特征变换以及维度下降——Linear Discriminant Analysis(二)
线性判别分析(Linear discriminant analysis, LDA),是一种监督学习算法,也叫做Fisher线性判别(Fisher Linear Discriminant, FLD),是模式识别的经典算法,它是在1996年由Belhumeur引入模式识别和人工智能领域的。
4.Linear Discriminant Analysis(多类情况)
前面是针对只有两个类的情况,假设类别变成多个,要如何改变才能保证投影后类别能够分离呢?
我们之前讨论的是如何将d维降到一维,现在类别多了,一维可能已经不能满足要求。假设我们有C个类别,需要K维向量(或者叫做基向量)来做投影。
将这K为向量表示为:
我们将样本点在这K维向量投影后结果表示为![]() ,有以下公式成立
,有以下公式成立
![]() (1)
(1)
![]() (2)
(2)
为了像上节一样度量J(w),我们打算仍然从类间散列度和类内散列度来考虑。
样本是二维时,我们从几何意义上考虑:
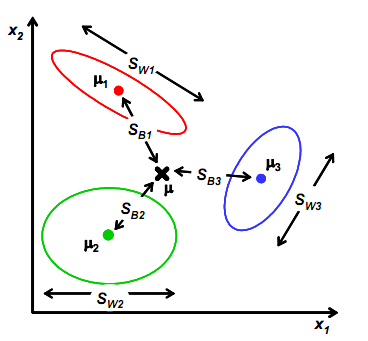
其中![]() 和
和![]() 与上节的意义一样,
与上节的意义一样,![]() 是类别1里的样本点相对于该类中心点
是类别1里的样本点相对于该类中心点![]() 的散列程度。
的散列程度。![]() 变成类别1中心点相对于样本中心点
变成类别1中心点相对于样本中心点![]() 的协方差矩阵,即类1相对于
的协方差矩阵,即类1相对于![]() 的散列程度。
的散列程度。
![]() 的计算基本不用变化:
的计算基本不用变化:
 (3)
(3)
![]() 的计算公式不变,仍然类似于类内部样本点的协方差矩阵
的计算公式不变,仍然类似于类内部样本点的协方差矩阵
 (4)
(4)
但是, ![]() 需要变,原来度量的是两个均值点的散列情况,现在度量的是每类均值点相对于样本中心的散列情况。类似于将
需要变,原来度量的是两个均值点的散列情况,现在度量的是每类均值点相对于样本中心的散列情况。类似于将![]() 看作样本点,
看作样本点,![]() 是均值的协方差矩阵,如果某类里面的样本点较多,那么其权重稍大,权重用Ni/N表示,但由于J(w)对倍数不敏感,因此使用Ni。
是均值的协方差矩阵,如果某类里面的样本点较多,那么其权重稍大,权重用Ni/N表示,但由于J(w)对倍数不敏感,因此使用Ni。
 (5)
(5)
其中
 (6)
(6)
![]() 是所有样本的均值。
是所有样本的均值。
上面讨论的都是在投影前的公式变化,但真正的J(w)的分子分母都是在投影后计算的。下面我们看样本点投影后的公式改变:
这两个是第i类样本点在某基向量上投影后的均值计算公式。
 (7)
(7)
 (8)
(8)
下面两个是在某基向量上投影后的![]() 和
和![]()
 (9)
(9)
 (10)
(10)
其实就是将![]() 换成了
换成了![]() 。
。
综合各个投影向量(w)上的![]() 和
和![]() ,更新这两个参数,得到
,更新这两个参数,得到
![]() (11)
(11)
![]() (12)
(12)
W是基向量矩阵,![]() 是投影后的各个类内部的散列矩阵之和,
是投影后的各个类内部的散列矩阵之和,![]() 是投影后各个类中心相对于全样本中心投影的散列矩阵之和。
是投影后各个类中心相对于全样本中心投影的散列矩阵之和。
回想我们上节的公式J(w),分子是两类中心距,分母是每个类自己的散列度。现在投影方向是多维了(好几条直线),分子需要做一些改变,我们不是求两两样本中心距之和(这个对描述类别间的分散程度没有用),而是求每类中心相对于全样本中心的散列度之和。
然而,最后的J(w)的形式是
 (13)
(13)
由于得到的分子分母都是散列矩阵,要将矩阵变成实数,需要取行列式。又因为行列式的值实际上是矩阵特征值的积,一个特征值可以表示在该特征向量上的发散程度。因此我们使用行列式来计算。
整个问题又回归为求J(w)的最大值了,我们固定分母为1,然后求导,得出最后结果。
![]() (14)
(14)
与上节得出的结论一样
![]() (15)
(15)
最后还归结到了求矩阵的特征值上来了。首先求出![]() 的特征值,然后取前K个特征向量组成W矩阵即可。
的特征值,然后取前K个特征向量组成W矩阵即可。
注意:由于![]() 中的
中的![]() 秩为1,因此
秩为1,因此![]() 的秩至多为C(矩阵的秩小于等于各个相加矩阵的秩的和)。由于知道了前C-1个
的秩至多为C(矩阵的秩小于等于各个相加矩阵的秩的和)。由于知道了前C-1个![]() 后,最后一个
后,最后一个![]() 可以有前面的
可以有前面的![]() 来线性表示,因此
来线性表示,因此![]() 的秩至多为C-1。那么K最大为C-1,即特征向量最多有C-1个。特征值大的对应的特征向量分割性能最好。
的秩至多为C-1。那么K最大为C-1,即特征向量最多有C-1个。特征值大的对应的特征向量分割性能最好。
由于![]() 不一定是对称阵,因此得到的K个特征向量不一定正交。
不一定是对称阵,因此得到的K个特征向量不一定正交。
(1)LDA至多可生成C-1维子空间
LDA降维后的维度区间在[1,C-1],与原始特征数n无关,对于二值分类,最多投影到1维。
(2)LDA不适合对非高斯分布样本进行降维。

上图中红色区域表示一类样本,蓝色区域表示另一类,由于是2类,所以最多投影到1维上。不管在直线上怎么投影,都难使红色点和蓝色点内部凝聚,类间分离。
(3)LDA在样本分类信息依赖方差而不是均值时,效果不好。

上图中,样本点依靠方差信息进行分类,而不是均值信息。LDA不能够进行有效分类,因为LDA过度依靠均值信息。
(4)LDA可能过度拟合数据。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)