
Zookeeper源码分析之leader选举
zookeeper默认选举算法为FastLeaderElection.java,其主要方法为FastLeaderElection.lookForLeader,选举的结果保存在类Vote中源码分析LOOKING转载请注明原文链接:http://blog.csdn.net/odailidong/article/details/41855613
·
zookeeper提供顺序一致性、原子性、统一视图、可靠性保证服务
zookeeper使用的是zab(atomic broadcast protocol)协议而非paxos协议
zookeeper能处理并发地处理多个客户端的写请求,并且以FIFO顺序commit这些写操作,zab采用了一个事务ID来实现事务的全局有序性,
在Zab协议的实现时,分为三个阶段:
1、 Leader Election
2、 Recovery Phase
3、 Broadcast Phase
今天就先分析选举算法的源码实现
2.sendNotifications();向所有的node发送notification消息,其主方法:
4.如果收到回应消息,则检查回应应状态,回应状态有以下四种:LOOKING、OBSERVING、FOLLOWING、LEADING
5.下面分析最核心的LOOKING状态:
zookeeper的leader算法类似于公民选举,每一个节点(选民),他们都有自己的推荐人(自己)。谁更适合成为leader有一个简单的规则,例如zxid(数据新)、sid/myid(服务编号大)。每个选民都告诉其他选民自己目前的推荐人是谁,当选民发现有比自己更适合的人时就转而推荐这个更适合的人。最后,过半数人意见一致时,就可以结束选举。当然,如果大多数人已经选举出了leader,那剩下的选民(无论是否参与投票)就只能接受已经选出的leader。
watch注意事项
1.Zookeeper客户端可以在znode上设置Watch。znode发生的变化会触发watch然后清除watch。当一个watch被触发,Zookeeper给客户端发送一个通知,当ZooKeeper客户端断开和服务器的连接,直到重新连接上这段时间你都收不到任何通知。如果你正在监视znode是否存在,那么你在断开连接期间收不到它创建和销毁的通知。
zookeeper使用的是zab(atomic broadcast protocol)协议而非paxos协议
zookeeper能处理并发地处理多个客户端的写请求,并且以FIFO顺序commit这些写操作,zab采用了一个事务ID来实现事务的全局有序性,
在Zab协议的实现时,分为三个阶段:
1、 Leader Election
2、 Recovery Phase
3、 Broadcast Phase
今天就先分析选举算法的源码实现
zookeeper默认选举算法为FastLeaderElection.java。其主要方法为FastLeaderElection.lookForLeader,该接口是一个同步接口,直到选举结束才会返回。选举的结果保存在类Vote中
选举整体过程主要流程可概括为下图:
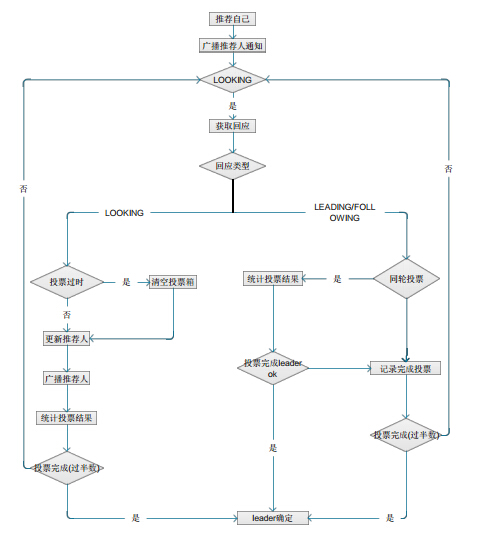
来看源码实现
1.//首先logicalclock自增, 在这里logicalclock表示本次选举的id,逻辑时钟的值,这个值从0开始递增,每次选举对应一个值,如果在同一次选举中,这个值是一样的,逻辑时钟值越大,说明该节点上的这一次选举leader的进程更加新
- synchronized(this){
- logicalclock++;
- //如果自己不是OBSERVER,则投给自己
- updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
- }
2.sendNotifications();向所有的node发送notification消息,其主方法:
- ToSend notmsg = new ToSend(ToSend.mType.notification,proposedLeader, proposedZxid,logicalclock,QuorumPeer.ServerState.LOOKING,sid,proposedEpoch);
- 消息格式:
- mType type 消息类型
- long leader 推荐的leader的id,就是配置文件中写好的每个服务器的id
- long zxid 推荐的leader的zxid,zookeeper中的每份数据,都有一个对应的zxid值,越新的数据,zxid值就越大
- long epoch, logicalclock
- ServerState state, 本节点的状态
- long sid 本节点的 id,即myid
3.当该节点的状态为LOOKING且没有stop时,就一直loop到选出leader为止
- //从消息队列中接收消息
- Notification n = recvqueue.poll(notTimeout, TimeUnit.MILLISECONDS);
- //如没有接收到消息,则检查manager.haveDelivered(),如果已经全部发送出去了,就继续发送,一直到选出leader为止。否则就重新连接。
- if(manager.haveDelivered()){
- sendNotifications();
- } else {
- manager.connectAll();
- }
- int tmpTimeOut = notTimeout*2;//延长超时时间
- notTimeout = (tmpTimeOut < maxNotificationInterval? tmpTimeOut : maxNotificationInterval);
4.如果收到回应消息,则检查回应应状态,回应状态有以下四种:LOOKING、OBSERVING、FOLLOWING、LEADING
5.下面分析最核心的LOOKING状态:
- case LOOKING:
- // If notification > current, replace and send messages out
- if (n.electionEpoch > logicalclock) {//该节点的epoch大于 logicalclock,表示当前新一轮的选举
- logicalclock = n.electionEpoch;//更新本地的logicalclock
- recvset.clear();//清空接收队列recvset
- //调用totalOrderPredicate决定是否更新自己的投票,依次比较选举轮数epoch,事务zxid,服务器编号server id(myid)
- if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
- updateProposal(n.leader, n.zxid, n.peerEpoch);//把投票修改为对方的
- } else {
- updateProposal(getInitId(),getInitLastLoggedZxid(), getPeerEpoch());
- }
- sendNotifications();//广播消息
- } else if (n.electionEpoch < logicalclock) {//如果该节点的epoch小于logicalclock,则忽略
- break;
- } else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,proposedLeader, proposedZxid, proposedEpoch)) {
- updateProposal(n.leader, n.zxid, n.peerEpoch);
- sendNotifications();
- }
- recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));//把从该节点的信息发到recvset中,表明已经收到该节点的回应
- //通过termPredicate函数判断recvset是否已经达到法定quorum,默认超过半数就通过
- if (termPredicate(recvset, new Vote(proposedLeader, proposedZxid, logicalclock, proposedEpoch))) {
- // Verify if there is any change in the proposed leader
- while((n = recvqueue.poll(finalizeWait, TimeUnit.MILLISECONDS)) != null){//循环,一直等新的notification到达,直到超时
- if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)){
- recvqueue.put(n);
- break;
- }
- }
- if (n == null) {//确定leader
- self.setPeerState((proposedLeader == self.getId()) ?ServerState.LEADING: learningState());
- Vote endVote = new Vote(proposedLeader, proposedZxid, proposedEpoch);
- leaveInstance(endVote);//清空接收队列
- return endVote;
- }
- }
- /*
- *
- * 返回true说明需要更新数据
- * We return true if one of the following three cases hold:
- * 1- New epoch is higher
- * 2- New epoch is the same as current epoch, but new zxid is higher
- * 3- New epoch is the same as current epoch, new zxid is the same
- * as current zxid, but server id is higher.
- */
- protected boolean totalOrderPredicate(long newId, long newZxid, long newEpoch, long curId, long curZxid, long curEpoch) {
- ...
- return ((newEpoch > curEpoch) || ((newEpoch == curEpoch) && ((newZxid > curZxid) || ((newZxid == curZxid) && (newId > curId)))));
- }
zookeeper的leader算法类似于公民选举,每一个节点(选民),他们都有自己的推荐人(自己)。谁更适合成为leader有一个简单的规则,例如zxid(数据新)、sid/myid(服务编号大)。每个选民都告诉其他选民自己目前的推荐人是谁,当选民发现有比自己更适合的人时就转而推荐这个更适合的人。最后,过半数人意见一致时,就可以结束选举。当然,如果大多数人已经选举出了leader,那剩下的选民(无论是否参与投票)就只能接受已经选出的leader。
watch注意事项
1.Zookeeper客户端可以在znode上设置Watch。znode发生的变化会触发watch然后清除watch。当一个watch被触发,Zookeeper给客户端发送一个通知,当ZooKeeper客户端断开和服务器的连接,直到重新连接上这段时间你都收不到任何通知。如果你正在监视znode是否存在,那么你在断开连接期间收不到它创建和销毁的通知。
2.Zookeeper的客户端和服务会检查确保每个znode上的数据小于1M,因为Zookeeper为了提供高吞吐量,保存到内存里的数据量不宜过多
转载请注明来源:http://blog.csdn.net/odailidong/article/details/41855613

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐



 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)