
java中hashmap容器实现查找O(1)时间复杂度的思考
我一直有个疑问,为什么hashmap能够实现O(1)的查找复杂度。。纵使其存储了一些键值对,那也只能保证你找到了key值之后,能够在O(1)事件内查询到value值。。而我的疑问是,怎么保证key值的查找也在O(1)事件内完成。而这也是整个hashmap中最关键的问题。一、理解:通过阅读jdk的源码,我对该问题的理解如下:我们知道hashmap在存储键值对时借助了“数组+链表”的方式。
·
我一直有个疑问,为什么hashmap能够实现O(1)的查找复杂度。。纵使其存储了一些键值对<key,value>,那也只能保证你找到了key值之后,能够在O(1)事件内查询到value值。。而我的疑问是,怎么保证key值的查找也在O(1)事件内完成。而这也是整个hashmap中最关键的问题。
一、理解:
![]()
通过阅读jdk的源码,我对该问题的理解如下:
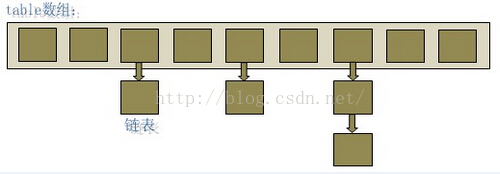
我们知道hashmap在存储键值对时借助了“数组+链表”的方式。
我们对一个键值对的查询,是分为四步的。
- 先根据key值计算出hash值以及h值(h值是java实现中处理得到的更优的index索引值)
- 查找table数组中的h位置,得到相应的键值对链表
- 根据key值,遍历键值对链表,找到相应的键值对,
- 从键值对中取出value值。
只有以上四步都能在O(1)时间内完成,hashmap才能拥有O(1)的时间复杂度。易知,步骤1(计算)、步骤2(数组的查找)和步骤4(从键值对中取value值)都可以在O(1)时间内完成。那么,步骤3中链表的长度决定了整个hashmap容器的查找效率,这也是hashmap容器设计的关键。必须采用优秀的hash算法以减少“冲突”,使得链表的长度尽可能短,理想状态下链表长度都为1。
二、结论:
- hashmap容器O(1)的查找时间复杂度只是其理想的状态,而这种理想状态需要由java设计者去保证
- 在由设计者保证了链表长度尽可能短的前提下,由于利用了数组结构,使得key的查找在O(1)时间内完成
- 可以将hashmap分成两部分来看待,hash和map。map只是实现了键值对的存储,也就是以上查询步骤的第4步。而其整个O(1)的查找复杂度很大程度上是由hash来保证的。
- hashmap对hash的使用体现出一些设计哲学,如:通过key.hashCode()将普通的object对象转换为int值,从而可以将其视为数组下标,利用数组O(1)的查找性能。

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)