招拆招吧~
所有的代码可以在这里下载
参考文献
[1]Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural computation, 1997, 9(8): 1735-1780.
[2]Understanding LSTM Network
[3]A. Graves. Supervised Sequence Labelling with Recurrent Neural Networks. Textbook, Studies in Computational Intelligence, Springer, 2012.
[4]RNN以及LSTM的介绍和公式梳理
[5]Cho K, Merrienboer B V, Gulcehre C, et al. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation[J]. Eprint Arxiv, 2014.
[6]Bengio Y, Schwenk H, Senécal J S, et al. A neural probabilistic language model[J]. Journal of Machine Learning Research, 2003, 3(6):1137-1155.
[7]RECURRENT NEURAL NETWORK TUTORIAL, PART 4 – IMPLEMENTING A GRU/LSTM RNN WITH PYTHON AND THEANO

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)