
[Java基础要义]HashMap、LinkedHashMap元素遍历机制探讨
Map作为键值对Entry的的容器,对其内部 键值对Entry 的遍历总归是要有一个顺序的。 本文重点讨论HashMap及其子类LinkedHashMap的遍历机制,总结出两者的特点和适用情况。1.HashMap的遍历机制 HashMap提供了两个遍历访问其内部元素Entry的接口: 1. Set
Map作为键值对Entry<K,V>的的容器,对其内部 键值对Entry<K,V> 的遍历总归是要有一个顺序的。
本文重点讨论HashMap及其子类LinkedHashMap的遍历机制,总结出两者的特点和适用情况。
1.HashMap的遍历机制
HashMap 提供了两个遍历访问其内部元素Entry<k,v>的接口:
1. Set<Map.Entry<K,V>> entrySet() 返回此映射所包含的映射关系的 Set 视图。
2. Set<K> keySet() 返回此映射中所包含的键的 Set 视图。
实际上,第二个借口表示的Key的顺序,和第一个接口返回的Entry顺序是对应的,也就是说:这两种接口对HashMap的元素遍历的顺序相相同的。 那么,HashMap遍历内部Entry<K,V> 的顺序是什么呢? 搞清楚这个问题,先要知道其内部结构是怎样的。
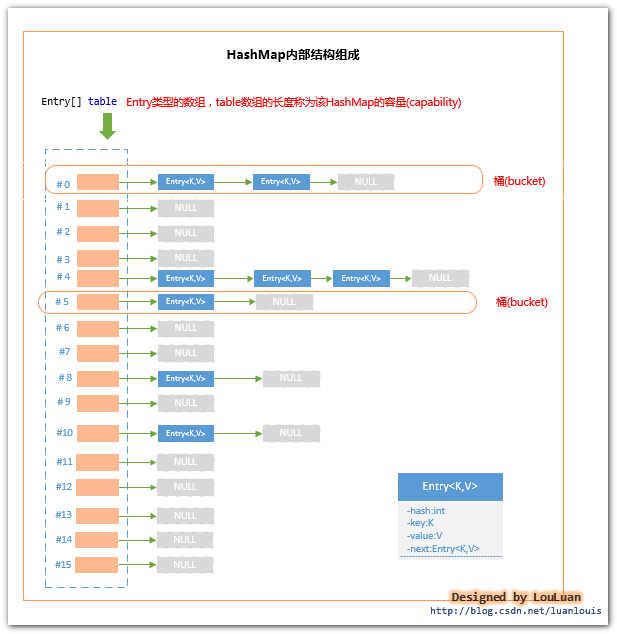
HashMap内部对键值对的存储结构使用的是数组+链表的形式。其结构如下图所示:
HashMap内部Entry<K,V>的遍历顺序:
对Entry[] table 数组,从index=0开始,依次遍历table[i] 上的链表上的Entry对象。
由于HashMap在存储Entry对象的时候,是根据Key的hash值判定存储到Entry[] table数组的哪一个索引值表示的链表上,所以笼统地说就是:使用hashMap.put(Key key,Value value)会将 对应的Entry<Key,Value>对象随机地分配到某个Entry[] table数组的元素表示的链表上。换一句话说就是:
对HashMap遍历Entry对象的顺序和Entry对象的存储顺序之间没有任何关系。
但是,我们有时候想要遍历HashMap的元素Entry的顺序和其存储的顺序一致,HashMap显然不能满足条件了。而LinkedHashMap则可以满足这个需要。
2. LinkedHashMap 的遍历机制
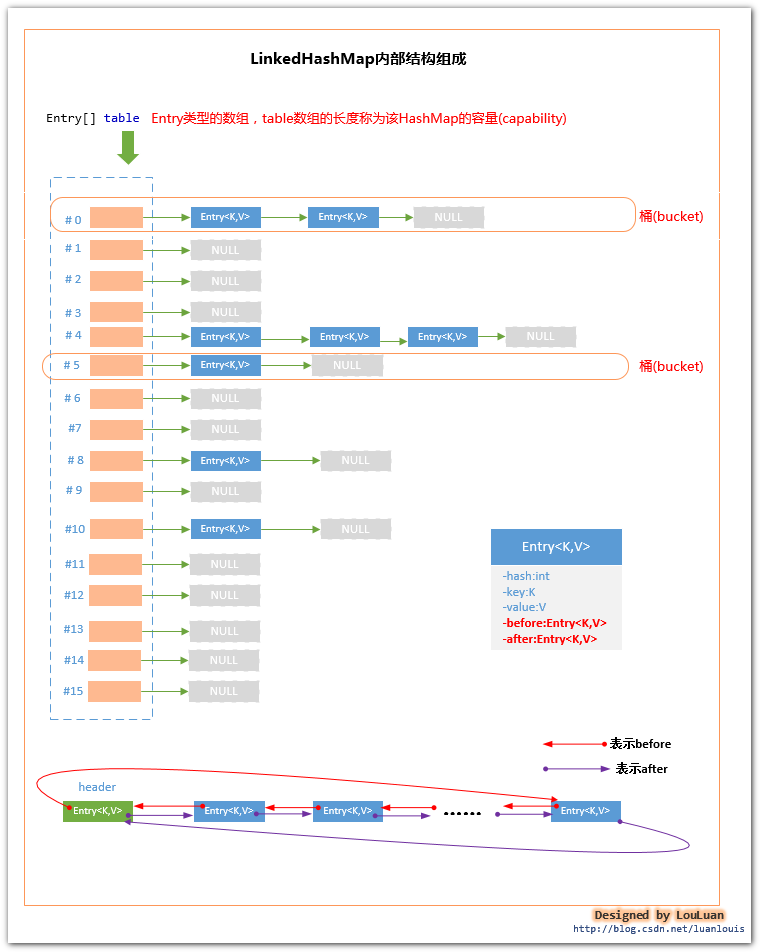
LinkedHashMap 是HashMap的子类,它可以实现对容器内Entry的存储顺序和对Entry的遍历顺序保持一致。
为了实现这个功能,LinkedHashMap内部使用了一个Entry类型的双向链表,用这个双向链表记录Entry的存储顺序。当需要对该Map进行遍历的时候,实际上是遍历的是这个双向链表。
LinkedHashMap内部使用的LinkedHashMap.Entry类继承自 Map.Ent ry类,在其基础上增加了LinkedHashMap.Entry类型的两个字段,用来引用该Entry在双向链表中的前面的Entry对象和后面的Entry对象。
它的内部会在 Map.Entry 类的基础上,增加两个Entry类型的引用:before,after。LinkedHashMap使用一个双向连表,将其内部所有的Entry串起来。
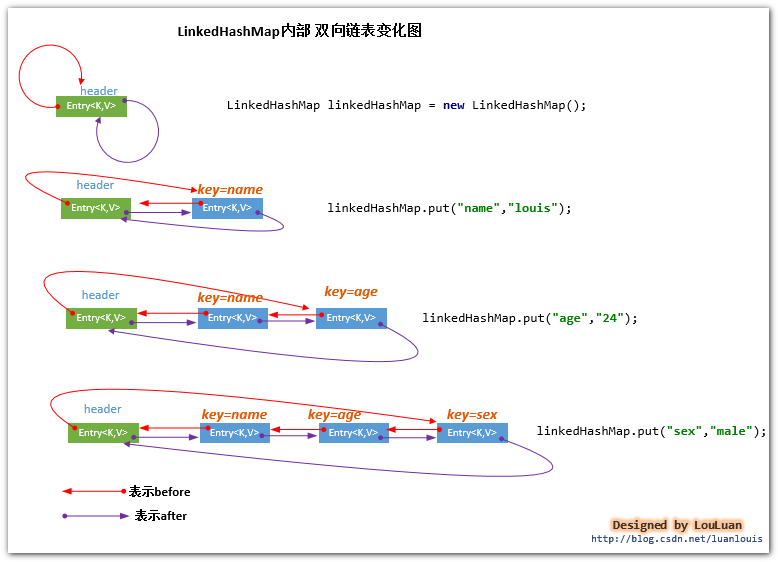
我们将通过以下例子,来了解内部双向链表是怎样构造的:
LinkedHashMap linkedHashMap = new LinkedHashMap(); linkedHashMap.put("name","louis"); linkedHashMap.put("age","24"); linkedHashMap.put("sex","male");上述的代码除了会将对应的Entry对象放置到在Entry[] table 表示的数组链表中外,还会将该Entry对象添加到其内部维护的双向链表中。对应的LinkedHashMap内部的双向链表变化如下:
对LinkedHashMap进行遍历的策略:
从 header.after 指向的Entry对象开始,然后一直沿着此链表 遍历下去,直到某个entry.after == header 为止,完成遍历。
由此,就可以保证遍历LinkedHashMap内元素的顺序,就是Entry插入到LinkedHashMap中的顺序。
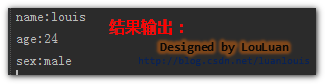
将上面代码中定义的linkedHashMap 遍历输出,会发现遍历的顺序跟插入的顺序完全一致:
结果输出:Iterator<Map.Entry> iterator= linkedHashMap.entrySet().iterator(); while(iterator.hasNext()) { Map.Entry entry = iterator.next(); System.out.println(entry.getKey()+":"+entry.getValue()); }
根据Entry<K,V>插入LinkedHashMap的顺序进行遍历的方式叫做:按插入顺序遍历。
另外,LinkedHashMap还支持一种遍历顺序,叫做:Get读取顺序。
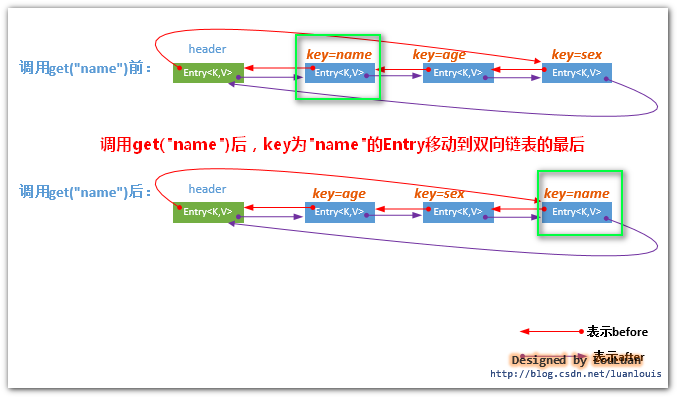
如果LinkedHashMap的这个Get读取遍历顺序开启,那么,当我们在LinkedHashMap上调用get(key) 方法时,会导致内部 key对应的Entry在双向链表中的位置移动到双向链表的最后。
比如,如果当前LinkedHashMap内部的双向链表的情况如下:
相关代码如下:
//默认情况下LinkedHashMap的遍历模式是插入模式,如果想显式地指定为get读取模式,那么要将 //其构造方法的参数置为true,(false 表示的是插入模式) LinkedHashMap linkedHashMap = new LinkedHashMap(16, (float) 0.75,true); linkedHashMap.put("name","louis"); linkedHashMap.put("age","24"); linkedHashMap.put("sex","male"); linkedHashMap.get("name");//get()方法调用,导致对应的entry移动到双向链表的最后位置 Iterator<Map.Entry> iterator= linkedHashMap.entrySet().iterator(); while(iterator.hasNext()) { Map.Entry entry = iterator.next(); System.out.println(entry.getKey()+":"+entry.getValue()); }
3. 总结
1.HashMap对元素的遍历顺序跟Entry插入的顺序无关,而LinkedHashMap对元素的遍历顺序可以跟Entry<K,V>插入的顺序保持一致。
2.当LinkedHashMap处于Get获取顺序遍历模式下,当执行get() 操作时,会将对应的Entry<k,v>移到遍历的最后位置。
3.LinkedHashMap处于按插入顺序遍历的模式下,如果新插入的<key,value> 对应的key已经存在,对应的Entry在遍历顺序中的位置并不会改变。
4. 除了遍历顺序外,其他特性HashMap和LinkedHashMap基本相同。

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)