
9、多智能体强化学习入门VDN、QMIX、CW_QMIX、OW_QMIX、QTRAN、ATT_QMIX、SA-IA-QMIX复现demo
在上一篇博客中,我们探讨了 MADDPG。当面对动作空间较小且完全离散的协作任务(如星际争霸 SMAC、Combat 5v5)时,基于策略梯度的算法在搜索效率上往往不如基于值函数(Value-Based)的算法。
在上一篇博客中,我们探讨了 MADDPG。当面对动作空间较小且完全离散的协作任务(如星际争霸 SMAC、Combat 5v5)时,基于策略梯度的算法在搜索效率上往往不如基于值函数(Value-Based)的算法。
- 今天,我们要正式踏入 MARL中最经典、在离散动作协作任务中胜率极高的流派:基于值函数(Value-Based)的价值分解算法家族。这其中包括了VDN、QMIX,以及它们的改进版CW_QMIX、OW_QMIX、QTRAN 和 ATT_QMIX以及SA-IA-QMIX。
1. 基于值函数的方法核心痛点
在多智能体协作中,如果把团队获得的总奖励直接平分给每个人,就会出现“吃大锅饭”现象——努力输出的得不到正反馈,划水的跟着混分。
- 这被称为信用分配 (Credit Assignment) 问题。
为了解决这个问题,研究者在 CTDE(中心化训练,去中心化执行) 框架下提出了价值分解:
-
构建一个网络,把全局的联合 QQQ 值(QtotQ_{tot}Qtot),合理拆解成每个智能体自己的局部 QQQ 值(QiQ_iQi)。
-
这其中有一个所有价值分解算法都必须遵守的数学圣经——IGM (Individual-Global-Max) 原理:
argmaxaQtot(τ,a)=(argmaxa1Q1(τ1,a1),…,argmaxanQn(τn,an))\arg\max_{\mathbf{a}} Q_{tot}(\boldsymbol{\tau}, \mathbf{a}) = \left( \arg\max_{a_1} Q_1(\tau_1, a_1), \dots, \arg\max_{a_n} Q_n(\tau_n, a_n) \right)argamaxQtot(τ,a)=(arga1maxQ1(τ1,a1),…,arganmaxQn(τn,an))一句话解释:只要保证每个智能体选出自己局部 QQQ 值最大的动作,拼在一起刚好就是能让团队总 QQQ 值最大的联合动作。
2. 基于值函数的价值分解算法原理及公式
2.1 VDN (Value Decomposition Networks):开创性的线性加法
- 核心思路:最朴素的想法,团队总价值等于每个人的价值简单相加。
- 数学公式:Qtot(τ,u)=∑i=1nQi(τi,ui)Q_{tot}(\boldsymbol{\tau}, \mathbf{u}) = \sum_{i=1}^nQ_i(\tau_i, u_i)Qtot(τ,u)=i=1∑nQi(τi,ui)
- 痛点:只能表达线性关系。无法拟合现实中“辅助+射手”这种“1+1>2”的复杂非线性协同效应。
2.2 QMIX:一代宗师,引入单调性约束
- 核心思路:放弃简单加法,引入混合网络 (Mixing Network) 进行非线性组合。同时,为了严格满足 IGM 原理,QMIX强制要求混合网络的权重必须为正。
- 数学公式:∂Qtot∂Qi≥0,∀i\frac{\partial Q_{tot}}{\partial Q_i} \ge 0, \quad \forall i∂Qi∂Qtot≥0,∀i具体实现上,它通过一个超网络 (Hypernetworks) 接收全局状态 sss,并对其输出的权重取绝对值来保证非负。
- 痛点:单调性是个枷锁,导致模型无法处理“非单调惩罚”任务(比如两人必须同时配合才能得分,任何单方面行动都会扣分)。
2.3 QTRAN:试图打破单调性枷锁
- 核心思路:彻底放弃权重必须为正的物理限制。通过构造复杂的损失函数,引入状态价值函数 V(s)V(s)V(s)补偿差值,强行约束个体最优和全局最优对齐。
- 数学公式:∑i=1nQi(τi,ui)−Qtot(τ,u)+V(τ)≥0\sum_{i=1}^n Q_i(\tau_i, u_i) - Q_{tot}(\boldsymbol{\tau}, \mathbf{u}) + V(\boldsymbol{\tau}) \ge 0i=1∑nQi(τi,ui)−Qtot(τ,u)+V(τ)≥0
- 痛点:理论完美但工程灾难。由于约束条件过于松散,在实际训练中 Loss 极难收敛。
2.4 CW_QMIX (Centrally Weighted QMIX):关注核心动作
- 核心思路:由于 QTRAN 难收敛,学者们退回 QMIX 路线进行改良。CW_QMIX认为,没必要把所有动作组合都算准,只要把“最优动作组合”算准就行。
- 数学公式:在计算 TD Error 时引入权重函数 w(s,a)w(s, a)w(s,a):L=w(s,a)(yTD−Qmix(τ,u,s))2\mathcal{L} = w(s, a) \left(y_{TD} - Q_{mix}(\boldsymbol{\tau}, \mathbf{u}, s) \right)^2L=w(s,a)(yTD−Qmix(τ,u,s))2当评估的是中心化网络给出的最优动作时,w=1w=1w=1;否则赋予极小的权重。这能有效防止模型被垃圾动作拖累。
2.5 OW_QMIX (Optimistically Weighted QMIX):乐观的探索者
- 核心思路:与 CW_QMIX 类似,但评价标准更倾向于乐观主义,以此鼓励探索。
- 数学公式:w(s,a)={1,if yTD>Qmix(τ,u,s)α,otherwisew(s, a) = \begin{cases} 1, & \text{if } y_{TD} > Q_{mix}(\boldsymbol{\tau}, \mathbf{u}, s) \\ \alpha, & \text{otherwise} \end{cases}w(s,a)={1,α,if yTD>Qmix(τ,u,s)otherwise当目标 QQQ值大于当前估值(说明有爆分潜力)时,赋予高权重,防止算法在早期陷入局部最优。
2.6 基础架构:ATT_QMIX(标准版)—— 引入注意力机制的“战场观察家”
-
核心痛点:在原版 QMIX 中,混合网络的超网络(Hypernetworks)需要接收所有智能体状态拼接而成的全局状态 s=[s1,s2,…,sn]\mathbf{s} = [s_1, s_2, \dots, s_n]s=[s1,s2,…,sn]。在 10v10等大规模协作场景下,这种暴力的向量拼接会导致“维度爆炸”,且包含了大量无关的冗余信息。
-
核心原理:标准 ATT_QMIX 引入了自然语言处理中大杀四方的多头注意力机制 (Multi-Head Attention,MHA)。它不再生硬地拼接全局信息,而是通过动态计算智能体之间的关联权重,让模型学会“划重点”,在 Mixer层面对全局状态进行动态加权。
-
核心公式:首先,将各智能体的状态或特征提取为向量 eie_iei。通过 QQQ (Query) 和 KKK (Key) 的点积,计算智能体iii 对智能体 jjj 的注意力权重 αi,j\alpha_{i,j}αi,j:αi,j=softmaxj((WQei)(WKej)Tdk)\alpha_{i,j} = \text{softmax}_j \left( \frac{(W_Q e_i)(W_K e_j)^T}{\sqrt{d_k}} \right)αi,j=softmaxj(dk(WQei)(WKej)T)随后,根据权重聚合 VVV (Value) 信息,得到提纯后的特征 hih_ihi:hi=∑j=1nαi,j(WVej)h_i = \sum_{j=1}^n \alpha_{i,j} (W_V e_j)hi=j=1∑nαi,j(WVej)最后,超网络使用提纯后的 h=[h1,…,hn]\mathbf{h} = [h_1, \dots, h_n]h=[h1,…,hn] 生成混合网络参数并计算QtotQ_{tot}Qtot。
-
机制解读:智能体学会了在复杂战场上自动分配精力:“80%关注交火的敌人,20%关注身边的辅助,0%关注远处的挂机队友。”这极大增强了大规模场景下的泛化能力。
2.7 实战进阶:双重注意力架构 (SA-IA-QMIX)
- 在复现完经典算法后,为了挑战更复杂的目标搜索与资源采集任务,在项目中并未止步于标准的 ATT_QMIX。
- 经过对底层源码的深度改造,我采用了一种更前沿的架构:基于自注意力 (SA) 与逆注意力 (IA) 机制的改进 QMIX 算法。
2.7.1. 局部自注意力 (Self-Attention, SA):突破单体视野瓶颈
- 核心原理:传统 Agent 的 RNN 网络直接吞吐原始局部观测值 oio_ioi。在 Agent 内部强力插入了 SA模块,让智能体在决策前,先对自己复杂的局部视野进行特征提纯,并采用残差拼接思想保留底层特征。
- 数学公式:
首先,通过三个不同的线性变换生成局部的查询、键、值向量:
Qi=WQoi,Ki=WKoi,Vi=WVoiQ_i = W_Q o_i, \quad K_i = W_K o_i, \quad V_i = W_V o_iQi=WQoi,Ki=WKoi,Vi=WVoi计算自注意力输出 Zi=MHA(Qi,Ki,Vi)Z_i = \text{MHA}(Q_i, K_i, V_i)Zi=MHA(Qi,Ki,Vi)。
工程实现精髓: 算法将原始观测特征与注意力特征拼接,输入全连接层映射出局部 Q 值:Qi(oi,ai)=fθ([oi∥Zi])Q_i(o_i, a_i) = f_{\theta}([o_i \parallel Z_i])Qi(oi,ai)=fθ([oi∥Zi])(注:∥\parallel∥ 代表向量拼接)
2.7.2 逆注意力机制 (Inverse Attention, IA):理清隐式协作关系
- 核心原理:这是该架构最惊艳的“底盘级”协同设计。在混合网络(Mixer)中,算法主动评估智能体之间的两两交互关系。通过专门的逆注意力网络,精准评估协作误差,剥离无效的冗余信息,强化有价值的协同动作。
- 数学公式:将智能体 iii 和 jjj 的隐状态拼接为 hi,j=[hi∥hj]h_{i,j} = [h_i \parallel h_j]hi,j=[hi∥hj],通过两层线性网络
计算注意力打分:
scorei,j=W2ReLU(W1hi,j)\text{score}_{i,j} = W_2 \text{ReLU}(W_1 h_{i,j})scorei,j=W2ReLU(W1hi,j)随后通过带温度系数 τ\tauτ 的 Softmax 归一化得到协作权重:αi,j=softmaxj(scorei,jτ)\alpha_{i,j} = \text{softmax}_j \left( \frac{\text{score}_{i,j}}{\tau} \right)αi,j=softmaxj(τscorei,j)
2.7.3 全局注意力特征融合:抗维度爆炸
- 核心原理:最终,混合网络不再仅仅依赖原始的全局状态sss,而是将上述经过提纯的注意力特征压缩后,进行高阶融合,如同给主教练戴上了“战术透视镜”。
- 数学公式:将所有计算出的注意力权重拼接为高维特征 grawg_{raw}graw,通过一层网络压缩至低维空间:
g=ReLU(Wggraw)g = \text{ReLU}(W_g g_{raw})g=ReLU(Wggraw)最终与全局状态 sss 拼接,共同作为超网络的输入:Mixer_Input=[s∥g]\text{Mixer\_Input} = [\mathbf{s} \parallel g]Mixer_Input=[s∥g]
这种“局部 SA 提纯 + 协同 IA 过滤 + 全局特征融合”的降维打击,完美契合了复杂的协同逻辑。在多智能体博弈测试中,其对环境关键信息的捕获能力大幅提升。
本节涉及的所有**底层核心代码(Agent 网络重构、Mixer 特征融合等)**均已上传至我的 GitHub。如果你也受困于传统 QMIX的表现上限,欢迎直接 Clone 我的项目,体验前沿双重注意力的威力!
3. 伪代码和网络框架图
伪代码:
3.1 VDN (值分解网络)
算法逻辑:
- 初始化:各个智能体的局部网络 QiQ_iQi。
- 前向传播:
- 各个智能体根据局部观测 oio_ioi 输出局部价值 QiQ_iQi。
- 对所有智能体的 QiQ_iQi 进行直接求和,得到联合价值 Qtot=∑QiQ_{tot} = \sum Q_iQtot=∑Qi。
- 参数更新:
- 计算 TD 目标:y=r+γmaxa′Qtot(s′,a′;θ−)y = r + \gamma \max_{a'} Q_{tot}(s', a'; \theta^-)y=r+γmaxa′Qtot(s′,a′;θ−)。
- 通过最小化均方误差 (y−Qtot)2(y - Q_{tot})^2(y−Qtot)2 来更新所有局部网络参数。
3.2 QMIX (单调性混合网络)
算法逻辑:
- 局部计算:各智能体独立计算 QiQ_iQi。
- 超网络计算:
- 将全局状态 sss 输入超网络(Hypernetwork)。
- 超网络输出混合网络(Mixing Network)的权重 WWW 和偏置 bbb。
- 关键约束:对权重 WWW 进行绝对值处理,确保 W≥0W \ge 0W≥0。
- 非线性混合:
- 将所有 QiQ_iQi 组合成向量,通过混合网络映射得到联合价值 QtotQ_{tot}Qtot。
- 混合过程通常包含一次非线性激活(如 ELU)。
- 更新:基于全局奖励 rrr 计算 TD 误差并回传。
3.3 QTRAN (解耦分解框架)
算法逻辑:
-
网络组成:包含各智能体局部网络 QiQ_iQi、联合价值网络 QjtQ_{jt}Qjt、状态价值网络 VVV。
-
三部分损失函数计算:
- TD 损失:联合网络 QjtQ_{jt}Qjt 必须学习全局的奖励信号。
- 最优性约束:对于当前采取的最优动作组合,要求 ∑Qi−Qjt+V\sum Q_i - Q_{jt} + V∑Qi−Qjt+V 的结果趋近于 000。
- 非最优约束:对于其他动作组合,要求 ∑Qi−Qjt+V\sum Q_i - Q_{jt} + V∑Qi−Qjt+V 的结果大于或等于 000。
-
更新:同时最小化上述三个损失项。
3.4 CW-QMIX / OW-QMIX (加权混合)
算法逻辑:
- 预测与对比:计算当前联合价值 QtotQ_{tot}Qtot 与 TD 目标的差值 δ\deltaδ。
- 执行加权逻辑:
- CW-QMIX (中心加权):如果当前联合动作 a\mathbf{a}a 是预测的最优动作,则设置权重 w=1w = 1w=1;否则设置 w=αw = \alphaw=α(α<1\alpha < 1α<1)。
- OW-QMIX (乐观加权):如果误差 δ>0\delta > 0δ>0(代表当前可能低估了价值),则 w=1w = 1w=1;反之 w=αw = \alphaw=α。
- 损失更新:使用加权后的平方损失 L=w⋅δ2L = w \cdot \delta^2L=w⋅δ2。
3.5 ATT-QMIX (注意力混合)
算法逻辑:
- 特征映射:
- 将全局状态 sss 转换为查询向量 QueryQueryQuery。
- 将每个智能体的局部信息(或 QiQ_iQi)转换为键向量 KeyiKey_iKeyi 和值向量 ValueiValue_iValuei。
- 计算得分:利用 QueryQueryQuery 与 KeyiKey_iKeyi 的点积计算注意力得分,并通过 Softmax 归一化。
- 加权求和:根据得分对各智能体的贡献进行加权计算。
- 混合输出:将加权后的结果输入混合网络得到最终的 QtotQ_{tot}Qtot。
3.6 SA-IA-QMIX (情境与身份感知)
算法逻辑:
- 身份嵌入 (IA):为每个智能体分配唯一的 ID 向量(Embedding),并将其拼接到局部输入中。
- 情境感知 (SA):使用编码器从全局状态 sss 中提取当前“情境特征”。
- 增强输入:每个智能体计算 QiQ_iQi 时,输入包含:自身观测 + 身份向量 + 情境特征。
- 值分解:将增强后的 QiQ_iQi 传入 QMIX 的混合层进行全局协同学习。
3.7 网络框架图
这个是gemini nano banana 画的。如果大家要发期刊或者论文,也可以用这个工具画噢!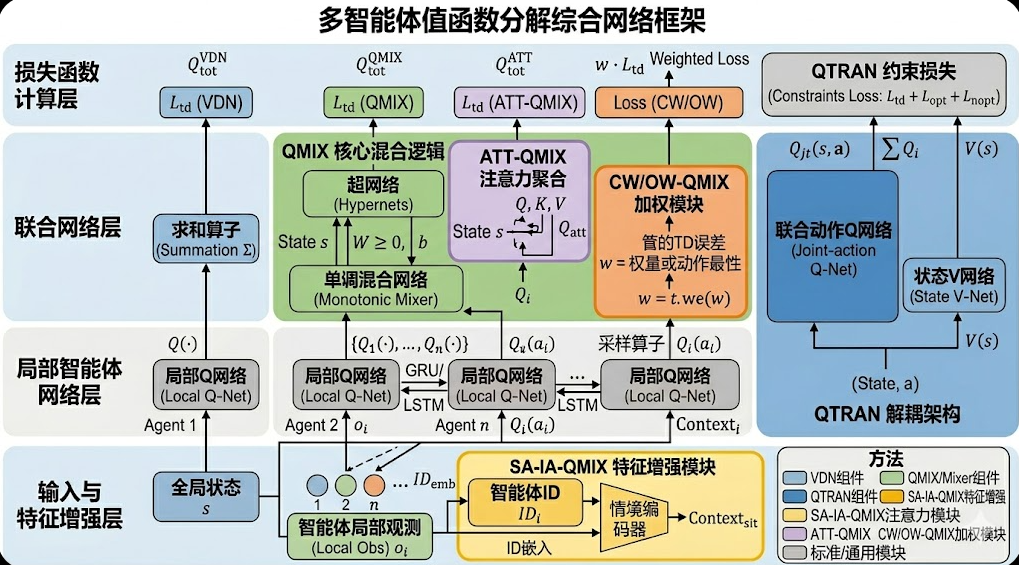
4. 复现demo
- 在简单的协作任务中,VDN的线性求和已经足够表达协作关系,反而VDN效果比其它4个方法更好。
- 复杂的非线性混合可能反而增加学习难度。
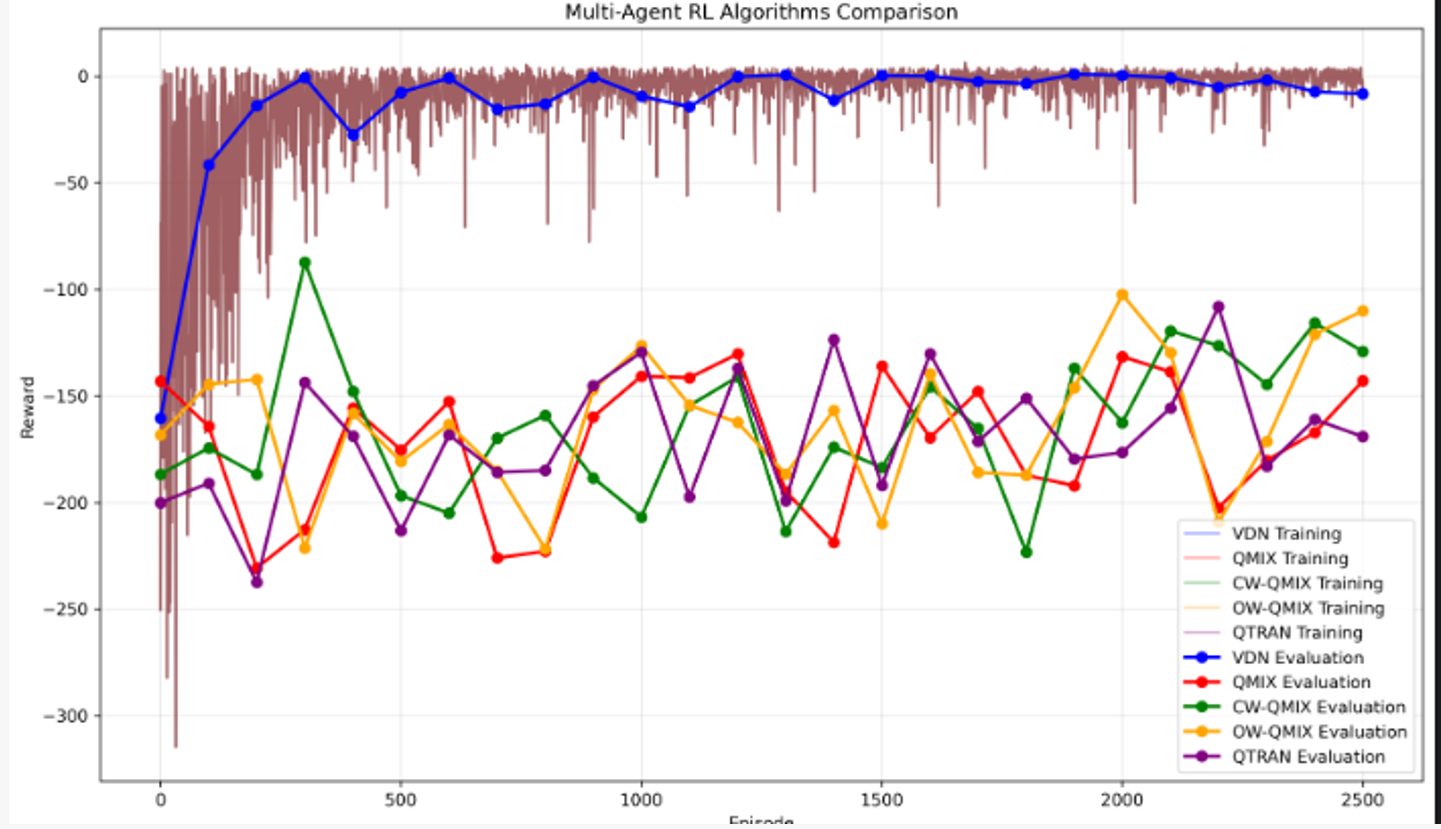
- 在这种简单任务中:VDN明显比其他方法更快达到收敛的效果。当然,上面复现的时候并没有添加ATT和SA/IA的QMIX的模块。
- 在当前实验所涉及的简单协作任务下,结构最基础、无需处理非单调关系的 VDN 算法凭借极快的收敛速度和最高的奖励值完胜其他复杂的非线性分解方法(QMIX、QTRAN 等)。
- 我们接下来换成复杂任务进行复现效果。
环境设计与实现-
资源收集环境 :创建一个多智能体资源收集任务,智能体需要合作收集环境中的资源
-
视野机制 :实现智能体的视野限制,模拟部分可观测环境(Dec-POMDP)
-
奖励机制 :设计非线性奖励结构,包括:
- 资源收集奖励
- 团队协作奖励
- 时间惩罚
- 资源清空奖励
随机展示一张类似的图像: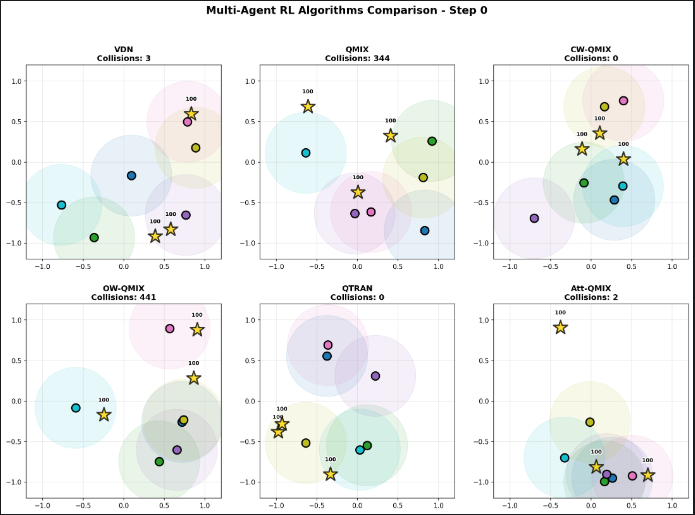
-
由于我们的环境是随机初始化的,针对每回合固定一个策略进行训练,所以每回合初始奖励对于不同方法来说肯定是一样的,然后用VDN、QMIX、CW_QMIX、OW_QMIX、QTRAN、ATT_QMIX、SA-IA-QMIX7种方法进行评估,分析优缺点,具有可比较性。
-
但是由于环境随机性比较强,所以不同回合的初始奖励不同,那么就不能把总奖励作为方法对比消融实验。
-
这里我们采取:收敛判定 = (动作一致性达标 (权重 40%) + Q 值稳定达标 (权重 30%) + 采集效率稳定 (权重 20%) + 碰撞率稳定 (权重 10%))。
-
动作一致性/动作熵 - 用 E 表示、Q 值稳定性 - 用 Q 表示、采集效率 - 用 η 或 Eff 表示、碰撞率 - 用 CR 表示。
这个改进的项目还是挺复杂的!!!
初学者经验:
- 1、刚开始训练,不要用随机性非常强的环境,要学简单的,逐层训练复杂的环境。不然一来就是随机智能体位置、随机目标位置,智能体很难学到东西!!!学会的概率为千万分之一,没有开玩笑!学强化学习的经验教训,当然,这是多智能体环境,不是单智能体环境。
- 2、上面的先学简单然后复杂,这也是很常见的手法,比如,OpenAI 在处理极其复杂的任务时,通常会采用以下三种“由简到难”的顶级策略:
阶段 1(幼儿期):瞎跑。抓捕者学会了追,躲藏者学会了逃。
阶段 2(工具期):躲藏者发现地图上有箱子,学会了推箱子把门堵死,抓捕者进不去。
阶段 3(破局期):抓捕者发现地图上有三角形的斜坡,学会了推斜坡到墙边,踩着斜坡翻墙进去抓人。
阶段 4(防守反击):躲藏者变得更聪明了,它们在游戏开局时,抢先一步把外面的斜坡偷走并锁在自己的基地里,让抓捕者无坡可用。阶段 5(卡 Bug 期):抓捕者利用了底层物理引擎的漏洞,踩在箱子上“冲浪”滑进基地。
所以我的代码分为3个阶段:
阶段 1 (简单:目标点附近出生)
轮数范围:0-2000 轮
出生策略:智能体在目标资源点周围极小范围出生(spawn_radius=0.15,约 1-2 个网格距离)
难度:最简单,智能体出生点离目标很近
阶段 2 (中等:半场范围出生)轮数范围:2000-4000 轮
出生策略:智能体出生范围线性扩大(从 0.15 线性扩大到 1.0)
难度:中等,出生范围逐渐扩大
阶段 3 (困难:全图随机出生)轮数范围:4000 轮以后
出生策略:智能体在全图范围内随机出生(spawn_radius=1.0)
难度:最困难(地狱难度),智能体需要在全图范围内寻找资源 这三个阶段通过逐步增加出生范围的难度,帮助智能体从简单场景开始学习,逐渐适应更复杂的环境。
4.1 加改进的训练效果:
4.1.1 改进后的收集率效果
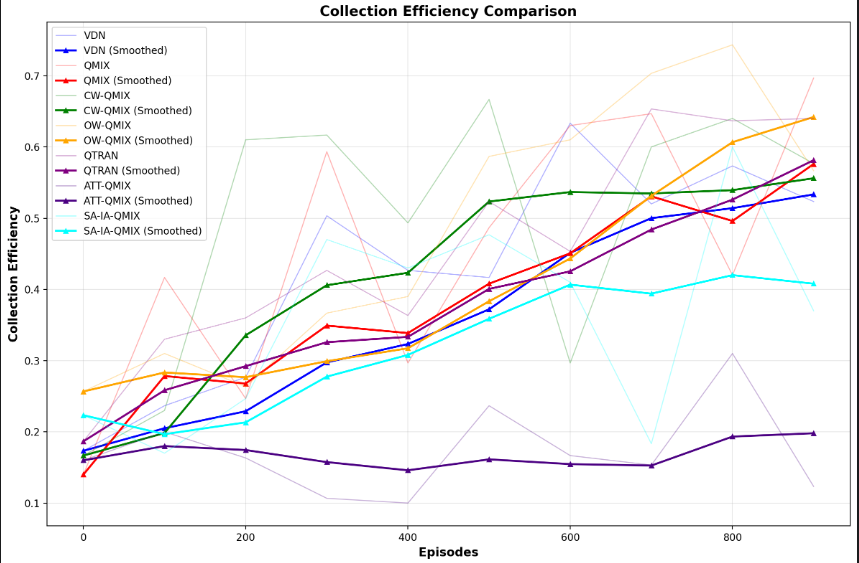
- 在上面明显可以看出,资源点收集率上升的趋势很明显。
- 上面的图片效果并不是阶段1的训练结果,而是由阶段1训练后的策略进行评估验证的效果,在评估阶段,采取智能体在全图范围内随机出生,这恰恰说明我们的想法是正确的,由简到难的策略,智能体是能学到东西的!
- 阶段1(智能体在目标资源点周围极小范围出生)的训练结果能够促进评估阶段(智能体在全图范围内随机出生)的上升趋势!
4.1.2 改进后的碰撞率效果
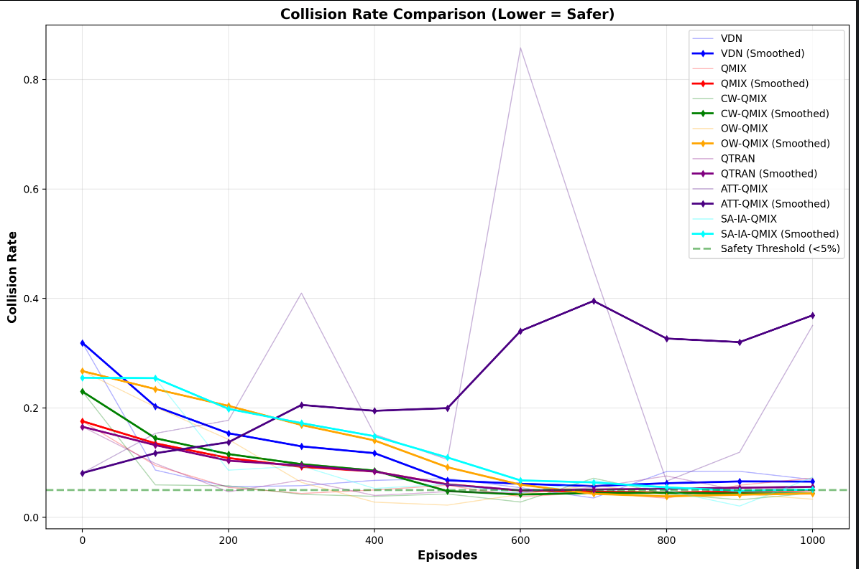
- 这同样是评估效果。4.1.1中大部分解释过概念了,图片中看得出大部分方法的碰撞率是下降趋势!
4.1.3 训练阶段1的碰撞率效果
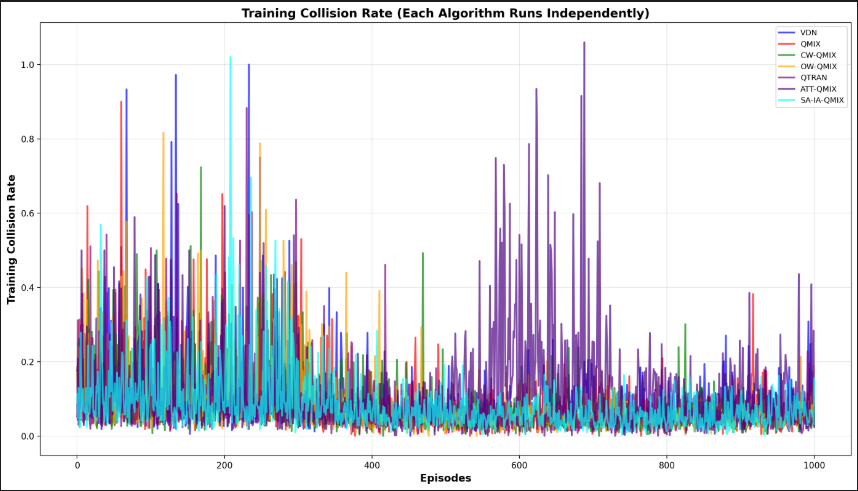
- 图片中还是很精彩的!ATT_QMIX在600轮的时候突然冒尖,其他的方法反而平稳!这只是训练初期,后面看看效果!
4.1.4 改进后的滑动平均奖励效果
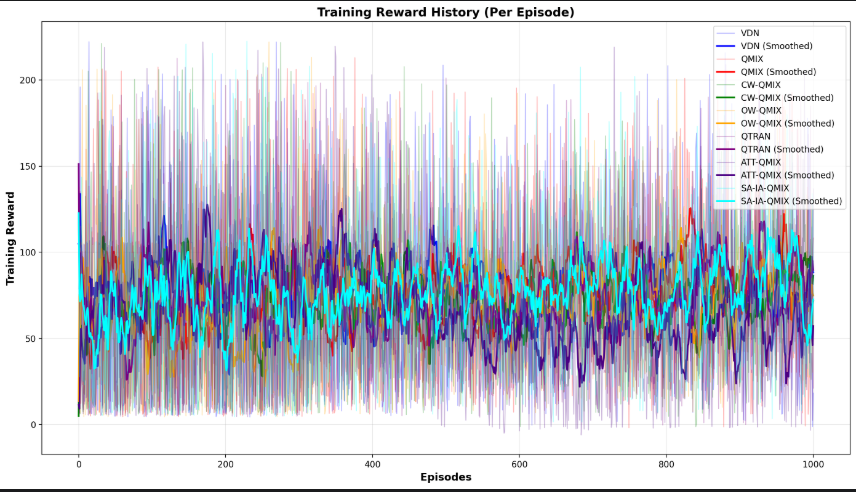
- 这里看得出来,由于环境比较简单,阶段1都是智能体在目标资源点周围极小范围出生,可能一开始奖励就较收敛了,只不过由于这个任务的性质,是不可能逼近一个横线了,收敛的状态是次收敛了。
4.2 最终训练和评估效果
4.2.1 最终训练碰撞效果
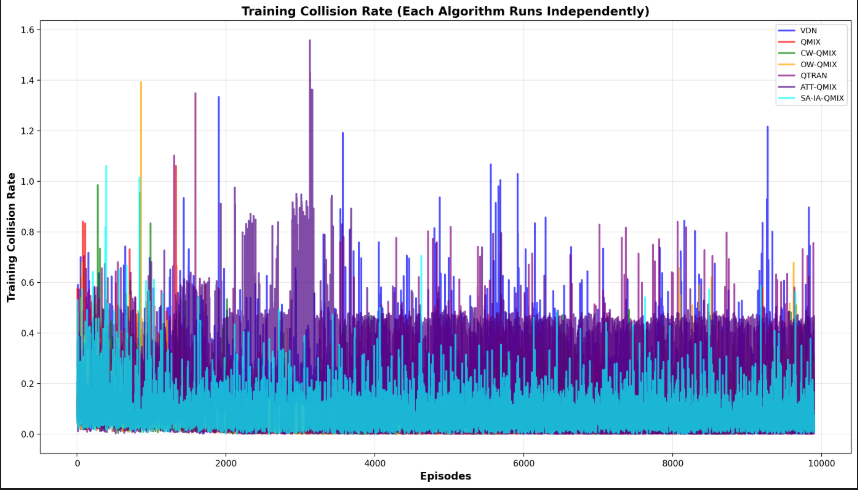
- 可以看到在阶段1的时候,7种算法大家都很震荡。在阶段2和3时SA-IA-QMIX的效果比其他算法较好,其中VDN碰撞率出现尖端,SA-IA-QMIX>ATT-QMIX=QTRAN=QMIX>CW-QMIX=OW-QMIX>VDN。
4.2.2 最终训练收集率效果
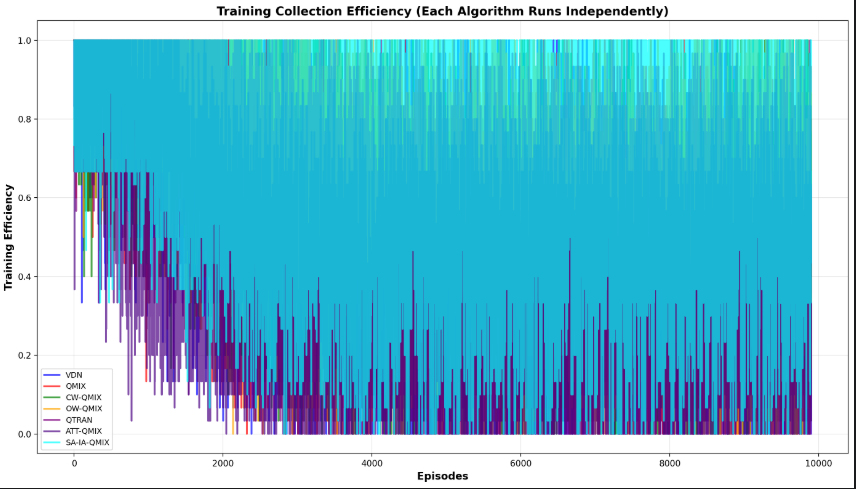
- 在阶段1,因为目标比较简单,智能体都出生在资源点附近,所以收集效果比较好;但当阶段2、阶段3时,环境变的更复杂了,但是反而CW-QMIX的收集率效果好。
4.2.3 最终训练动作一致性效果
4.2.3 最终训练滑动平均奖励效果
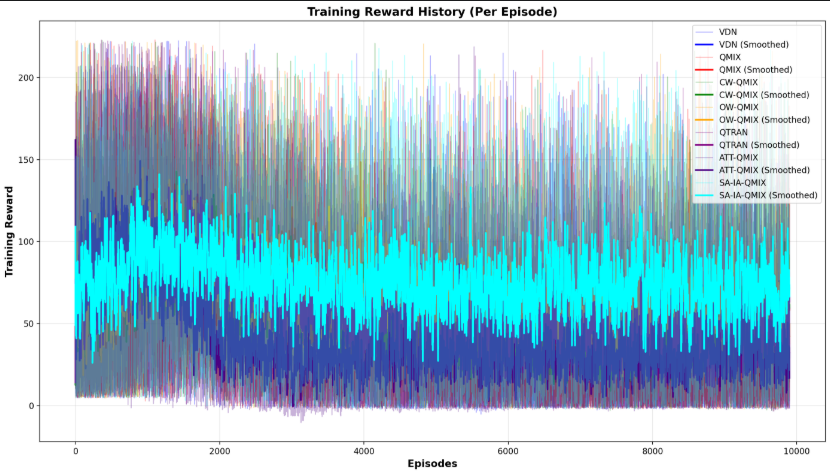
- 这种任务是不太适合用滑动平均奖励收敛性,环境随机意味着就算智能体学会了最优的策略,也会因为环境的随机,奖励回报也不一样,当然,可以在图中可以明显看出,阶段1是奖励回报是最好的,因为阶段1是比较简单的。虽然证明不了收敛性,但是可以评判不同网络框架在同一任务下的训练效果,其中,CW-QMIX/OW-QMIX/QMIX/QTRAN/ATT-QMIX奖励比较发散,而VDN的收敛效果比SA-IA-QMIX的较差一点。
4.2.4 最终评估碰撞率效果
我们的评估环境都是在全图随机生成的,但是策略是从不同训练阶段得到的: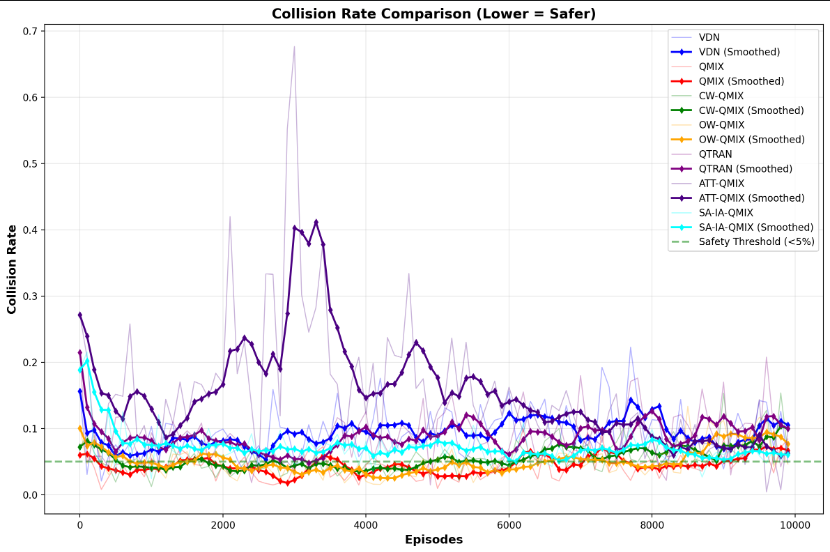
- 可以看到,说明在训练阶段1的策略促进了评估时碰撞率的效果,但是发现ATT-QMIX在阶段2开始摆烂了,在阶段3又开始变好了。
- QMIX>OW-QMIX>CW-QMIX>SA-IA-QMIX>VDN>QTRAN>ATT-QMIX;可以发现,虽然理论上有些方法的效果是比VDN好的,但是在实际中VDN反而会更好。
4.2.5 最终评估收集率效果
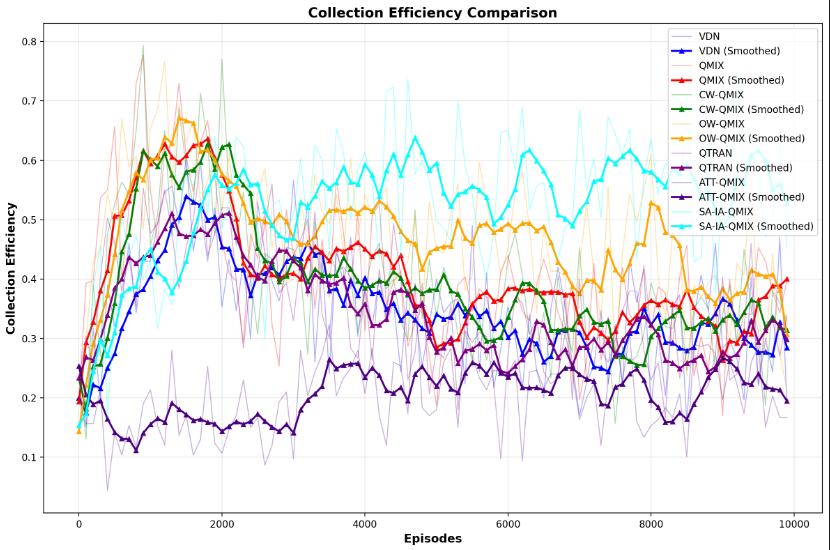
- 在收集率上,刚开始都是往上趋势,在训练阶段环境变更时,说明智能体摆烂了,不继续变优了,有些方法反而越变越差,不适应环境变复杂了。
- 这里显示,SA-IA-QMIX方法是最好的,它是最优的,这个理论恰恰表明SA-IA-QMIX方法的优越性。
4.2.6 最终评估动作一致性效果
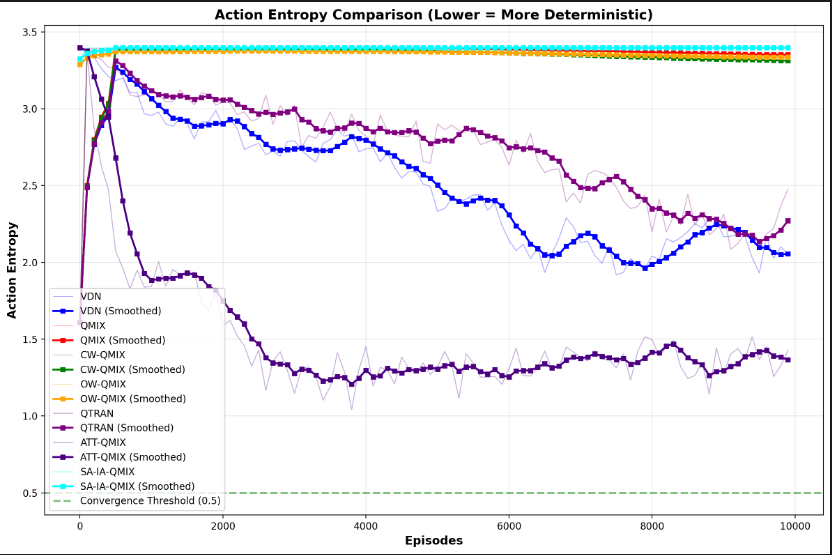
- E=0,智能体越自信执行策略,但是看图片中只有ATT-QMIX\VDN\QTRAN变的越来越自信。
4.2.7 最终评估效果视频
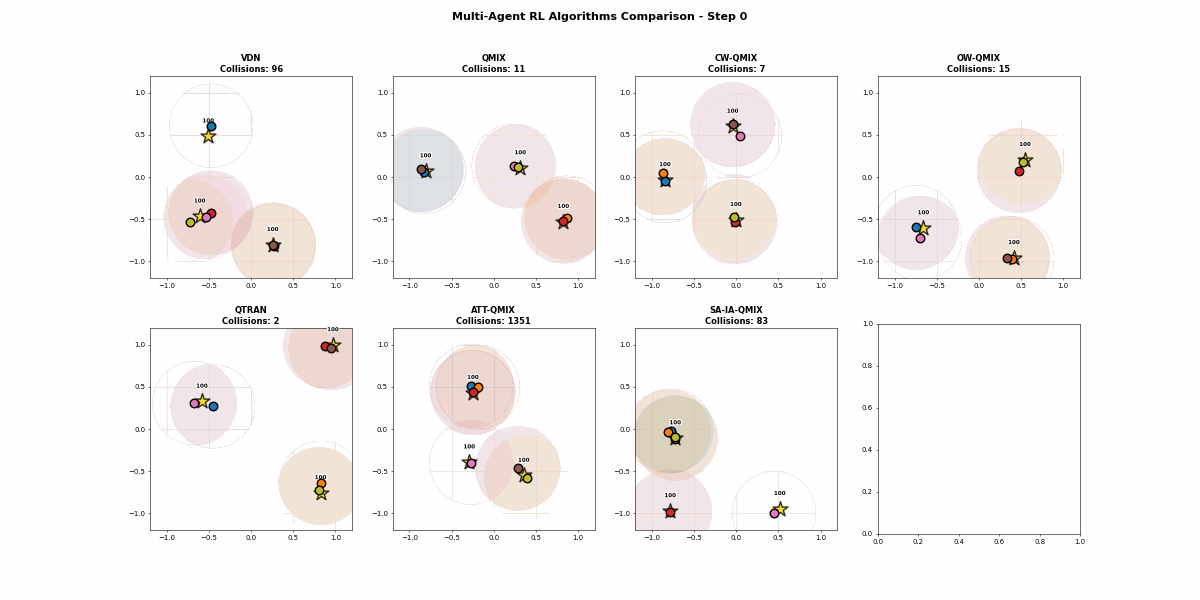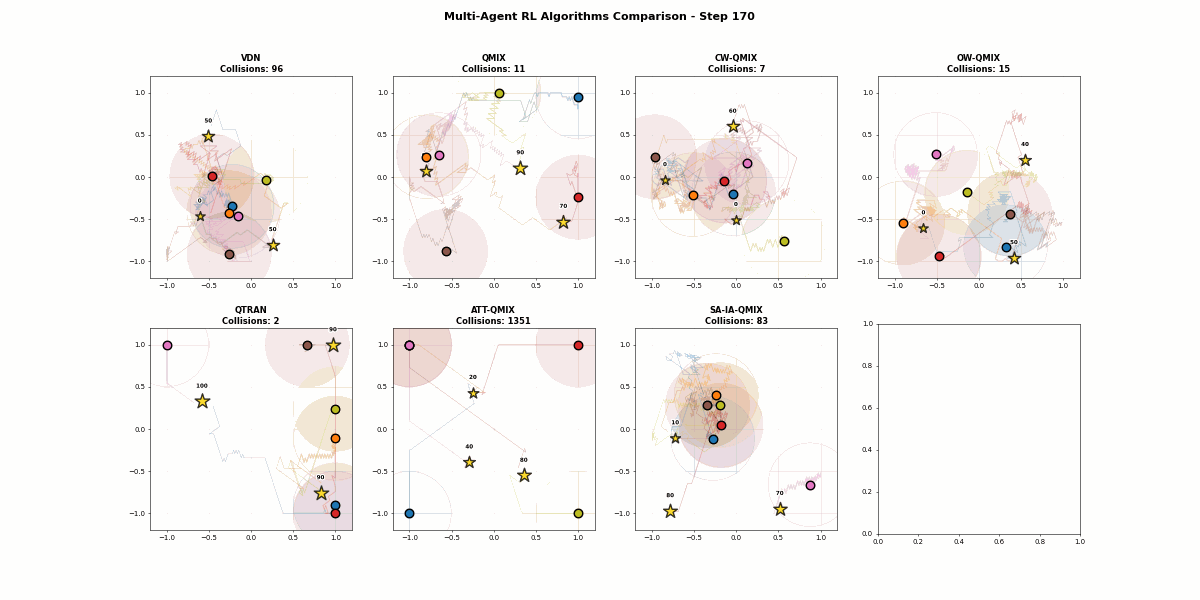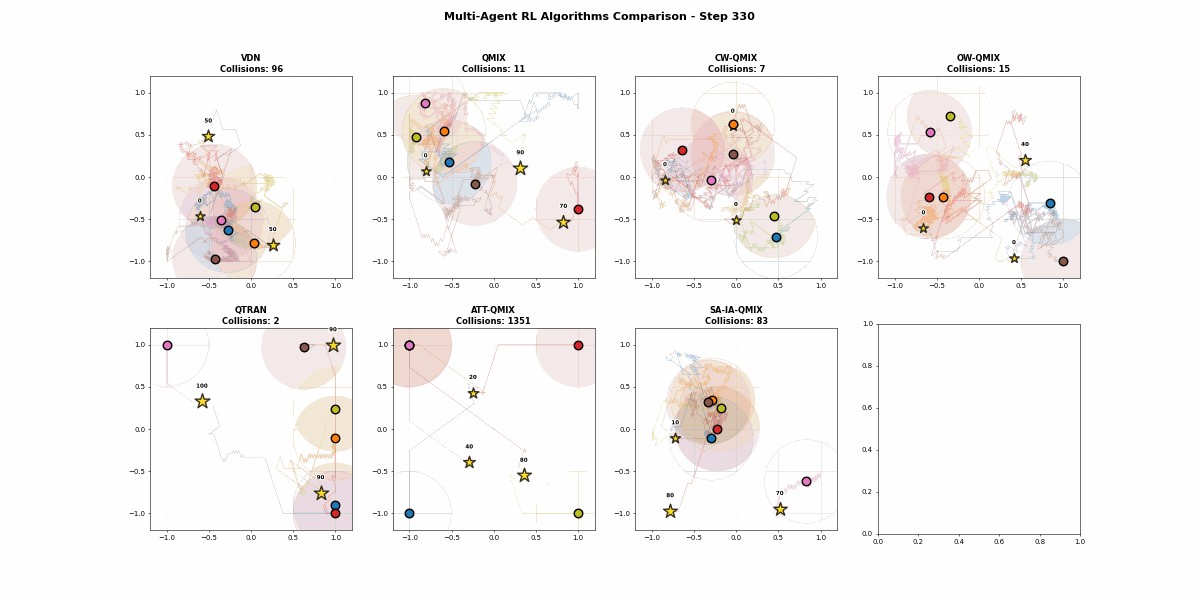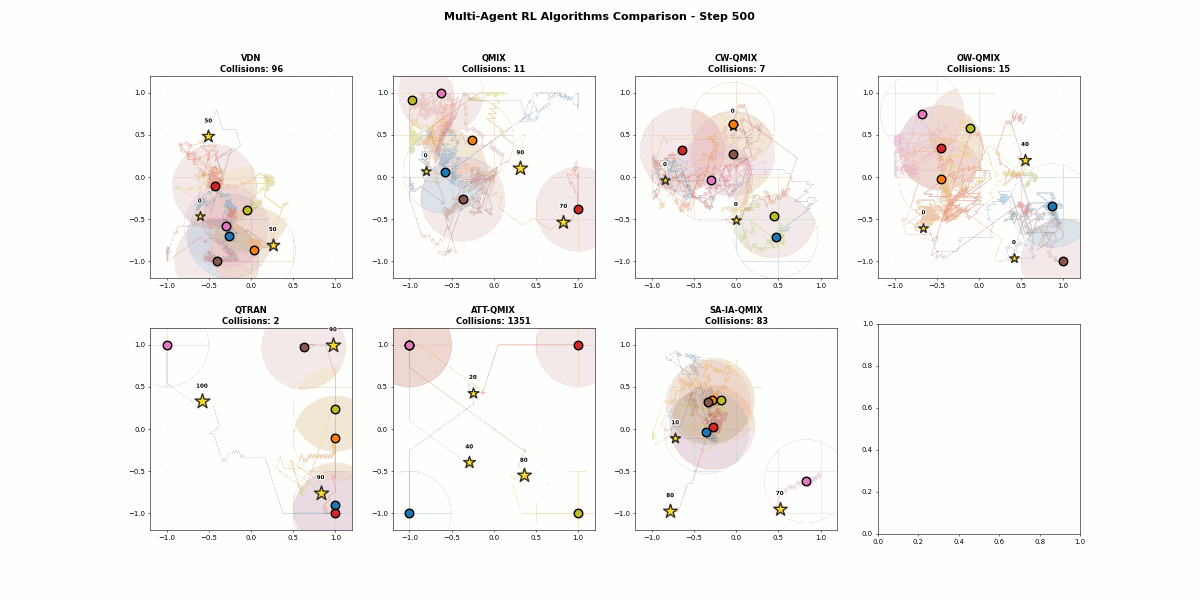
OK,这里就写完了7种算法的研究。
效果不太行,可能因为前期学习率已经消耗太久了,在训练阶段2和3的时候,智能体太会摆烂了,不符合预期,说明科研的时候最好用开源的代码,不然从0到1的代码复现太难了,这里我们就看QMIX家族的效果展示。
虽然效果不太行,还是有一点价值可得的,对于大家学习价值分解的研究具有一定帮助!!!
- 我就不放github代码了,如果需要,可以私聊。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)