[Hibernate Search] (3) 基础查询
基础查询目前我们只用到了基于关键字的查询,实际上Hibenrate Search DSL还提供了其它的查询方式,下面我们就来一探究竟。映射API和查询API对于映射API,我们可以通过使用Hibernate提供的注解来完成映射工作,同时我们也可以使用JPA提供的注解来完成。类似的,对于查询API,我们也可以从Hibernate和JPA提供的查询API中进行选择。每种方式都有
基础查询
目前我们只用到了基于关键字的查询,实际上Hibenrate Search DSL还提供了其它的查询方式,下面我们就来一探究竟。
映射API和查询API
对于映射API,我们可以通过使用Hibernate提供的注解来完成映射工作,同时我们也可以使用JPA提供的注解来完成。类似的,对于查询API,我们也可以从Hibernate和JPA提供的查询API中进行选择。每种方式都有它的优点和缺点,比如当我们使用Hibernate提供的查询API时,意味着可以使用更多的特性,毕竟Hibernate Search就是建立在Hibernate之上的。而当我们选择JPA的查询API时,意味着应用可以更方便的切换ORM的实现,比如我们想将Hibernate替换成EclipseLink。
Hibernate Search DSL
所谓的Hibernate Search DSL,实际上就是用于编写查询代码的一些列API:
import org.hibernate.search.query.dsl.QueryBuilder;
// ...
String searchString = request.getParameter("searchString");
QueryBuilder queryBuilder = fullTextSession.getSearchFactory()
.buildQueryBuilder().forEntity( App.class ).get();
org.apache.lucene.search.Query luceneQuery = queryBuilder
.keyword()
.onFields("name", "description")
.matching(searchString)
.createQuery();
它采用链式编程的方式将查询中关键的部分封装成一个个方法进行连续调用。当下,很多API都被设计成这样。比如jQuery的API,以及Java 8中最新的Stream类型的API等。同时,一些设计模式如建造者模式也大量地使用了这种技术。
关键字查询(Keyword Query)
基于关键字的查询,是最为基本的一种查询方式。目前见到的例子都是基于关键字查询的。 为了执行这种查询,第一步是得到一个QueryBuilder对象,并且说明需要查询的目标实体:
QueryBuilder queryBuilder = fullTextSession.getSearchFactory().buildQueryBuilder()
.forEntity(App.class).get();
下图反映了在创建关键字查询时可能的流程:
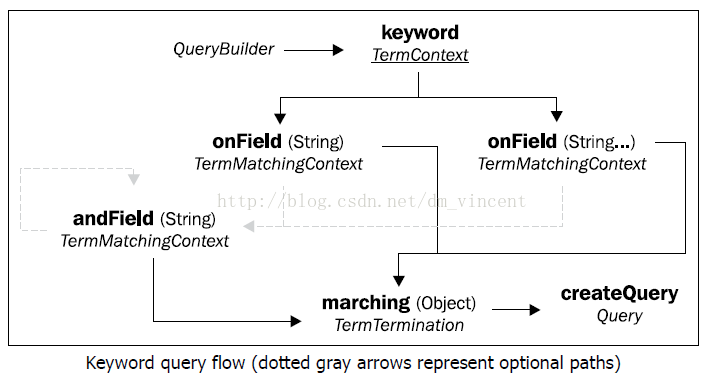
反映到代码中是这样的:
org.apache.lucene.search.Query luceneQuery = queryBuilder
.keyword()
.onFields("name", "description", "supportedDevices.name", "customerReviews.comments")
.matching(searchString)
.createQuery();
onFields方法可以看做是多个onField方法的组合,为了方便一次性地声明所有查询域。 如果onFields中接受的某个域在对应实体的索引中不存在相关信息,那么查询会报错。所以,需要确保传入到onFields方法中的域确实是存在于实体的索引中的。
对于matching方法,通常而言它需要接受的是一个字符串对象,表示查询的关键字。但是实际上借助FieldBridge,传入到该方法的参数可以是任意类型。在“高级映射”一文中会对FieldBridge进行介绍。
对于传入的关键字字符串,它也许包含了多个关键字(使用空白字符分隔,就像我们使用搜索引擎时)。Hibernate Search会默认地将它们分割成一个个的关键字,然后逐个进行搜索。
最终,createQuery方法会结束DSL的定义并返回一个Lucene查询对象。最后,我们可以通过FullTextSession(Hibernate)或者FullTextEntityManager(JPA)来得到最终的Hibernate Search查询对象(FullTextQuery):
FullTextQuery hibernateQuery =
fullTextSession.createFullTextQuery(luceneQuery, App.class);
模糊查询(Fuzzy Query)
当我们使用搜索引擎时,它都能够很“聪明”地对一些输入错误进行更正。而在Hibernate Search中,我们也可以通过模糊查询来让查询更加智能。
当使用了模糊查询后,当关键字和目标字串之间的匹配程度低于设置的某个阈值时,Hibernate Search也会认为匹配成功而返回结果。这个阈值的范围在0和1之间:0代表任何字串都算匹配,而1则代表只有完全符合才算匹配。所以当这个阈值取了0和1之间的某个值时,就代表查询能够支持某种程度的模糊。
当使用Hibernate Search DSL来定义模糊查询时,可能的流程如下:
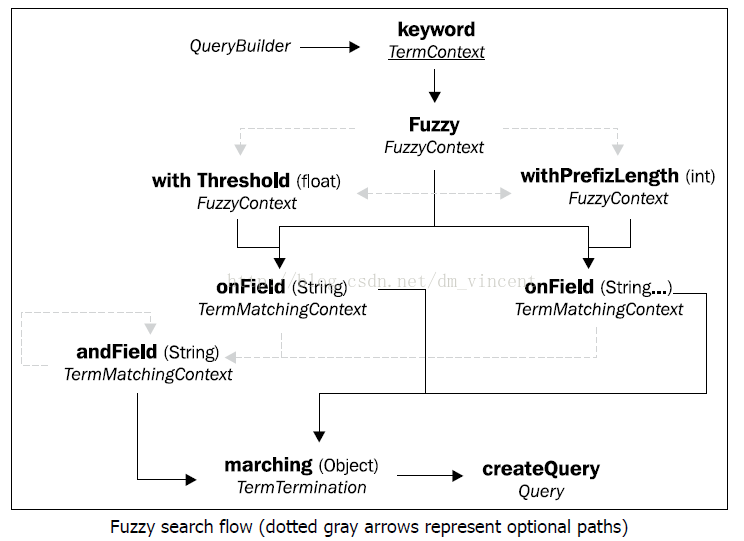
它一开始使用的也是keyword方法来定义一个基于关键字的查询,毕竟模糊查询也只是关键字查询的一种。 它在最后也会使用onField/onFields来指定查询的目标字段。
只不过在keyword和onField/onFields方法中间会定义模糊查询的相关参数。
fuzzy方法会使用0.5作为模糊程度的默认值,越接近0就越模糊,越接近1就越精确。因此,这个值是一个折中的值,在多种环境中都能够通用。
如果不想使用该默认值,还可以通过调用withThreshold方法来指定一个阈值:
luceneQuery = queryBuilder
.keyword()
.fuzzy()
.withThreshold(0.7f)
.onFields("name", "description", "supportedDevices.name", "customerReviews.comments")
.matching(searchString)
.createQuery();
除了withThreshold方法外,还可以使用withPrefixLength方法来指定每个词语中,前多少个字符需要被排除在模糊计算中。
通配符查询(Wildcard Query)
在通配符查询中,问号(?)会被当做一个任意字符。而星号(*)则会被当做零个或者多个字符。
在Hibernate Search DSL中使用通配符搜索的流程如下:
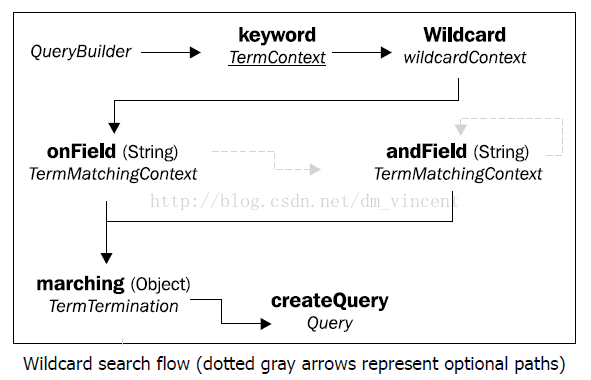
需要使用wildcard方法来指定它是一个支持通配符的查询。
精确短语查询(Exact Phrase Query)
前面提到过,Hibernate Search会在执行查询前将关键字使用空白字符进行分割,然后对得到的词语逐个查询。然而,有时候我们需要查询的就是一个完整的短语,不需要Hibernate Search多此一举。在搜索引擎中,我们通过使用双引号来表示这种情况。
在Hibernate Search DSL中,可以通过短语查询来完成,一下是流程图:
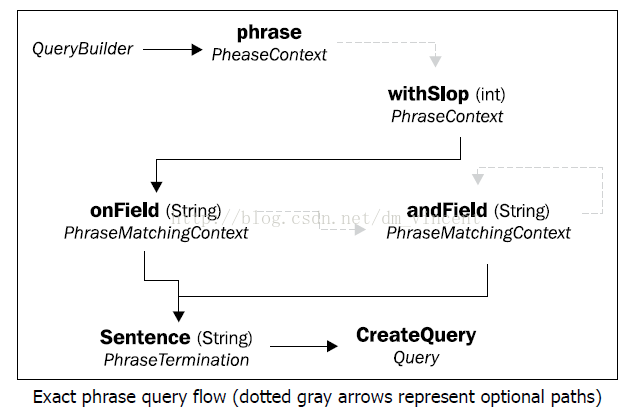
sentence方法接受的参数必须是一个String类型,这一点和matching有所不同。 withSlop方法接受一个整型变量作为参数,它提供了一种原始的模糊查询方式:短语中额外可以出现的词语数量。比如我们要查询的是“Hello World”,那么在使用withSlop(1)后,“Hello Big World”也会被匹配。
那么在具体的代码中,我们可以首先进行判断,如果搜索字符串被引号包含了,那么就使用短语查询:
if(isQuoted(searchString)) {
luceneQuery = queryBuilder
.phrase()
.onField("name")
.andField("description")
.andField("supportedDevices.name")
.andField("customerReviews.comments")
.sentence(searchStringWithQuotesRemoved)
.createQuery();
}
范围查询(Range Query)
范围查询的流程:
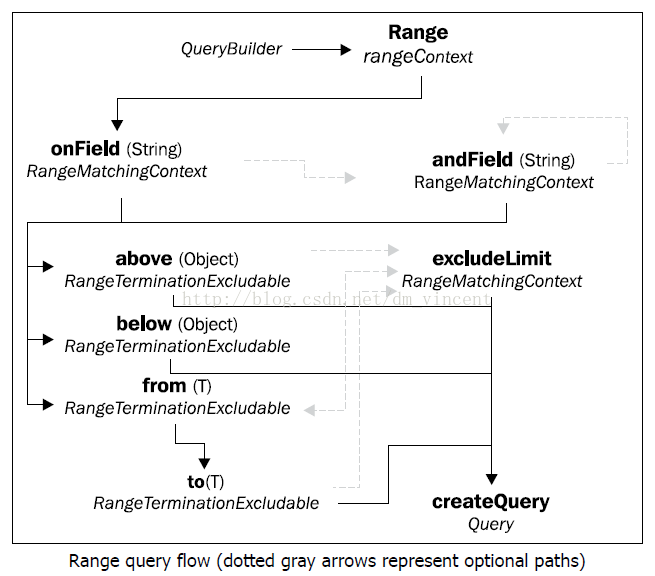
顾名思义,范围查询通过给定上限值和下限值来对某些域进行的查询。 因此,日期类型和数值类型通常会作为此类查询的目标域。
above,below方法用来单独指定下限值和上限值。而from和to方法必须成对使用。 它们可以结合excludeLimit来将区间从闭区间转换为开区间:
比如from(5).to(10).excludeLimit()所代表的区间就是:5 <= x < 10。
下面是一个查询拥有4星及以上评价的App实体:
luceneQuery = queryBuilder
.range()
.onField("customerReviews.stars")
.above(3).excludeLimit()
.createQuery();
布尔(组合)查询(Boolean(Combination) Query)
如果一个查询满足不了你的需求,那么你可以使用布尔查询将若干个查询结合起来。下面是它的流程:
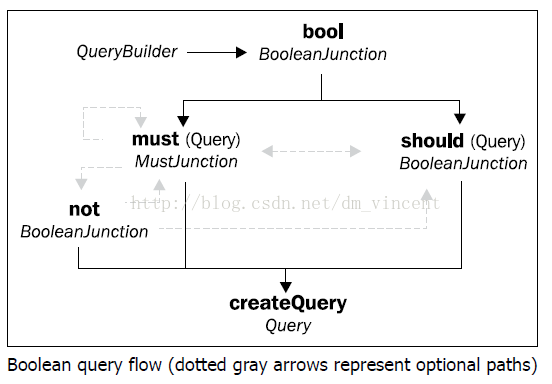
使用bool方法来表明这个查询是一个组合查询,会组合多个子查询。它至少需要包含一个must子查询或者一个should查询。must和should分别表示的是逻辑与(Logical-AND)和逻辑或(Logical-OR)的语义。
一般,不要同时使用must和should,因为这会让should中的查询毫无意义。只有在需要根据相关度对结果的排序进行调整时,才会将must和should联合使用。
比如,下述代码用来查询支持设备xPhone并且拥有5星评价的App实体:
luceneQuery = queryBuilder
.bool()
.must(
queryBuilder
.keyword()
.onField("supportedDevices.name")
.matching("xphone")
.createQuery()
)
.must(
queryBuilder
.range()
.onField("customerReviews.stars")
.above(5)
.createQuery()
)
.createQuery();
排序(Sorting)
默认情况下,查询结果应该按照其和查询条件间的相关度进行排序。关于相关度排序,会在后续的文章中介绍。
但是我们也能够不再使用相关度作为排序的依据,转而我们可以使用日期,数值类型甚至字符串的顺序作为排序依据。比如,对App的搜索结果,我们可以使用其名字在字母表中的顺序进行排序。
为了支持对于某个域的排序,我们需要向索引中添加一些必要的信息。在对字符串类型的域进行索引时,默认的分析器会将该域的值进行分词,所以对于某个值“Hello World”,在索引中会有两个入口对“Hello”和“World”进行单独保存。这样做能够让查询更具效率,但是当我们需要对该域进行排序时,分词器是不需要的。
因此,我们可以对该域设置两个@Field注解:
@Column
@Fields({
@Field,
@Field(name="sorting_name", analyze=Analyze.NO)
})
private String name;
一个用来建立标准的索引,一个用来建立用于排序的索引,其中指定了analyze=Analyze.NO,默认情况下分词器是被使用的。
这个域就可以被用来创建Lucene的SortField对象,并集合FullTextQuery使用:
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.SortField;
// ...
Sort sort = new Sort(new SortField("sorting_name", SortField.STRING));
hibernateQuery.setSort(sort); // a FullTextQuery object
执行此查询后,得到的结果会按照App名字,从A-Z进行排序。 实际上,SortField还能够接受第三个boolean类型的参数,当传入true时,排序结果会被颠倒即从Z-A。
分页(Pagination)
当搜索会返回大量结果时,通常都不可能将它们一次性返回,而是使用分页技术一次只返回并显示一部分数据。
对于Hibernate Search的FullTextQuery对象,可以使用如下代码完成分页:
hibernateQuery.setFirstResult(10);
hibernateQuery.setMaxResults(5);
List<App> apps = hibernateQuery.list();
setFirstResult指定的是偏移量,它通常是通过 页码(从0开始) * 一页中的记录数 计算得到。比如以上代码中的10实际上就是 2 * 5,因此它透露出来的信息是:显示第3页的5条数据。
而为了得到查询的结果数量,可以通过getResultSize方法获得:
int resultSize = hibernateQuery.getResultSize();
在使用getResultSize方法时,不涉及到任何的数据库操作,它仅仅通过Lucene索引来得到结果。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)