
Linux调度浅析
对称多处理结构(Symmetrical Multi-Processing)是指在一个计算机上汇集了一组处理器(多CPU),各CPU之间共享内存子系统以及总线结构。这种体系架构实现了多个CPU可以同时执行各个任务,对多线程的应用程序非常有益。尽管优先级调度在 SMP 系统上也可以工作,但是它的大锁体系架构意味着当一个CPU选择一个任务进行分发调度时,运行队列会被这个CPU加锁,其他CPU只能等待。C
对称多处理结构(Symmetrical Multi-Processing)是指在一个计算机上汇集了一组处理器(多CPU),各CPU之间共享内存子系统以及总线结构。这种体系架构实现了多个CPU可以同时执行各个任务,对多线程的应用程序非常有益。尽管优先级调度在 SMP 系统上也可以工作,但是它的大锁体系架构意味着当一个CPU选择一个任务进行分发调度时,运行队列会被这个CPU加锁,其他CPU只能等待。
CPU调度的任务是控制,协调进程对CPU的竞争,即按照一定的调度算法从就绪队列中选择一个进程把CPU的使用权交给被选中的进程。如果没有就绪进程,系统会安排一个系统空闲进程或者idle进程上CPU运行。CPU调度要解决的3个问题:
what?即按什么原则选择下一个要执行的程序,这个依靠调度算法来实现。
when?即什么时候选择,指的是调度时机。
how?即如何让被选中的进程上CPU执行,指的是调度过程,涉及到进程上下文切换(一个进程让出CPU,由另一个进程占用CPU的过程)
CPU调度的系统场景
- N个进程就绪,等待上CPU运行
- M个CPU,M>=1
这时候就需要决策分配哪一个进程到哪一个CPU上运行?
调度的时机
典型的事件举例:
- 创建,唤醒,退出等进程控制操作
- 进程等待I/O,I/O中断
- 时钟中断,如:时间片用完,计时器到时
- 进程执行过程中出现abort异常
事件发生会导致当前运行的进程暂停运行,硬件机制响应后由操作系统处理相应的事件,处理结束后,某些进程的状态会发生变化,也可能又创建了一些新的进程,这样就绪队列就会发生改变,这时就需要进程调度根据预设的调度算法从就绪队列选一个进程。
CPU调度决策可在如下4种情况环境下发生:
- 新进程创建或一个等待进程变成就绪
- 当一个进程从运行状态切换到就绪状态
- 当一个进程从运行状态切换到阻塞状态
- 当一个进程正常终止或由于某种错误终止
总而言之调度的触发通常是在内核对中断、异常、系统调用处理完成后从内核态返回到用户态时。
调度策略
For real time scheduling 实时进程
SCHED_RR
Round-robin fashion,each process gets a max CPU time
一旦时间片消耗完毕,则会将该进程置于队列的末尾,然后运行其他相同优先级的进程,如果没有其他相同优先级的进程,则该进程会继续执行。
SCHED_FIFO
只有当前进程执行完毕才会轮到其他进程执行。但是当前进程有严重的I/O延迟,系统会自动的调另一个上去。或者这个进程用sched_yield函数把CPU隔一段时间分出去。或者它被高优先级的进程取代。
Runs until blocked by I/O,calls sched_yield or preempted by a higher priority process
For general scheduling 普通进程
SCHED_NORMAL
For general applocations,standard round-robin policy
SCHED_BATCH
针对批量的处理的操作的进程;比如对数据进行压缩,合并等等。不能中断,而且运行时间较久。如果运用了这个策略,CPU会相应的照顾到这些进程。
For batch style process,tuned to not be preempted tpp often,tacks run longer,make better use of caches
SCHED_IDLE
For low priority applications,with a very low priority(lower than nice 19)
Linux进程分类
第一种分为系统进程和普用户进程;系统进程是操作系统为了管理一些资源而创建的,优先级比普通的用户进程高。
第二种分为前台进程和后台进程;前台进程与用户直接交互,例如键盘鼠标的敲击,后台进程往往是系统启动初始化时创建的进程,为用户提供服务,比如防火墙,打印机,邮件服务等。
第三种为CPU密集型和I/O密集型,这种分类实际上考虑了进程行为,比如在玩3D游戏中,画面的渲染需要大量的计算,这就属于CPU密集型进程;再比如对文件的操作会涉及到大量的读盘以及输入输出,这就属于I/O密集型进程,这样的区分是为了进程调度做准备。
调度器对进程的分类
实时进程对调度延迟的要求最高,这些进程往往执行非常重要的操作,要求立即响应并执行,不能容忍长时间的调度延迟。
交互式进程有大量的人机交互,因此进程不断地处于睡眠状态,等待用户输入,一般多为I/O密集型进程。此类进程对系统响应时间要求比较高,否则用户会感觉系统反应迟缓。
批处理进程不需要人机交互,在后台运行,需要占用大量的系统资源,一般多为CPU密集型进程,但是能够忍受响应延,比如编译器。
Linux进程优先级
实时进程只有静态优先级,内核不会根据休眠等因素对其静态优先级做调整;而普通进程有静态优先级和动态优先级。任何时候,实时进程的优先级都高于普通进程,实时进程只会被优先级更高的实时进程抢占,同级实时进程之间是按照FIFO或者RR规则调度的。
静态优先级(static priority)隐藏在内核中,是用户不可见的,但内核提供了一个可以影响静态优先级的接口——nice值,即在用户空间可以通过系统调用修改nice值,进而影响进程的静态优先级变化。
static_prio= MAX_RT_PRIO + nice + 20 【MAX_RT_PRIO值为100】【nice取值范围为-20-19】
动态优先级
系统调度时,不仅要考虑静态优先级,也要考虑进程的属性,因此有了进程动态优先级的概念。为了防止高优先级进程独占 CPU 造成其他低优先级进程饿死的现象,Linux 2.6 版本的调度器采用了惩罚CPU密集型的进程或奖励 I/O 密集型的进程的策略。简单来说就是调度器监控优先级在100-139之间的进程,先判断其等待时间是否过长,而后调高或降低相应进程的优先级。
dynamic prio=max(100,min(static prio- bonus +5,139 )) 【bonus的取值范围为0-10】
综上所述,一般来说与用户的通信大多都是的交互式进程(交互性指标=进程执行所花费的时间/睡眠所花费的时间),I/O 密集型进程的交互性比CPU密集型的更强,因此可以适当的调高 I/O 密集型进程的优先级,分配较短的时间片,以获得更好的交互式响应能力;而CPU密集型的进程应该分配较低的优先级和较长的时间片
调度器的概念
通常来说,操作系统是应用程序和可用资源之间的媒介。典型的资源有内存和物理设备。但是 CPU也可以认为是一个资源,调度器可以临时分配一个任务在上面执行(单位是时间片)。调度器使得同时执行多个程序成为可能,因此可以与具有各种需求的用户共享CPU。调度器的一个重要目标是有效地分配 CPU 时间片,同时提供很好的用户体验。调度器还需要面对一些互相冲突的目标,例如既要为关键实时任务最小化响应时间,又要最大限度地提高CPU的总体利用率。
早期 Linux 调度器的缺陷
在Linux 2.4版本的内核中,可执行状态的进程被挂在一个链表中。每次调度,调度程序需要扫描整个链表,以找出最优的那个进程来运行。复杂度为O(n);活动的任务越多,调度任务所花费的时间越长。在任务负载非常重时,处理器会因调度消耗掉大量的时间,用于任务本身的时间就非常少了。因此,这个算法缺乏可伸缩性。
在SMP中,2.6 版本之前的调度器只设计了一个运行队列,这意味着一个任务可以在任何处理器上进行调度 。这对于负载均衡来说是好事,但是对于内存缓存来说却是个灾难。例如正在CPU-1 上执行的一个任务,随后被调度到 CPU-2 上执行,那么先前在 CPU-1 上缓存的数据需要先使其无效,并将其放到CPU-2的缓存中。
早期的调度器还使用了一个运行队列锁;因此在 SMP 系统中,选择一个任务执行就会阻碍其他处理器操作这个运行队列。结果是空闲处理器只能等待这个处理器释放出运行队列锁,这样会造成效率的降低。
在早期的内核中没有抢占机制;这意味着如果有一个低优先级的任务在执行,高优先级的任务只能等待它完成。
Linux 2.6 调度器简介
2.6 版本的调度器是由 Ingo Molnar 设计并实现的。Ingo 从 1995 年开始就一直参与 Linux 内核的开发。他编写这个新调度器的动机是为唤醒、上下文切换和定时器中断开销建立一个完全 O(1) 的调度器。触发对新调度器的需求的起因之一是JVM的使用。Java 编程模型使用了很多执行线程,在 O(n) 调度器中这会产生很多调度负载。O(1) 调度器在这种高负载的情况下并不会受到太多影响,因此 JVM 可以有效地执行。2.6 版本的调度器解决了以前调度器中O(n) 、 SMP 可伸缩性的问题、以及抢占等其他一些问题。
在linux 2.6早期,可执行状态的进程被挂在N(N=140)个链表中,每一个链表代表一个优先级,系统中支持多少个优先级就有多少个链表。每次调度,调度程序只需要从第一个不为空的链表中取出位于链表头的进程即可。这样就大大提高了调度程序的效率,复杂度为O(1);
在linux 2.6近期的版本中,可执行状态的进程按照优先级顺序被挂在一个红黑树(可以想象成平衡二叉树)中。每次调度,调度程序需要从树中找出优先级最高的进程。复杂度为O(logN)。
Linux 2.6 版本调度器允许抢占,这意味着当高优先级的进程准备运行时,调度器会抢占低优先级的进程,并将这个进程放回其优先级列表中,然后重新进行调度。
2.6 版本的调度器不再使用一个锁进行调度;而是对每个运行队列都有一个锁;这样允许所有的 CPU 都可以对任务进行调度,而不会与其他CPU产生竞争,因此可以更好地支持 SMP 系统。另外,由于每个处理器都有一个运行队列,因此任务通常都是与CPU密切相关的,可以更好地利用CPU的热缓存。
2.6 版调度器结构
每个 CPU 都有一个运行队列,其中包含了 140 个优先级列表,它们是按照FIFO的顺序进行服务的。被调度执行的进程都会被添加到各自运行队列优先级列表的末尾。每个任务都有一个时间片,这取决于系统允许执行这个任务多长时间。Linux内核中使用内部优先级0~(MAX_RT_PRIO-1)来标识实时进程【MAX_RT_PRIO值默认为100】,即实时进程优先级取值范围为1-99,优先级随数字增大递增;普通进程的内部优先级从MAX_RT_PRIO到(MAX_RT_PRIO + 40)。nice值从-20到19,分别对应内部优先级100到140;即nice值越低,表示普通进程的优先级越高。标准的Linux提供两种实时调度策略,分别是SCHED_FIFO,SCHED_RR。其中,SCHED_FIFO是主要使用的实时调度策略。

除了 CPU 正在运行的活动运行队列(active runqueue)之外,还有一个过期运行队列(expired runqueue)。当活动运行队列中的一个进程用完自己的时间片之后,它就被移动到过期运行队列中。在移动过程中,会对其时间片重新进行计算(因此会体现其优先级的作用)。如果活动运行队列中已经没有某个给定优先级的任务了,那么指向活动运行队列和过期运行队列的指针就会交换,这样就可以让过期优先级列表变成活动优先级列表。
调度过程:在优先级最高的队列中选择一个进程来执行。为了使这个过程的效率更高,内核使用了一个位图来定义给定优先级列表上何时存在进程。查找一个进程来执行所需要的时间并不依赖于活动任务的个数,而是依赖于优先级的数量。这使得 2.6 版本的调度器成为一个复杂度为 O(1) 的过程,因为调度时间既是固定的,而且也不会受到活动任务个数的影响。
SMP 负载均衡
在SMP系统中创建任务时,这些任务都被放到一个给定的CPU运行队列中。通常来说,我们无法知道一个任务何时是短期存在的,何时需要长期运行。因此最初任务到CPU的分配可能并不理想。为了在CPU之间维护任务负载的均衡,任务可以重新进行分发:将任务从负载重的CPU上移动到负载轻的CPU 上。Linux 2.6 版本的调度器使用负载均衡(load balancing) 提供了这种功能。每隔 200ms,处理器都会检查 CPU 的负载是否不均衡;如果不均衡,处理器就会在 CPU 之间进行一次任务均衡操作。
这个过程的缺陷是新 CPU 的缓存对于迁移过来的任务来说是冷的(CPU 的本地缓存中没有任何数据,需要将数据读入缓存中)。CPU 缓存是一个本地内存,提供了比系统内存更快的访问能力。如果一个任务是在某个 CPU 上执行的,与这个任务有关的数据都会被放到这个 CPU 的本地缓存中,这就称为热的。不幸的是,保持 CPU 繁忙会出现 CPU 缓存对于迁移过来的任务为冷的情况。
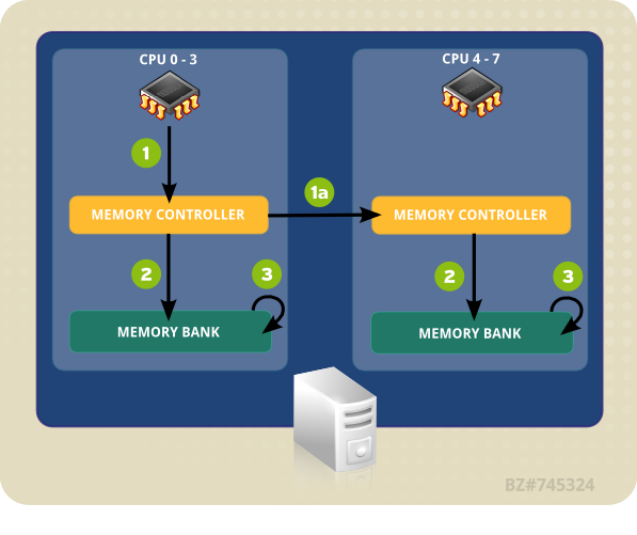
Non Uniform Memory Access Architecture非一致内存访问
由于传统的SMP系统中,所有处理器都共享系统总线,因此当处理器的数目增大时,系统总线的竞争冲突加大,系统总线将成为瓶颈,所以目前SMP系统的CPU数目一般只有数十个,可扩展能力受到极大限制。NUMA技术有效结合了SMP系统易编程性和MPP(大规模并行)系统易扩展性的特点,较好解决了 SMP系统的可扩展性问题,已成为当今高性能服务器的主流体系结构之一。目前国外著名的服务器厂商都先后推出了基于NUMA架构的高性能服务器,如HP的 Superdome、SGI的Altix 3000、IBM的 x440、NEC的TX7、AMD的Opteron等。随着Linux在服务器平台上的表现越来越成熟,Linux内核对NUMA架构的支持也越来越完善,特别是从2.5开始,Linux在调度器、存储管理、用户级API等方面进行了大量的NUMA优化工作,目前这部分工作还在不断地改进,如新近推出的 2.6.7-RC1内核中增加了NUMA调度器。
NUMA系统的结点通常是由一组CPU和本地内存组成,有的结点可能还有I/O子系统。由于每个结点都有自己的本地内存,因此系统的内存在物理上是分布的,由于局部内存的访存延迟低于远地内存访存延迟,因此将进程分配到局部内存附近的处理器上可极大优化应用程序的性能。
Local and Remote Memory Access in NUMA Topolog
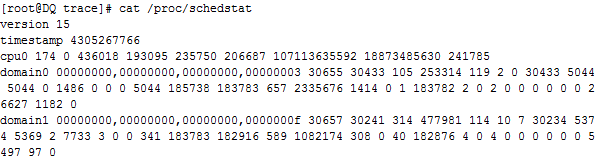
2.6 版本的调度器还可以提供一些统计信息(如果启用了 CONFIG_SCHEDSTATS)。这些统计信息可以从 /proc 文件系统中的 /proc/schedstat 看到,它为系统中的每个 CPU 都提供了很多数据,包括负载均衡和进程迁移的统计信息。
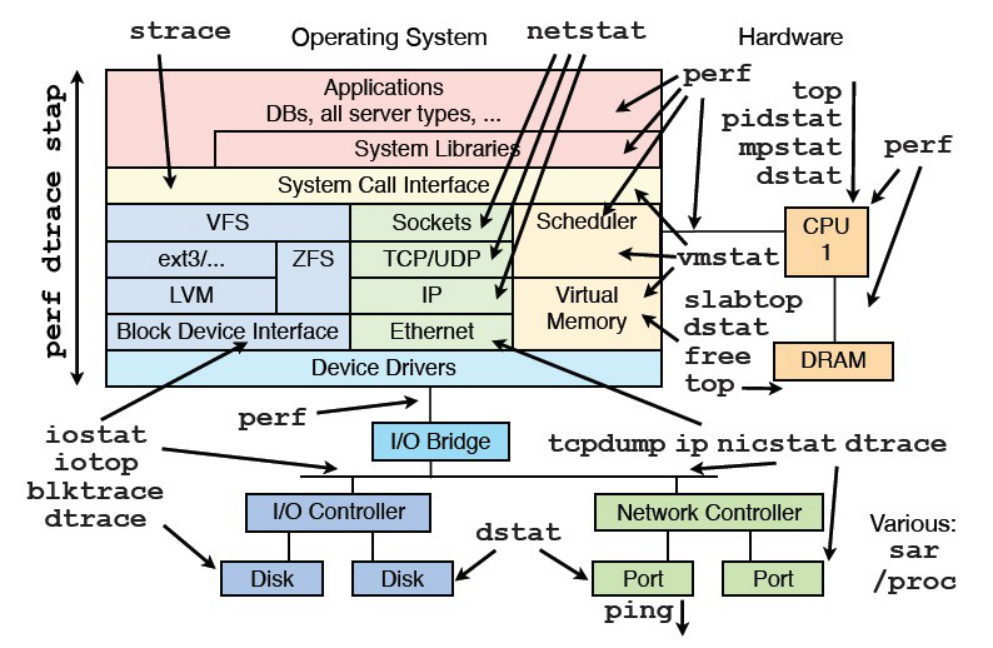
Linux常用性能调优工具索引
主要参考
http://www.cnblogs.com/zhaoyl/archive/2012/09/04/2671156.html
http://www.ibm.com/developerworks/cn/linux/l-scheduler/
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)