机器学习C6笔记:正则化文本回归(交叉验证,正则化,lasso)
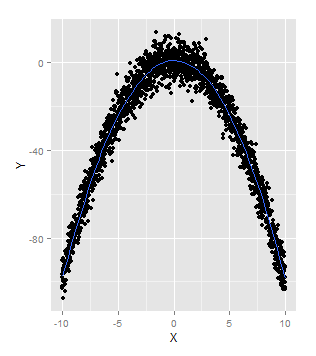
非线性模型广义加性模型Generalized Additive Model (GAM)同过使用ggplot2程序包中的geom_smooth函数,使用默认的smooth函数,就可以拟合GAM模型:set.seed(1)x <- seq(-10, 10, by = 0.01)y <- 1 - x ^ 2 + rnorm(length(x), 0, 5)ggplot(data.frame(X = x,
非线性模型
广义加性模型
Generalized Additive Model (GAM)同过使用ggplot2程序包中的geom_smooth函数,使用默认的smooth函数,就可以拟合GAM模型:
set.seed(1)
x <- seq(-10, 10, by = 0.01)
y <- 1 - x ^ 2 + rnorm(length(x), 0, 5)
ggplot(data.frame(X = x, Y = y), aes(x = X, y = Y)) +
geom_point() +
geom_smooth(se = FALSE)
避免过拟合的方法
过拟合是指: 一个模型拟合了部分噪声,而不是真正数据.
一个模型的好坏取决于它能否准确预测未来的未知数据. 若没有未来的数据,一种变通的方法是: 可以把过去的数据分为两部分,用其中一份拟合模型, 用另一份数据模拟”将来的”数据.
交叉验证
交叉验证的核心思想, 就是在模型拟合的过程中并不适用全部的历史数据,而是保留了一部分数据,用来模拟未来的数据,对模型进行检验.
ex. 利用正弦波数据来演示通过交叉验证来帮助选择多项式回归的次数.
1. 创建正弦波数据
# Twelfth code snippet
set.seed(1)
x <- seq(0, 1, by = 0.01)
y <- sin(2 * pi * x) + rnorm(length(x), 0, 0.1)- 随机抽样避免系统性差异
随机拆分训练集和测试集, 避免有系统性差异, 比如: 你可能拿较小的x来训练,而拿较大的x来测试. 利用R语言的sample函数可以提供随机性,他可以从一个给定的向量中进行随机采样. - 利用RMSE度量效果
# Fourteenth code snippet
rmse <- function(y, h)
{
return(sqrt(mean((y - h) ^ 2)))
}- 进行1-12次回归计算RMSE
# Fifteenth code snippet
performance <- data.frame()
for (d in 1:12)
{
poly.fit <- lm(Y ~ poly(X, degree = d), data = training.df)
performance <- rbind(performance,
data.frame(Degree = d,
Data = 'Training',
RMSE = rmse(training.y, predict(poly.fit))))
performance <- rbind(performance,
data.frame(Degree = d,
Data = 'Test',
RMSE = rmse(test.y, predict(poly.fit,
newdata = test.df))))
}
# Sixteenth code snippet
ggplot(performance, aes(x = Degree, y = RMSE, linetype = Data)) +
geom_point() +
geom_line()
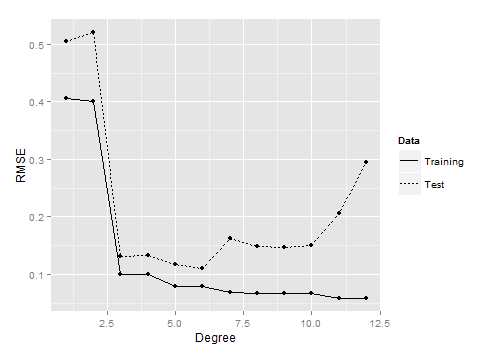
从上图可以看到,中间大小的次数对应的模型在测试数据上表现最好.
一方面,当次数过低,如1或2时,模型没有能拟合到真正的模式, 训练集和测试集的效果都非常差. 当一个模型过于简单, 以致连训练数据都拟合不够好是,称之为欠拟合(underfitting).
另一方面, 次数太大,如11或12时, 可以看到模型在测试,数据上的表现又开始变差了. 这是因为模型变得太复杂, 拟合了在测试数据中并不存在的而在训练数据中存在的噪音.
当模型开始拟合训练数据中的噪音时,就称之为发生了过拟合.
可以从另一个角度理解过拟合: 随着次数不断增加, 训练误差和测试误差变化趋势开始不一致了—训练误差持续变小,而测试误差变大. 模型对于它没见过的数据都没有泛化能力—导致了过拟合.
正则化避免过拟合
使用glmnet程序包, 参考网址:数据铺子(很棒的小铺,有许多r语言的文章)
The Elements of
Statistical Learning
摘录其中的glmnet包的讲解:
glmnet包和算法
glmnet包是关于Lasso and elastic-net regularized generalized linear models。 作者是Friedman, J., Hastie, T. and Tibshirani, R这三位。
这个包采用的算法是循环坐标下降法(cyclical coordinate descent),处理的模型包括 linear regression,logistic and multinomial regression models, poisson regression 和 the Cox model,用到的正则化方法就是l1范数(lasso)、l2范数(岭回归)和它们的混合 (elastic net)。
坐标下降法是关于lasso的一种快速计算方法(是目前关于lasso最快的计算方法),其基本要点为: 对每一个参数在保持其它参数固定的情况下进行优化,循环,直到系数稳定为止。这个计算是在lambda的格点值上进行的。
例子:
产生数据
# Twenty-first code snippet
set.seed(1)
x <- seq(0, 1, by = 0.01)
y <- sin(2 * pi * x) + rnorm(length(x), 0, 0.1)
n <- length(x)
indices <- sort(sample(1:n, round(0.5 * n)))
training.x <- x[indices]
training.y <- y[indices]
test.x <- x[-indices]
test.y <- y[-indices]
df <- data.frame(X = x, Y = y)
training.df <- data.frame(X = training.x, Y = training.y)
test.df <- data.frame(X = test.x, Y = test.y)
rmse <- function(y, h)
{
return(sqrt(mean((y - h) ^ 2)))
}进行glmnet回归
library('glmnet')
glmnet.fit <- with(training.df, glmnet(poly(X, degree = 10), Y))> glmnet.fit
Call: glmnet(x = poly(X, degree = 10), y = Y)
Df %Dev Lambda
[1,] 0 0.0000 0.569600
[2,] 1 0.1125 0.519000
[3,] 1 0.2060 0.472900
[4,] 1 0.2836 0.430900
[5,] 1 0.3480 0.392600
...
[60,] 8 0.9906 0.002354
[61,] 8 0.9906 0.002145
[62,] 8 0.9907 0.001954
[63,] 8 0.9907 0.001780
[64,] 8 0.9907 0.001622列表中最靠前的是glmnet函数执行最强正则化的结果,最靠后的是glmnet函数执行最弱正则化的结果.
df: 表示模型中的非零权重有几个.但并包括截距项,它不应该正则化.
dev: 是指R方的值, 最后一行是直接使用lm函数时得到的r方值是一样的,因为lm没用使用任何正则化, 介于完全正则化和完全正则化的两个极端之间的模型dev值介于11%~99%之间.
lambda:在第7章详解.直观的概念是: lambda很大,说明对模型的复杂度很在意, 对模型施加很大的”惩罚”, 这个惩罚将迫使所有的模型权重趋向于0; 反之, lambda很小, 说明对模型的复杂度不关心, 对模型的复杂度不怎么”惩罚”. 在极端情况下, 我们可以把lambda设为0, 就会得到一个完全没有正则化的线性回归模型,就像直接使用lm函数得到的模型一样.
寻找最优lambda的方法: 可以用交叉验证.
交叉验证
对lambda进行循环, 求RMSE.
lambdas <- glmnet.fit$lambda
performance <- data.frame()
for (lambda in lambdas)
{
performance <- rbind(performance,
RMSE = rmse(test.y,
with(test.df,
predict(glmnet.fit,
poly(X, degree = 10),s = lambda)))))# 利用测试数据在不同lambda不同的情况下进行计算RMSE
}画图
# Twenty-third code snippet
ggplot(performance, aes(x = Lambda, y = RMSE)) +
geom_point() +
geom_line()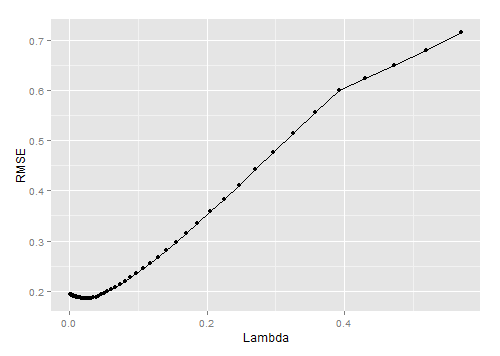
从上图可以看出lambda=0.05时, 模型效果最好.
利用最优lambda训练全部模型
# Twenty-fourth code snippet
best.lambda <- with(performance, Lambda[which(RMSE == min(RMSE))])
glmnet.fit <- with(df, glmnet(poly(X, degree = 10), Y))
# Twenty-fifth code snippet
coef(glmnet.fit, s = best.lambda)> coef(glmnet.fit, s = best.lambda)
11 x 1 sparse Matrix of class "dgCMatrix"
1
(Intercept) 0.0101667
1 -5.2132586
2 .
3 4.1759498
4 .
5 -0.4643476
6 .
7 .
8 .
9 .
10 . 从结果中看到, 虽然有10个特征可供选择, 但实际上我们只是使用了3个.这正是正则化背后的主要思想: 宁愿选择像这样比较简单的模型,也不选择复杂的模型.
参考书籍:机器学习实用案例解析

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)