稀疏表示综述:A Survey of Sparse Representation: Algorithms and Applications_2015(2)
稀疏表示综述:A Survey of Sparse Representation: Algorithms and Applications_2015(2)本文地址:http://blog.csdn.net/shanglianlm/article/details/46866803
稀疏表示综述:A Survey of Sparse Representation: Algorithms and Applications_2015(2)
本文地址:http://blog.csdn.net/shanglianlm/article/details/46866803
VI. 基于邻近算法的优化策略(PROXIMITY ALGORITHM BASED OPTIMIZATION STRATEGY)
proximity algorithm 的核心是 使用邻近算子(proximal operator)去迭代地求解子问题(sub-problem)。
proximity algorithm 被广泛地应用于求解非光滑(nonsmooth),约束凸优化问题(constrained convex optimization problems) [29]。
假设一个简单的约束优化问题
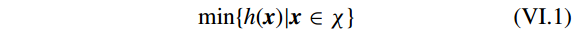
其中
χ⊂Rn
。
使用 proximity algorithm 解原问题为
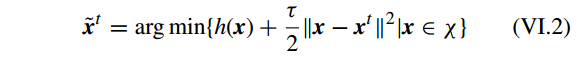
其中
τ
和
不失一般性,假设一个线性约束的凸优化问题
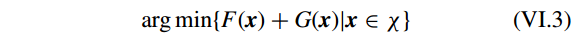
通过使用 proximity algorithm, 问题 VI.3 的解为
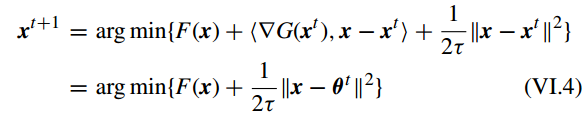
其中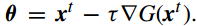
更具体地来说,对于 带有 l1-norm正则化 的稀疏表示问题,能被写为
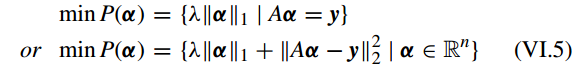
A. 软阈值或收缩操作符(SOFT THRESHOLDING OR SHRINKAGE OPERATOR)


B. 迭代收缩阈值算法(ITERATIVE SHRINKAGE THRESHOLDING ALGORITHM (ISTA))





[80] M. A. T. Figueiredo and R. D. Nowak, ‘‘A bound optimization approach to wavelet-based image deconvolution,’’ in Proc. IEEE Int. Conf. Image Process., vol. 2. Sep. 2005, pp. II-782–II-785.
[81] P. L. Combettes and J. C. Pesquet, ‘‘Proximal splitting methods in signal processing,’’ in Fixed-Point Algorithms for Inverse Problems in Science and Engineering. New York, NY, USA: Springer-Verlag, 2011, pp. 185–212.
C. 加速地迭代收缩阈值算法(FAST ITERATIVE SHRINKAGE THRESHOLDING ALGORITHM (FISTA))



[82] A. Beck and M. Teboulle, ‘‘A fast iterative shrinkage-thresholding algorithm for linear inverse problems,’’ SIAM J. Imag. Sci., vol. 2, no. 1, pp. 183–202, 2009.
[83] A. Y. Yang, S. S. Sastry, A. Ganesh, and Y. Ma, ‘‘Fast L1-minimization algorithms and an application in robust face recognition: A review,’’in Proc. 17th IEEE Int. Conf. Image Process. (ICIP), Sep. 2010, pp. 1849–1852
D. 由可分近似稀疏重建(SPARSE RECONSTRUCTION BY SEPARABLE APPROXIMATION (SpaRSA))
Sparse reconstruction by separable approximation (SpaRSA) [84] 使用 热启动(worm-starting)技术优化问题 VI.8 中的参数 λ 和使用 Barzilai-Borwein (BB) 谱方法[85] 为问题 VI.9中的 Hf(α) 选择一个更合适的近似。
1) 使用热启动技术优化 λ(UTILIZING THE WORM-STARTING TECHNIQUE TO OPTIMIZE λ)
SpaRSA 使用一个一种自适应连续技术来更新 λ 的值,使得它更快地收敛。
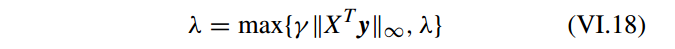
其中 γ 是小的常数。
2) 使用 BB 谱方法近似
Hf(α)
(UTILIZING THE BB SPECTRAL METHOD TO APPROXIMATE
Hf(α)
)
- ISTA 使用 (1/τ)I 来近似
Hf(α)
;
- FISTA使用 ∇f(α) 的 Lipschitz 常数来近似
Hf(α)
;
- SpaRSA 使用 BB 谱方法选择 τ 的值 来仿真
Hf(α)
。
τ 的值要求满足下列条件:
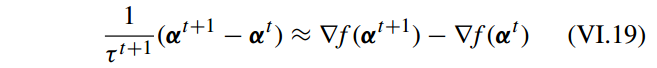
其中 满足最小化问题
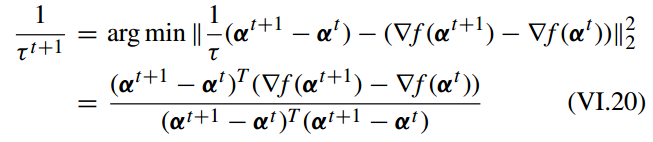
SpaRSA 具体算法:

[84] S. J. Wright, R. D. Nowak, and M. A. T. Figueiredo, ‘‘Sparse reconstruction by separable approximation,’’ IEEE Trans. Signal Process., vol. 57, no. 7, pp. 2479–2493, Jul. 2009.
[85] Y.-H. Dai, W. W. Hager, K. Schittkowski, and H. Zhang, ‘‘The cyclic Barzilai–Borwein method for unconstrained optimization,’’ IMA J. Numer. Anal., vol. 26, no. 3, pp. 604–627, 2006.
E. 基于 l1/2 -norm 正则化的稀疏重建( l1/2 -NORM REGULARIZATION BASED SPARSE REPRESENTATION)
带有 lp-norm (0 < p < 1) 正则化的稀疏表示 通常是 一个 nonconvex, nonsmooth, 和 non-Lipschitz 优化问题。但是, 大多数有代表性的有关 lp-norm (0 < p < 1) 正则化 的算法是带有 l1/2 -norm 正则化的稀疏表示 [87]。
[60] 提出一个半接近(half proximal algorithm)算法来求解 l1/2 -norm 正则化问题。它使用 iterative shrinkage thresholding algorithm 处理 l1 -norm regularization 和 使用 iterative hard thresholding algorithm 处理 l0-norm regularization。
带有
l1/2
-norm 正则化的稀疏表示问题:
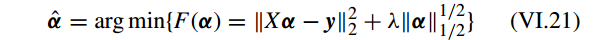
其中 F(α) 关于 α 的 一阶优化条件(first-order optimality condition)为
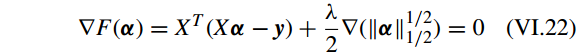
有
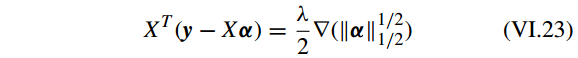
其中
∇(||α||1/21/2)
是
||α||1/21/2
的梯度。
两边同时乘以一个正常数 τ 和添加一个参数 α ,
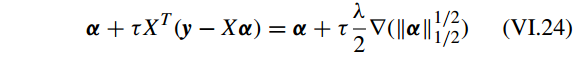
引入 解算子(resolvent operator):
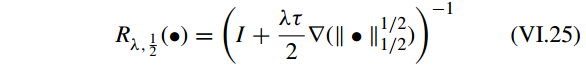
因此有
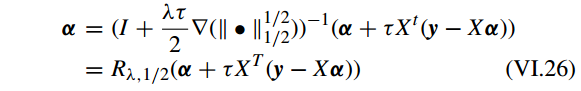
定义
θ(α)=α+τXT(y−Xα)
, the resolvent operator 可以表示为
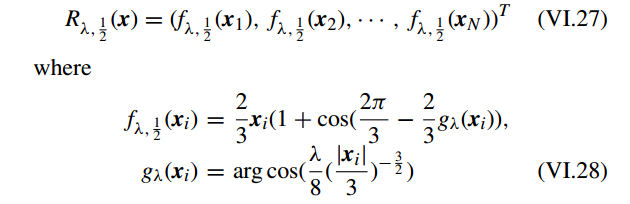
因此,
l1/2
-norm正则化的半接近阈值函数(half proximal thresholding function)定义为:
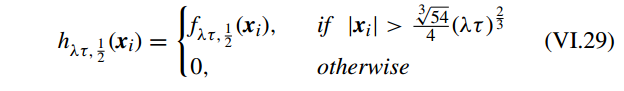
等式 VI.29 代入等式 VI.27,问题 VI.25 可以写成
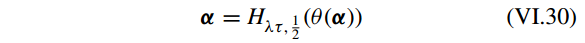
到目前为止,half proximal thresholding 算法可以用 等式 VI.30 来构建。等式 VI.24中 λ 和 τ 的值使用下面的优化
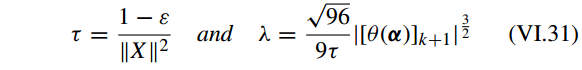
其中 ε 是一个很接近于 0 的常数, k 表示 稀疏的极限 (i.e. k-sparsity),
[∙]k
表示 [•] 中第 k 个最大的成分。
详细算法见

[60] Z. Xu, X. Chang, F. Xu, and H. Zhang, ‘‘L1/2 regularization: A thresholding representation theory and a fast solver,’’ IEEE Trans. Neural Netw. Learn. Syst., vol. 23, no. 7, pp. 1013–1027, Jul. 2012.
[87] J. Zeng, Z. Xu, B. Zhang, W. Hong, and Y. Wu, ‘‘Accelerated L1/2 regularization based SAR imaging via BCR and reduced Newton skills,’’Signal Process., vol. 93, no. 7, pp. 1831–1844, 2013.
[88] J. Zeng, S. Lin, Y. Wang, and Z. Xu, ‘‘L1/2 regularization: Convergence of iterative half thresholding algorithm,’’ IEEE Trans. Signal Process., vol. 62, no. 9, pp. 2317–2329, May 2014.
F. 基于增广拉格朗日乘子的优化策略(AUGMENTED LAGRANGE MULTIPLIER BASED OPTIMIZATION STRATEGY)
Lagrange multiplier 被广泛地用于转换等式约束问题(equality constrained problem)为一个带有适当的惩罚函数(penalty function)的无约束问题(unconstrained problem)。
首先,问题 III.9 的增广 Lagrangian 函数为:
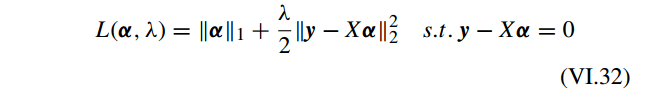
写成 Lagrangain 形式
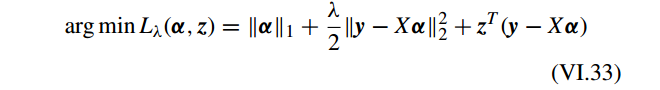
问题 VI.33 可以通过交替优化 α 和 z 获得:
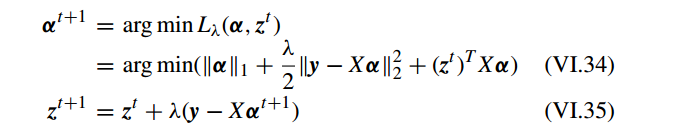
其中 问题 VI.34 可以通过 FISTA 算法求解。 问题 VI.34 是迭代求解的,参数 z 使用 等式 VI.35 来更新直到收敛。
此外,如果问题 III.9 可以通过 ALM 求解(叫做原增广Lagrangian方法 primal augmented Lagrangian method (PALM) ),那么 问题 III.9 的对偶函数(dual function)也能被 ALM 求解(叫做对偶增广Lagrangian 方法 dual augmented Lagrangian method (DALM))[89]。
下面考虑问题 III.9 的对偶优化(dual optimization):
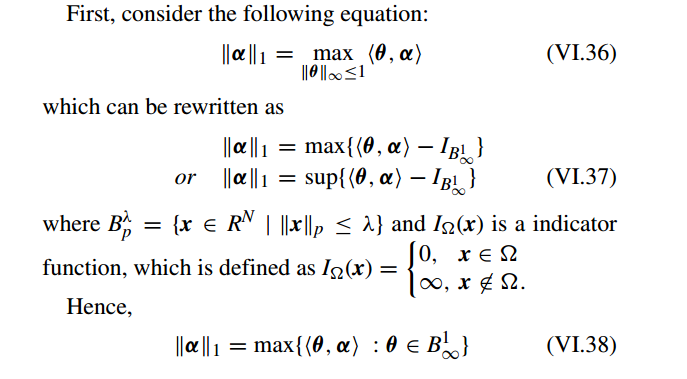

其中
µ∈Rd
是 Lagrangian 乘子 和 τ 是 惩罚参数。
最后,对偶优化问题 VI.43 可以求解
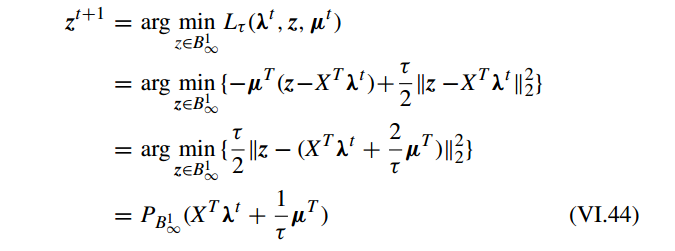
其中
PB1∞(u)
是一个
B1∞
上的投影,也叫做 group-wise soft-thresholding。
例如,让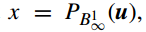
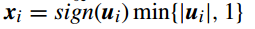
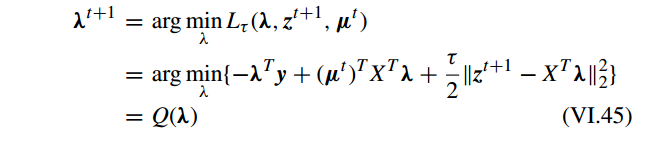
对 Q(λ) 关于 λ 求导

DALM详细见

[89] A. Y. Yang, Z. Zhou, A. G. Balasubramanian, S. S. Sastry, and Y. Ma,‘‘Fast `1-minimization algorithms for robust face recognition,’’ IEEE Trans. Image Process., vol. 22, no. 8, pp. 3234–3246, Aug. 2013.
G. 其他基于邻近算法的优化方法(OTHER PROXIMITY ALGORITHM BASED OPTIMIZATION METHODS)
邻近算法(proximity algorithm)的理论基础是首先构建一个邻近操作(proximal operator),接着使用这个邻近操作来求解凸优化问题。
[29] N. Parikh and S. Boyd, ‘‘Proximal algorithms,’’ Found. Trends Optim., vol. 1, no. 3, pp. 123–231, 2013.
VII. 基于 Homotopy 算法的稀疏表示(HOMOTOPY ALGORITHM BASED SPARSE REPRESENTATION)
The main idea of homotopy is to solve the original optimization problems by tracing a continuous parameterized path of solutions along with varying parameters.
A. Lasso Homotopy(LASSO HOMOTOPY)
B. BPDN Homotopy(BPDN HOMOTOPY)
C. Homotopy(ITERATIVE REWEIGHTING l1-NORM MINIMIZATION VIA HOMOTOPY)
D. Homotopy(OTHER HOMOTOPY ALGORITHMS FOR SPARSE REPRESENTATION)
VIII. 稀疏表示的应用(THE APPLICATIONS OF THE SPARSE REPRESENTATION METHOD)
A. 字典学习中的稀疏表示(SPARSE REPRESENTATION IN DICTIONARY LEARNING)
一个超完备字典通常有两种生成方式:1)transform domain method(预定义的一组变换函数) [5];2)dictionary learning methods(通过学习获得) [104]。两者都是转换图片样本到其他域并且学习转换系数的相似性 [105]。但是 transform domain methods 通常使用一组固定的变换函数(正交基 例如: over-complete wavelets transform , super-wavelet transform, bandelets , curvelets transform , contourlets transform and steerable wavelet filters)来表示图片样本,而 dictionary learning methods 却使用一个带有冗于信息超完备字典上的稀疏表示。transform domain methods 速度快,但 dictionary learning methods 效果好。
假设矩阵
Y=[y1,y2,⋅⋅⋅,yN]
,
X=[x1,x2,⋅⋅⋅,xN]T
和字典
D=[d1,d2,⋅⋅⋅,dM]
。从 [23], [112],字典学习的框架一般可以表示为:
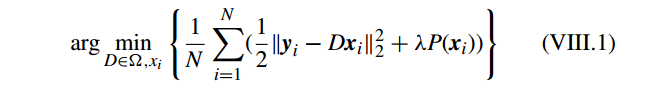
其中
Ω={D=[d1,d2,⋅⋅⋅,dM]:dTidi=1,i=1,2,⋅⋅⋅,M}
;
N
为样本数据个数(已知);
1) 无监督字典学习(UNSUPERVISED DICTIONARY LEARNING)
无监督字典学习主要用于图像压缩,图像表示的特征编码。
a: KSVD(KSVD FOR UNSUPERVISED DICTIONARY LEARNING)
KSVD 的目标函数为:
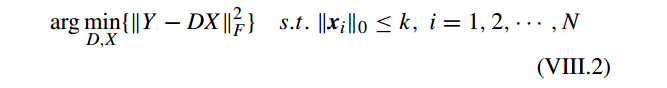
其中
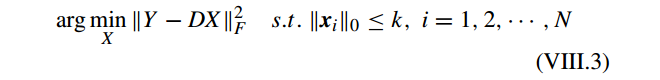
即所谓稀疏编码,它的子问题为
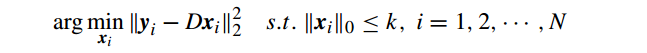
可以使用MP和 OMP 求解。接着固定 X, 问题 VIII.2 转为回归问题
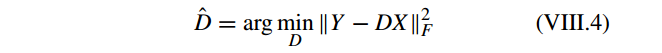
其中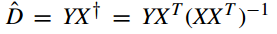
由于 VIII.4 中 求 inverse problem 的复杂度为
O(n3)
。 KSVD 重写问题 VIII.4 为
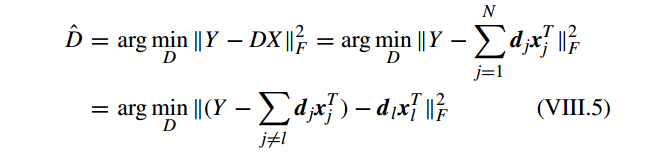
首先 计算 overall representation residual 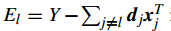
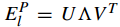
具体算法见[121]

[121] M. Aharon, M. Elad, and A. Bruckstein, ‘‘K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation,’’ IEEE Trans. Signal Process., vol. 54, no. 11, pp. 4311–4322, Nov. 2006.
b: 位置约束的线性编码(LOCALITY CONSTRAINED LINEAR CODING FOR UNSUPERVISED DICTIONARY LEARNING)
locality constrained linear coding (LLC) 算法 [129] 是一种有效的局部坐标线性编码方法,它把每个描述子(descriptor )映射到一个局部约束的系统来获得一个有效地字典。
It has been demonstrated that the property of locality is more essential than sparsity, because the locality must lead to sparsity but not vice-versa, that is, a necessary condition of sparsity is locality, but not the reverse [129].
假设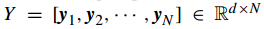
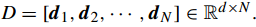
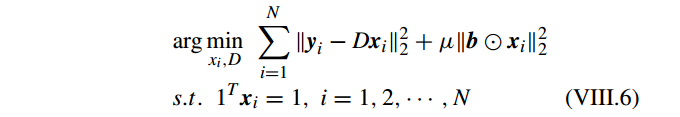
其中 正则化参数
μ
调节权重衰减速度( weighting decay speed),b 为 locality adaptor,为
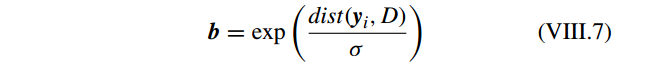
特别地,向量
b
的第 个值
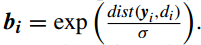
使用 k-means 产生字典 D ,接着 LLC 的解为
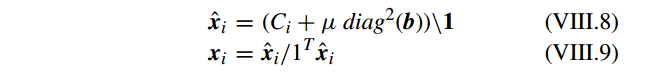
其中
a∖b
表示
a−1b
,关于
yi
的协方差矩阵(covariance matrix)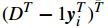
此外, incremental codebook optimization algorithm 目标函数为
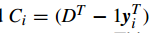
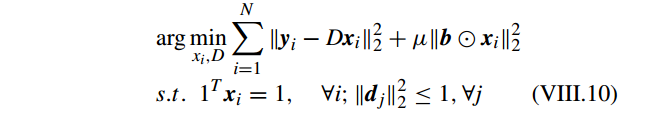
详细算法:

[129] J. Wang, J. Yang, K. Yu, F. Lv, T. Huang, and Y. Gong, ‘‘Localityconstrained linear coding for image classification,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2010, pp. 3360–3367.
c: 其他(OTHER UNSUPERVISED DICTIONARY LEARNING METHODS)
[112] J. Shi, X. Ren, G. Dai, J. Wang, and Z. Zhang, ‘‘A non-convex relaxation approach to sparse dictionary learning,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2011, pp. 1809–1816.
[117] C. Bao, H. Ji, Y. Quan, and Z. Shen, ‘‘L0 norm based dictionary learning by proximal methods with global convergence,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2014, pp. 3858–3865.
[122] R. Jenatton, J. Mairal, G. Obozinski, and F. Bach, ‘‘Proximal methods for sparse hierarchical dictionary learning,’’ in Proc. 27th Int. Conf. Mach. Learn., 2010, pp. 487–494.
[130] M. Zhou et al., ‘‘Nonparametric Bayesian dictionary learning for analysis of noisy and incomplete images,’’ IEEE Trans. Image Process., vol. 21, no. 1, pp. 130–144, Jan. 2012.
[131] I. Ramirez and G. Sapiro, ‘‘An MDL framework for sparse coding and dictionary learning,’’ IEEE Trans. Signal Process., vol. 60, no. 6, pp. 2913–2927, Jun. 2012.
[132] J. Mairal, F. Bach, J. Ponce, and G. Sapiro, ‘‘Online learning for matrix factorization and sparse coding,’’ J. Mach. Learn. Res., vol. 11, pp. 19–60, Mar. 2010.
[133] M. Yang, L. Van Gool, and L. Zhang, ‘‘Sparse variation dictionary learning for face recognition with a single training sample per person,’’ in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Dec. 2013, pp. 689–696.
2) 有监督字典学习(SUPERVISED DICTIONARY LEARNING)
a: 判别式 KSVD(DISCRIMINATIVE KSVD FOR DICTIONARY LEARNING)
Discriminative KSVD (DKSVD) [126] 主要用于图像分类问题。DKSVD 整合带有判别信息(discriminative information)的字典学习和分类器参数(classier parameters)到目标函数,然后使用 KSVD 为所有参数获得全局最优解。DKSVD 的目标函数为:
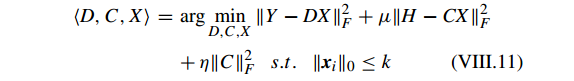
where Y is the given input samples, D is the learned dictionary, X is the coefcient term, H is the matrix composed
of label information corresponding to Y , C is the parameter
term for classier, and and are the weights.
其中 Y 是给定的输入样本,D 是学习的字典,X 是因数项,H 是对应于 Y 的标签信息组成的矩阵,C 是分类器参数,
η
和
μ
是权重。
写成 KSVD 形式:
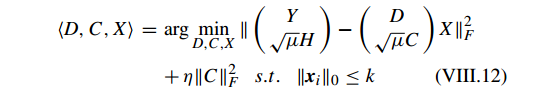
字典的每一列都归一化为 l2 范式,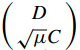
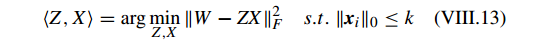
其中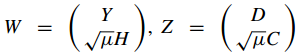
明显, VIII.13 类似于 VIII.2 的 KSVD 框架,它可以通过 KSVD 求解。
DKSVD 包含两个阶段:1)训练阶段和2)分类阶段。
1)训练阶段,Y 是训练样本组成的矩阵,目标是学习判别性的字典(discriminative dictionary) D 和 分类器参(classier parameter)C。DKSVD 逐列更新 Z,对于每一列
zi
,DKSVD 使用 KSVD 获得
zi
及其对应的权重。然后 DKSVD 归一化 字典 D 和分类器参数 C,即
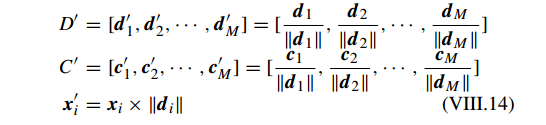
2)分类阶段, Y 是测试样本矩阵。基于获得的
D′
和
C′
,对应于每个测试样本
yi
的稀疏因子矩阵
xi
可以通过 OMP 获得
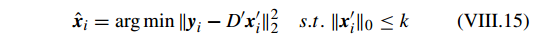
基于对应的稀疏因子
xi
,对于每个测试样本
yi
的最后分类标签为
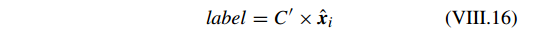
DKSVD 的亮点在于它使用 KSVD 的框架同时学习一个判别性的字典和分类器参数,然后利用 OMP 算法获得一个稀疏的解,最后使用稀疏解和学习的分类器来分类。
b: 标签一致 KSVD(LABEL CONSISTENT KSVD FOR DISCRIMINATIVE DICTIONARY LEARNING)
label consistent KSVD (LC-KSVD) [134], [135] 整合 构建字典的过程和优化线性分类器到混合重建的(reconstructive )和判别的(discriminative )目标函数中,然后联合获得学习的字典和有效的分类器。
LC-KSVD 的目标函数为:
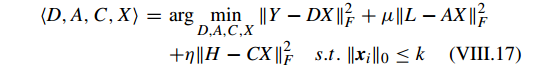
其中第一项为重建误差(reconstruction error)项,第二项为判别稀疏编码误差(discriminative sparse-code error)项,第三项为分类误差( classication error)项。Y 是输入数据矩阵,D 为学习的字典,X 为稀疏编码项,
η
和
μ
分别为权重,A 为线性变换矩阵(linear transformation matrix),H 为对应于 Y 的标签信息(label information)矩阵,C 为分类器参数,L 为关于 Y 和 D 的标签的 联合标签矩阵(joint label matrix)。例如,假设
Y=[y1...y4]
,
D=[d1...d4]
,其中
y1
,
y2
和
d1
,
d2
来自第一类,
y3
,
y4
和
d3
,
d4
来自第二类,则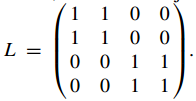
写成 KSVD 形式
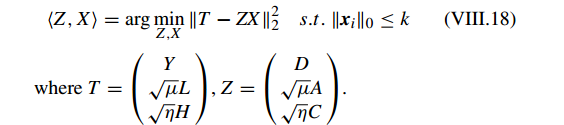
LC-KSVD 包含两个阶段:1)训练阶段和2)分类阶段。
1)训练阶段,应用 KSVD 逐个更新 Z 和计算 X。然后 LC-KSVD 归一化 字典 D ,转换矩阵 A 和分类器参数 C,即
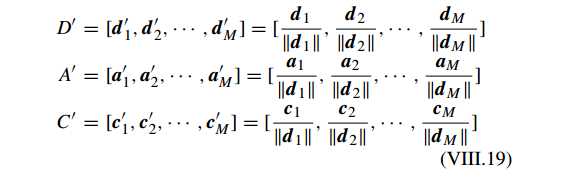
2)分类阶段, Y 是测试样本矩阵。基于获得的
D′
和
C′
,对应于每个测试样本
yi
的稀疏因子矩阵
xi
可以通过 OMP 获得
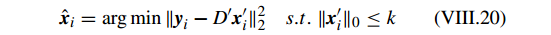
基于对应的稀疏因子
xi
,对于每个测试样本
yi
的最后分类标签为
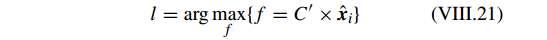
[134] Z. Jiang, Z. Lin, and L. S. Davis, ‘Learning a discriminative dictionary for sparse coding via label consistent K-SVD,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2011, pp. 16971704.
[135] Z. Jiang, Z. Lin, and L. S. Davis, “Label consistent K-SVD: Learning a discriminative dictionary for recognition,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 11, pp. 26512664, Nov. 2013
c: Fisher 判别式(FISHER DISCRIMINATION DICTIONARY LEARNING FOR SPARSE REPRESENTATION)
Fisher discrimination dictionary learning (FDDL) [136] 整合监督(类标签信息)信息和 Fisher 判别信息到目标函数中来学习一个结构化的判别性字典。FDDL 的一般模型为:
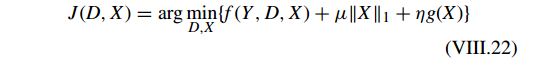
第一项为判别精确项(discriminative fidelity term),第二项为稀疏正则化项(sparse regularization term),第三项为判别因数项(discriminative coeffcient term),例如 Fisher discrimination criterion in Eq. (VIII.23)。
FDDL 分别逐类(class by class)更新字典和计算稀疏表示解。
Yi
为输入数据的第 i 类,
Xi
为,
Yij
为对应于稀疏表示矩阵。
因此 FDDL 的目标函数为:
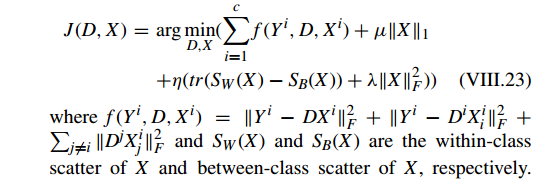
c 为类的数量。交替求解 VIII.23。
固定 D,问题 VIII.23 可以通过逐类(class by class)计算
Xi
获得,它的 sub-problem 为
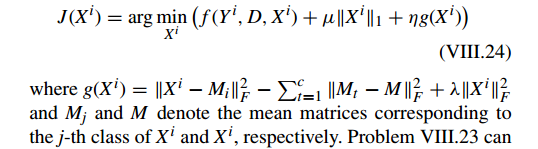
固定
α
,问题 VIII.23 可以写为
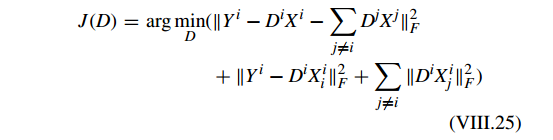
其中
Xi
表示
Y
在
FDDL 的主要贡献在于整合 Fisher discrimination criterion 到字典学习过程中。使用问题 VIII.22 中的函数 f 构建判别性的字典和同时通过探索问题 VIII.22 中的函数 g 形成判别性的稀疏表示因数。
[136] M. Yang, L. Zhang, X. Feng, and D. Zhang, `Fisher discrimination dictionary learning for sparse representation,” in Proc. IEEE Int. Conf. Comput. Vis., Nov. 2011, pp. 543550.
[138] M. Yang, L. Zhang, J. Yang, and D. Zhang, “Metaface learning for sparse representation based face recognition,” in Proc. IEEE Int. Conf. Image Process. (ICIP), Sep. 2010, pp. 16011604.
B. 图像处理中的稀疏表示(SPARSE REPRESENTATION IN IMAGE PROCESSING)
C. 图像分类和视觉跟踪中的稀疏表示(SPARSE REPRESENTATION IN IMAGE CLASSIFICATION AND VISUAL TRACKING)
IX. 实验评价(EXPERIMENTAL EVALUATION)
A. 参数选择(PARAMETER SELECTION)
Parameter selection, especially selection of the regularization parameter in different minimization problems, plays an important role in sparse representation. In order to make fair comparisons with different sparse representation algorithms, performing the optimal parameter selection for different sparse representation algorithms on different datasets is advisable and indispensable.
B. 实验结果(EXPERIMENTAL RESULTS)
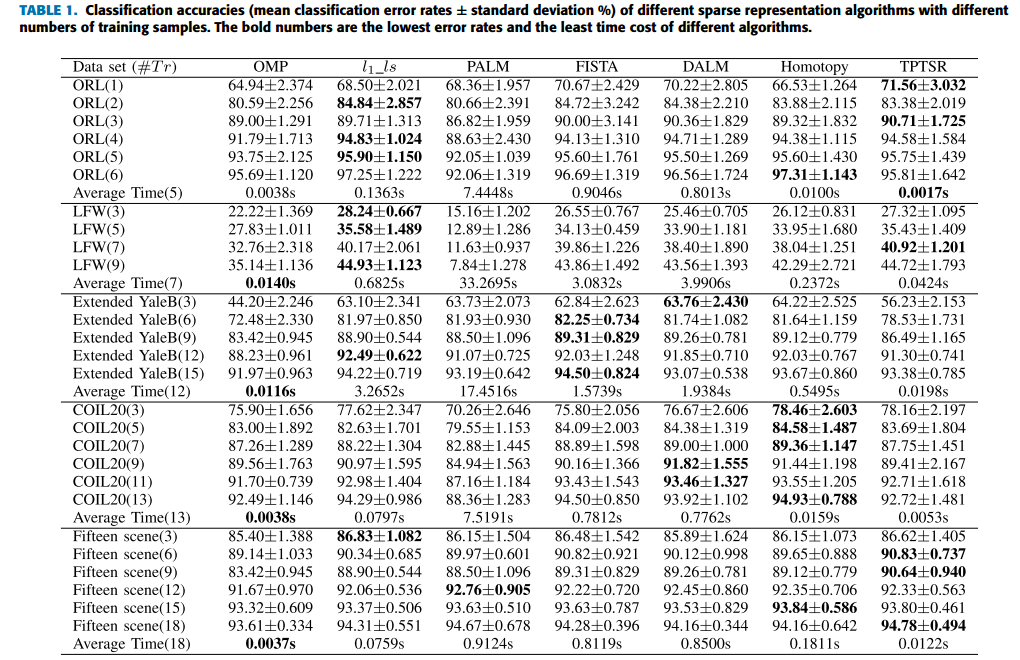
计算精度:
- l1_ls 算法在 ORL 数据集上多数情况下可以获得较好的分类结果;
- TPTSR 计算更有效,结果接接近其他算法。
计算效率:
OMP 和 TPTSR 明显比其他基于 l1 的算法要快(使用 least squares technique 而不是迭代)。
C. 讨论(DISCUSSION)
- 选择一个合适的正则化参数仍然有很长的路,基于自适应参数(adaptive parameter selection)的方法还很少;
- 精度和鲁棒性仍需提高;
- 基于 l1 范式最小化的稀疏表示的速率还有进一步发展空间(由于迭代);
- 还不存在绝对的算法能在所有数据集上效果好。
X. 结论(CONCLUSION)
- effcient sparse representation, robust sparse representation, and dictionary learning based on sparse representation 是当前的主流研究方向。
- low-rank representation 的数学理论不太elegant,整合sparse representation 和 low-rank 值得考虑。
- 稀疏表示还没有完全应用到迁移学习(transfer learning)框架。
- 有效性(effectiveness),效率(fciency )和鲁棒性(robustness)要进一步加强;
- 稀疏表示可以进一步应用到 event detection, scene reconstruction, video tracking, object recognition, object pose estimation, medical image processing, genetic expression and natural language processing等领域;
- 除了 l2-norm 和 l1-norm,基于 l2;1-norm 的稀疏表示(sparse representation)和字典学习(dictionary learning)也需要进一步研究。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)