
OpenClaw 的多 agent 团队搭建协作:结合飞书、Telegram、Discord 做真正能落地的分工
OpenClaw 的多 agent 团队搭建协作:结合飞书、Telegram、Discord 做真正能落地的分工
这篇文章适合已经把 OpenClaw 跑起来,并且已经至少接好一个渠道的人。
目标很明确:不是空谈“多智能体很厉害”,而是讲清楚什么时候该上多 agent、主 agent 和子 agent 到底怎么分工,以及飞书、Telegram、Discord 这三种入口应该怎么配合使用。
一、先说结论:不是所有团队都需要多 agent,但一旦开始多人协作,它就很值
如果你现在只是:
- 一个人用
- 一个聊天入口
- 让 OpenClaw 帮你写写代码、查查资料
那单 agent 基本够用。
但如果你已经出现下面这些情况,多 agent 就不是“锦上添花”,而是很快会变成“必须要上”:
- 一个需求同时要查资料、改代码、做验证
- 你希望 AI 能并行干活,而不是一个步骤一个步骤排队
- 你希望不同渠道承接不同类型的任务
- 你不想把老板私聊、团队频道、运营通知,全都堆到同一个 agent 里
说白了:
单 agent 更像一个全能助理,多 agent 更像一个有前台、有开发、有测试的小团队。
二、OpenClaw 里说的“多 agent”,到底分哪两种
这是最容易搞混的地方。
根据 OpenClaw 官方文档,你至少要把下面两种东西分清楚。
1. 多个顶层 agent
这类 agent 往往是长期存在的。
你可以理解成:
- 一个负责飞书入口
- 一个负责 Telegram 深度沟通
- 一个负责 Discord 开发频道
它们可以有:
- 不同的工作区
- 不同的模型策略
- 不同的渠道绑定
- 不同的职责边界
2. 子 agent
这类 agent 更像“临时工”。
主 agent 收到任务后,可以用官方的 sessions_spawn 把任务拆出去,让几个子 agent 并行执行,再把结果汇总回来。
比如:
- 研究 agent 去查文档
- 编码 agent 去改代码
- QA agent 去跑验收
你可以把它理解成:
顶层 agent 负责长期分工,子 agent 负责单次任务里的并行拆解。
三、最推荐你先记住的协作模型
如果你第一次搭多 agent,我建议你不要一上来就搞 7 个、8 个角色。
最稳的起步方式就是下面这个模型:
- 一个主 agent 负责接活、路由、汇总
- 两到三个子 agent 负责并行处理
- 结果统一回到原来的聊天入口
你可以先看这个图:
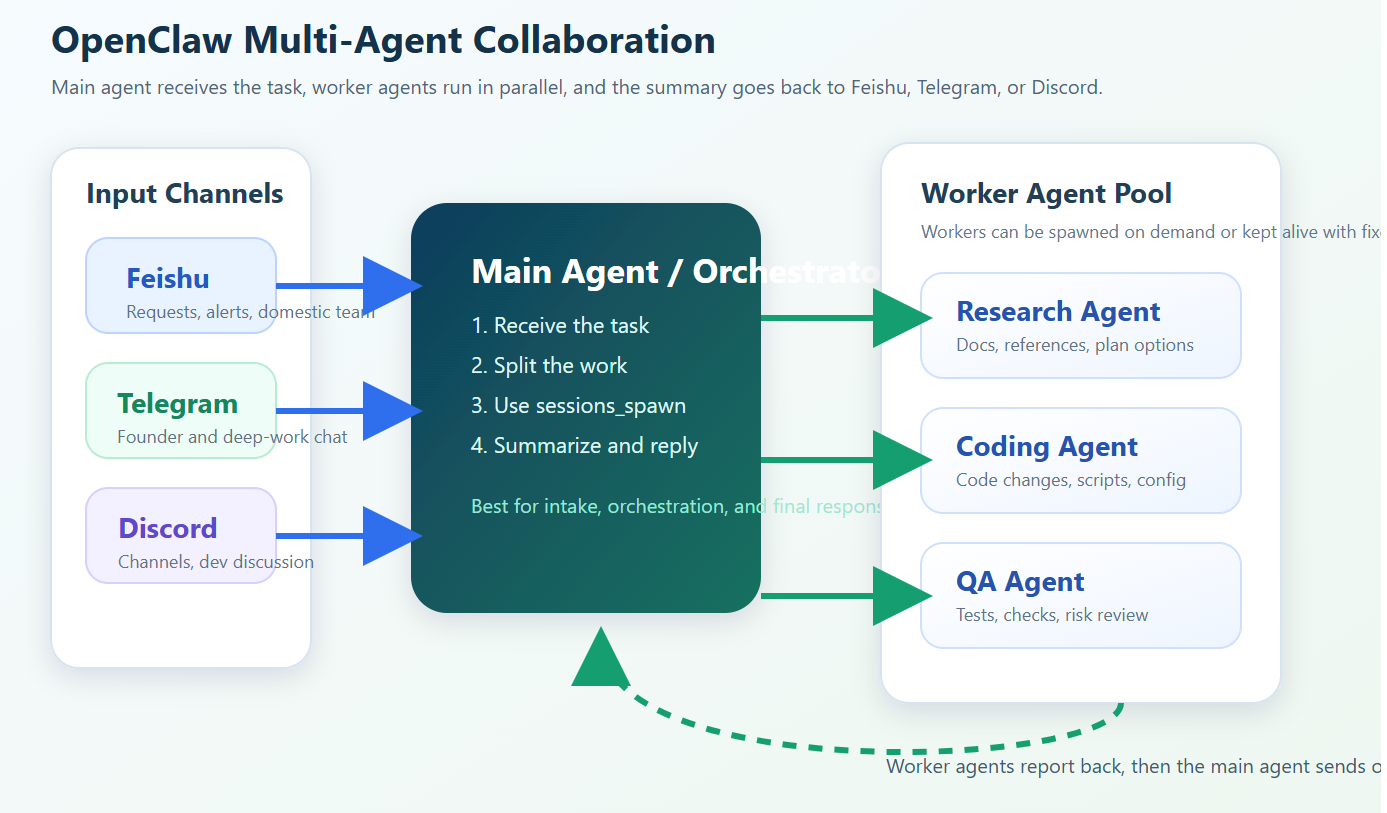
这个图对应的就是最实用的一版:
- 飞书、Telegram、Discord 都可以作为外部入口
- 主 agent 负责判断该不该拆任务
- 子 agent 分别去做研究、编码、测试
- 最后再由主 agent 把结果发回给用户
这比“所有事情都让一个 agent 自己硬扛”要稳很多。
这里我提前澄清一个很容易误解的点:
我推荐的默认设计,不是让每个子 agent 都再额外对应一个新的 Telegram / 飞书 / Discord 机器人。
更推荐的结构是:
- 外部渠道机器人,负责做人类用户入口
- 内部子 agent,负责系统内部编排和执行
也就是说:
- 你完全可以只有 1 个 Telegram 机器人对外
- 但它背后仍然能拉起多个内部 sub-agent 去做研究、编码、QA
这些内部 sub-agent 默认并不需要用户直接和它们聊天,也不需要每个都单独绑一个外部 bot。
只有在下面这种场景,你才需要给不同 agent 再额外配独立外部机器人:
- 你希望不同团队成员分别直接找不同 agent
- 你希望不同渠道本身就承接不同业务入口
- 你希望某个 agent 长期独立对外服务,而不是只做内部 worker
如果只是做任务编排,内部 worker agent 不需要额外做成新的 Telegram 机器人,这是我更推荐的第一版。
四、飞书、Telegram、Discord 分别适合做什么
这一段非常关键。
很多人不是不会搭,而是角色分错了。
结果就是:
- 本来该走通知链路的任务,跑去深度聊天入口
- 本来该给团队频道看的结果,回到了老板私聊
- 本来该多人协作的任务,被塞进单人 DM
我建议你按下面这个思路来分。

1. 飞书
更适合:
- 国内团队
- 日常通知
- 需求受理
- 运营或客服入口
优点是:
- 国内用户更顺手
- 不需要魔法梯子
- 更适合承接“把事情接进来”的前台工作
所以飞书最适合绑定:
- 运营 agent
- 客服 agent
- 主调度 agent
2. Telegram
更适合:
- 创始人或核心负责人私聊
- 长上下文的连续沟通
- 更自由、更高频的个人工作流
它的优点是:
- 私聊体验强
- 对技术用户很友好
- 做深度需求讨论、长期个人陪跑都很顺
但要明确告诉国内用户:
Telegram 往往需要魔法梯子。
3. Discord
更适合:
- 多人协作
- 多频道分主题
- 开发团队长期沟通
- 把日志、测试、发布拆到不同频道
它的强项不是“私聊”,而是“频道化协作”。
但同样要明确一点:
Discord 对国内用户来说,通常也需要魔法梯子。
另外,权限一定要配齐,不然 bot 明明进群了,也可能无法正常对话。
五、最实用的一套角色分工,我建议你直接从这个版本开始
如果你现在是一个小团队,或者准备把 OpenClaw 真正拿来干活,我建议先按下面这个版本落地。
1. 飞书放一个主调度 agent
职责:
- 接需求
- 收问题
- 发通知
- 汇总子 agent 结果
适合谁用:
- 运营
- 客服
- 国内团队成员
2. Telegram 放一个深度工作 agent
职责:
- 和老板或负责人长对话
- 做需求细化
- 做方案对比
- 做高频个人助理
适合谁用:
- 创始人
- 产品负责人
- 技术负责人
3. Discord 放一个开发团队 agent
职责:
- 在不同频道里分主题协作
- 接代码问题
- 接测试问题
- 接发布问题
适合谁用:
- 开发
- QA
- 远程协作团队
这套分工的核心不是“渠道越多越高级”,而是:
让不同场景各走各的入口,别把所有任务全压到一个默认 agent 身上。
六、一个真实可用的工作流应该长什么样
光讲概念没意义,我直接给你一个实战例子。
场景:飞书收到一个新需求
需求内容大概是:
“帮我评估这个需求要怎么做,顺便把代码改掉,再帮我看看有没有回归风险。”
这时候最合理的流程不是让同一个 agent 从头干到尾,而是:
- 飞书主 agent 接到需求
- 主 agent 先拆任务
- 研究子 agent 去看文档和现有实现
- 编码子 agent 去改代码
- QA 子 agent 去检查改动风险和验证点
- 三个子 agent 把摘要回传给主 agent
- 主 agent 再把最终结论回发到飞书
这时候用户看到的是一条清晰结果,背后其实已经完成了并行协作。
这就是多 agent 真正有价值的地方。
七、OpenClaw 官方能力里,哪些点是你最该知道的
这一段不讲全量文档,只讲你搭多 agent 最有用的几个点。
1. sessions_spawn
这是主 agent 拉起子 agent 的关键能力。
你可以把它理解成:
把一个大任务临时拆给几个小 agent 去并行处理。
官方文档还提到:
- 它是非阻塞的
- 发起后会立即返回
- 子 agent 完成后会把结果通报给发起者
这就很适合做:
- 文档调研并行
- 代码修改并行
- 校验复核并行
2. sessions_send
这个更像“跨 session 传话”。
如果你已经有几个长期存在的 agent,会话之间需要交接任务时,这个能力就很有用。
3. 子 agent 的并发和层级要收着点用
官方文档里对子 agent 有几组很实用的限制项:
maxConcurrentmaxSpawnDepthmaxChildrenPerAgent
其中官方默认的 maxConcurrent 是 8,但对大部分团队来说,我不建议你一上来就开那么大。
第一版更稳的思路是:
- 并发先控制在
2到4 - 深度先控制在
1到2 - 不要让子 agent 再无限递归拉更多子 agent
原因很简单:
- 更容易排错
- 成本更可控
- 不容易把上下文和任务路由搞乱
4. /stop 和 /subagents kill
官方也给了停止机制。
这很重要,因为你一旦开始并行跑任务,就必须考虑:
- 拉错了怎么办
- 子 agent 卡住了怎么办
- 不想继续烧 token 了怎么办
所以别只顾着会“开”,也要知道怎么“停”。
八、你真正关心的:这个多 agent 编排到底要怎么搭
前面几段更偏“理解架构”,这一段我直接讲搭法。
你先记住一句最关键的话:
渠道路由 和 任务编排 是两层,不要混在一起。
第一层:渠道路由
这层解决的是:
- 飞书消息进来之后先找谁
- Telegram 私聊进来之后先找谁
- Discord 某个频道进来之后先找谁
这层的目标不是“并行干活”,而是:
先把不同入口稳定地打到不同顶层 agent。
最小落地版你就按这个分:
- 飞书 ->
ops-agent - Telegram ->
deepwork-agent - Discord ->
dev-agent
如果你用的是 Control UI,实际动作就是:
- 先在 Agents 里建 3 个长期 agent
- 再在 Channels 里把不同 channel / account 绑定到对应 agent
- 保存并应用配置
- 每个入口各发一条测试消息,确认确实进的是你想要的 agent
如果这一步都还没稳定,就先别急着做任务编排。
第二层:任务编排
这层解决的是:
- 一个复杂任务进来后要不要拆
- 拆成几个子任务
- 哪个子 agent 负责研究
- 哪个子 agent 负责编码
- 哪个子 agent 负责 QA
- 最后谁来统一汇总
这时候才轮到:
sessions_spawnsessions_send- 子 agent 并发限制
- 子 agent 深度限制
也就是说:
先把“谁接消息”配好,再去配“接到消息以后怎么拆任务”。
九、一个最小可运行的搭建流程,我建议你直接照着做
这一版是我最建议你真正落地的版本。
第一步:先建 3 个顶层 agent
你至少先有:
ops-agentdeepwork-agentdev-agent
分别对应:
- 飞书主入口
- Telegram 私聊入口
- Discord 团队入口
这一步的目标只有一个:
先把渠道入口稳定分流。
但这里再强调一次:
这 3 个顶层 agent 是“如果你真的同时要飞书、Telegram、Discord 三个对外入口”时的推荐布局。
如果你现在只想做一个 Telegram 版本,也完全可以先缩成:
- 1 个 Telegram 入口 agent
- 1 个内部 orchestrator 子 agent
- 2 到 3 个内部 worker 子 agent
也就是说,你完全不必为了做编排,强行去接飞书和 Discord。
我前面用飞书 / Telegram / Discord 举例,是为了讲“多渠道分工”这件事,不是说编排必须依赖这三个渠道同时存在。
第二步:只给主入口 agent 开启子 agent 能力
第一版最稳的做法,不是所有 agent 都能随便拉子 agent,而是:
- 先只让
ops-agent能拉子 agent deepwork-agent和dev-agent先只做各自入口处理
为什么这样更稳?
因为多 agent 一开始最容易乱的地方,不是模型本身,而是:
- 谁能拉人
- 拉出来的任务回给谁
- 哪个入口在做调度
所以第一版先收口到一个主入口最稳。
第三步:把子 agent 并发参数收紧
如果你打算让主入口 agent 去做编排,我建议第一版直接按这个思路控住:
maxConcurrent: 2 到 3maxSpawnDepth: 2maxChildrenPerAgent: 3 到 4
这里有一个关键点很多人会漏:
如果你想做“组 agent 管理其他子 agent”,maxSpawnDepth 至少要允许到 2。
原因很简单:
- 主入口 agent 先拉一个“编排子 agent”
- 这个编排子 agent 再去拉研究 / 编码 / QA 子 agent
如果深度只有 1,就做不到这一层转发。
第四步:明确谁是“入口 agent”,谁是“编排 agent”,谁是“执行 agent”
这一点一定要写清楚,不然 agent 自己也容易乱。
我建议你按这三个角色分:
1. 入口 agent
职责:
- 接收渠道消息
- 判断任务是否复杂
- 决定要不要进入编排模式
- 面向最终用户回消息
2. 编排 agent
职责:
- 接过复杂任务
- 再拆成研究 / 编码 / QA 等执行子任务
- 等各个 worker 回报
- 输出一份结构化总结
3. 执行 agent
职责:
- 只做单一任务
- 不负责对外解释
- 不负责最终汇总
这样一分,整个系统会清晰很多。
第五步:先用一个固定任务跑通编排
不要一上来就让它处理所有需求。
先挑一个固定模板任务测试,比如:
“请先阅读这个需求并整理方案,再改代码,最后做一轮风险检查。”
只要这类任务能稳定跑通,你再慢慢放更多类型进来。
十、怎么让“组 agent”管理其他子 agent,并把结果统一汇总回来
这就是你刚刚指出来缺失的核心点。
这里我直接给你最实用的结构。
不推荐的结构
主入口 agent 直接同时拉:
- research worker
- coding worker
- QA worker
问题在于:
- 主入口 agent 自己还要对用户说话
- 还要接外部渠道消息
- 还要自己收 3 份回报
这样很容易乱。
更推荐的结构
改成三层:
- 入口 agent
- 编排子 agent
- 执行子 agent
也就是:
入口 agent -> 编排子 agent -> worker 子 agent
为什么这一版更合理?
因为根据官方子 agent / session tool 文档,sessions_spawn 拉出来的子 agent,完成结果会回给发起者。
这就意味着:
- 如果是入口 agent 直接拉 3 个 worker
- 那 3 个 worker 的结果都会直接回给入口 agent
而如果你改成:
- 入口 agent 只拉 1 个编排子 agent
- 编排子 agent 再拉 3 个 worker
那最后:
- 3 个 worker 的结果会先回给编排子 agent
- 编排子 agent 汇总后,再把统一结果回给入口 agent
这就形成了真正的“组 agent 管理子 agent”的结构。
这才是你要的那个编排链条。
换成你刚才举的 Telegram 例子,就是这样:
方案 A:我更推荐的第一版
- 对外只有 1 个 Telegram 主机器人
- 用户只和这个主机器人聊天
- 主机器人背后对应入口 agent
- 入口 agent 拉一个内部 orchestrator
- orchestrator 再拉内部 research / coding / QA worker
- 最终结果回到入口 agent,再回复给 Telegram 用户
这套的特点是:
- 外部入口简单
- 用户体验最清晰
- 不需要额外创建 2 个 Telegram 子机器人
- 最适合第一版落地
方案 B:你也可以做多个 Telegram 机器人,但我不建议一开始这么做
也就是:
- 1 个 Telegram 主机器人
- 2 到 3 个 Telegram 子机器人
- 每个机器人各自绑定一个 agent
这套当然也能做,但问题是:
- 用户容易混淆到底该找哪个机器人
- 权限、配置、运维都更复杂
- 实际上很多 worker agent 并不需要直接对外
所以如果你的目标只是“编排任务”,而不是“让多个机器人都对外接客”,那这版没有必要先上。
方案 C:飞书 / Discord 作为其他外部入口,不是 Telegram 主机器人的子机器人
这个也是你刚才问到的另一个重点。
飞书和 Discord 在我文章里的定位是:
- 如果你同时有飞书团队入口
- 同时有 Discord 团队入口
那它们各自都可以绑定自己的顶层 agent。
它们不是 Telegram 主机器人的“子机器人”,而是并列的外部入口。
也就是说:
- Telegram 入口 agent
- 飞书入口 agent
- Discord 入口 agent
这三者是平级的。
真正负责拆分和汇总的,是它们背后共享的编排逻辑,而不是渠道之间互相当子机器人。
这一套的具体执行流程
你可以直接按下面这个顺序理解:
- 飞书把复杂需求发给
ops-agent ops-agent判断这是复杂任务,需要拆分ops-agent用sessions_spawn拉起一个orchestrator子 agentorchestrator收到任务后,再分别拉起:research-workercoding-workerqa-worker
- 这 3 个 worker 分别执行自己的子任务
- 它们执行完成后,结果先回到
orchestrator orchestrator把三份结果整合成一份统一摘要orchestrator再把摘要回给ops-agentops-agent把最终结果整理成面向用户的回复,回发到飞书
这就是最标准的“组 agent 管理子 agent 并汇总”的落地方式。
什么时候必须上“编排子 agent”
我建议你遇到下面这类任务时就上:
- 同时包含调研、实现、验证三步
- 一个任务明显会分成多个平行子任务
- 你希望最终结果是一个统一结论,而不是 3 份散结果
如果只是简单问题,比如:
- 帮我解释一段代码
- 帮我改一个小 bug
- 帮我起草一段回复
那入口 agent 直接自己做就行,不必每次都开编排。
十一、怎么把这个“编排逻辑”真正教给 agent
只开参数不够。
你还得明确告诉 agent:
- 什么时候该拆任务
- 什么时候该拉编排子 agent
- 什么时候只需要自己直接回答
最稳的做法,就是给入口 agent 加一段明确的系统提示,或者做成一个专门的 Skill。
我更建议你做成 Skill,因为后面更好维护。
比如你可以建一个:
./skills/team_orchestrator/SKILL.md
里面先放一个最小模板:
---
name: team_orchestrator
description: Use this skill when a user request clearly contains multiple parallel workstreams such as research, implementation, and QA that should be split and summarized.
---
# Team Orchestrator
When the user request contains two or more independent workstreams:
1. Do not execute every step in the main agent directly.
2. First spawn one orchestrator sub-agent for the whole task.
3. The orchestrator sub-agent may then spawn specialized worker sub-agents such as research, coding, and QA.
4. Each worker must only handle its own slice and return a concise result.
5. The orchestrator must wait for all worker reports, merge them into one summary, and send that summary back to the parent agent.
6. The parent agent should then produce the final user-facing answer.
Do not use this pattern for trivial single-step requests.
这段模板的重点不在文字优雅,而在于它把编排规则写死了:
- 主入口别自己硬做全部事情
- 先拉一个编排子 agent
- 编排子 agent 再拉 worker
- worker 回给编排子 agent
- 编排子 agent 再统一汇总
你只要把这个逻辑稳定下来,整个系统的行为就会比“靠 agent 临场发挥”稳定得多。
十二、如果你是按 Control UI 来配,实际点击路径怎么走
这里直接说结论,不绕弯子。
你截图里的这个页面,没有创建 agent 按钮是正常的。
而且你现在还是公网 http 直接打开,所以页面上还带着:
origin not allowed
这说明两件事:
- 这个页面现在不能当“主配置入口”
- 你继续在 UI 里找按钮,基本走不下去
这版 OpenClaw 2026.3.2,最稳的配置方式是:
- 用 CLI 建 agent
- 用 CLI 绑 channel
- 用 CLI 设置 subagent 并发和深度
- 最后回 Control UI 验收
你先记住一句话:
先配,再看 UI;不是先看 UI 再硬配。
你现在这个生产容器,最小落地版就按这个顺序配
先进入容器:
docker exec -it 你的OpenClaw容器名 sh
先确认命令在:
openclaw agents --help
openclaw config file
如果你只想先跑通一个主入口,比如 Telegram 主机器人,就先不要一下子搞 3 个入口。
先建一个主 agent:
openclaw agents add "Ops Agent" \
--workspace ~/.openclaw/workspace-main \
--agent-dir ~/.openclaw/agents/ops-agent/agent \
--model kiro-proxy/claude-haiku-4-5 \
--bind telegram \
--non-interactive
再把多 agent 编排的限制补上:
openclaw config set agents.defaults.subagents.maxConcurrent 2
openclaw config set agents.defaults.subagents.maxSpawnDepth 2
openclaw config set agents.defaults.subagents.maxChildrenPerAgent 4
然后检查结果:
openclaw agents list
openclaw agents bindings
cat ~/.openclaw/openclaw.json
如果你看到:
ops-agent- routing 里有
telegram agents.defaults.subagents里已经有深度和并发
那就说明已经配进去了。
如果你要 3 个长期 agent,就直接照下面抄
openclaw agents add "Ops Agent" \
--workspace ~/.openclaw/workspace-main \
--agent-dir ~/.openclaw/agents/ops-agent/agent \
--model kiro-proxy/claude-haiku-4-5 \
--bind feishu \
--non-interactive
openclaw agents add "Deepwork Agent" \
--workspace ~/.openclaw/workspace-deepwork \
--agent-dir ~/.openclaw/agents/deepwork-agent/agent \
--model kiro-proxy/claude-haiku-4-5 \
--bind telegram \
--non-interactive
openclaw agents add "Dev Agent" \
--workspace ~/.openclaw/workspace-dev \
--agent-dir ~/.openclaw/agents/dev-agent/agent \
--model kiro-proxy/claude-haiku-4-5 \
--bind discord \
--non-interactive
如果 agent 已经建好了,只是后面想补绑定,就用:
openclaw agents bind --agent ops-agent --bind feishu
openclaw agents bind --agent deepwork-agent --bind telegram
openclaw agents bind --agent dev-agent --bind discord
你为什么会在 UI 里看到 0 configured
不是因为一定没配成功,而是因为你当前打开方式本身就有问题。
你现在是:
- 公网 IP
- 直接
http - 浏览器页面提示
origin not allowed
所以这个页面连完整 agent 数据都拿不到。
更稳的看法是:
- 先在容器里把 agent 配好
- 再用本机或 SSH 隧道去开控制台
- 再看
Overview / Channels / Chat
如果你非要在公网浏览器里直接看,那至少要处理:
gateway.controlUi.allowedOrigins
否则你会一直误以为“没配置成功”,其实只是 UI 根本没拿到数据。
十三、一个适合新手直接抄的实测配置思路
这里我不放概念图,只放你最需要知道的 5 个点。
- agent 自己没有
channels字段 - 路由是在顶层
bindings description不是这版 agent schema 的字段- 子 agent 并发和深度在
agents.defaults.subagents - 单个 agent 自己能拉谁,在
subagents.allowAgents
也就是说,你真正要认的结构是这个:
{
"agents": {
"defaults": {
"workspace": "~/.openclaw/workspace-main",
"model": {
"primary": "kiro-proxy/claude-haiku-4-5"
},
"subagents": {
"maxConcurrent": 2,
"maxSpawnDepth": 2,
"maxChildrenPerAgent": 4
}
},
"list": [
{
"id": "ops-agent",
"default": true,
"name": "Ops Agent",
"workspace": "~/.openclaw/workspace-main",
"agentDir": "~/.openclaw/agents/ops-agent/agent",
"model": "kiro-proxy/claude-haiku-4-5",
"subagents": {
"allowAgents": [
"orchestrator-agent",
"research-agent",
"coding-agent",
"qa-agent"
]
}
},
{
"id": "deepwork-agent",
"name": "Deepwork Agent",
"workspace": "~/.openclaw/workspace-deepwork",
"agentDir": "~/.openclaw/agents/deepwork-agent/agent",
"model": "kiro-proxy/claude-haiku-4-5"
},
{
"id": "dev-agent",
"name": "Dev Agent",
"workspace": "~/.openclaw/workspace-dev",
"agentDir": "~/.openclaw/agents/dev-agent/agent",
"model": "kiro-proxy/claude-haiku-4-5"
}
]
},
"bindings": [
{
"agentId": "ops-agent",
"match": {
"channel": "feishu"
}
},
{
"agentId": "deepwork-agent",
"match": {
"channel": "telegram"
}
},
{
"agentId": "dev-agent",
"match": {
"channel": "discord"
}
}
]
}
如果你现在只是个人用,我还是建议你先走最短路线:
- 只配 1 个 Telegram 主机器人
- 只建 1 个
ops-agent - 先把
sessions_spawn能力跑通 - 后面再考虑要不要拆出飞书入口和 Discord 入口
也就是说,第一版最简单的落地不是:
- 3 个外部机器人
- 3 个外部入口
- 一堆路由
而是:
- 1 个外部入口
- 1 个主 agent
- 多个内部 sub-agent
这才是最容易先跑通的版本。
十四、飞书、Telegram、Discord 结合多 agent 时,最容易踩的坑
1. 所有渠道都绑定到同一个默认 agent
这会导致:
- 上下文混杂
- 角色边界不清
- 不同场景的消息全挤在一起
最后你会发现 agent 什么都在做,但什么都做不稳。
2. 一上来就开太多并发
很多人看到可以并行,就忍不住把并发开很大。
问题是:
- 日志更难看
- 结果更难汇总
- token 消耗更快
- 一旦任务拆错,更难回收
第一版宁可保守,也别激进。
3. 渠道适配没讲清楚
这点对交付很重要。
你最好明确告诉用户:
- 飞书一般不需要魔法梯子
- Telegram 通常需要
- Discord 通常也需要
如果这件事不提前说清楚,后面很多“接入失败”“为什么打不开”的问题,其实根本不是 OpenClaw 本身的问题。
4. Discord 权限没配齐
尤其是 Discord。
如果 bot 缺权限,它可能出现这些现象:
- 能进频道但不能正常回复
- 能收到一部分消息但不能完整工作
- 私聊没问题,频道里却异常
所以你在做 Discord 协作入口时,一定要把权限说明写完整。
5. 不给 agent 明确职责
比如:
- 飞书 agent 既做客服又做研发又做发布
- Telegram agent 既做老板助理又做所有工单
- Discord agent 什么频道都接
这种设计短期看省事,长期一定会乱。
最稳的方法永远是:
一个 agent 一个明确角色。
十五、如果你想把它真正用在团队里,我建议的上线顺序
你可以直接照这个顺序来。
- 先选一个主入口
- 先把这个入口跑稳定
- 再补第二个渠道
- 再补第三个渠道
- 再让主 agent 学会拆任务
- 最后再优化并发、深度和成本
比如对国内团队来说,我一般更建议:
- 先飞书
- 再 Telegram
- 最后 Discord
因为飞书门槛最低,最适合先把流程跑顺。
十六、如果你准备自己实操,直接按这 3 篇继续往下做
这篇到这里,主要解决的是:
- 让你理解多 agent 到底该怎么设计
- 让你分清楚外部入口和内部 worker 不是一回事
- 让你知道飞书、Telegram、Discord 更适合承接什么场景
但如果你现在不是想看概念,而是想直接上手配置,那最省时间的走法不是反复读这篇,而是直接接着做后面这 3 篇:
1. 先看 OpenClaw 最短落地教程:用生产容器从 0 到 1 配出 Telegram -> ops-agent
它解决的是:
- 先把
Telegram -> ops-agent单入口跑通 - 先确认 Telegram bot 真能进 OpenClaw
- 先把第一个主入口稳定下来
2. OpenClaw 第二篇最短落地:在 ops-agent 基础上补 research-agent
它解决的是:
- 给
ops-agent补上research-agent - 补上
coding-agent - 补上
qa-agent - 让主 agent 真正具备内部拆任务能力
3. 最后看 OpenClaw 第三篇最短排障:修 provider 401,让多 agent 真正能跑
它解决的是:
- 排掉最容易卡住的
provider 401 - 修通 OpenClaw 到代理层的认证
- 完成最后一轮真实回归
你可以把这 4 篇的关系直接记成:
本章 = 讲清楚整体设计
1 = 先把 Telegram 主入口跑通
2 = 再把 3 个内部 worker 补齐
3 = 最后把 provider 401 修掉并做验收
十七、如果你只是想直接拿一个已经搭好的 OpenClaw 多渠道协作环境
你看到这里应该也发现了:
真正麻烦的并不只是“开几个 agent”。
更麻烦的是:
- 每个 agent 的职责怎么定
- 哪个渠道接哪个入口
- 子 agent 并发怎么控制
- 不同团队成员怎么用起来不乱
- Telegram / Discord 对国内用户的网络门槛怎么说明
如果你只是想:
- 快速拥有一个已经配好的 OpenClaw
- 不想自己折腾多渠道和多 agent 路由
- 直接拿来给团队用
也可以直接看我这边的云端版入口:
- 购买地址:
https://opensale.chunlin.lat/
如果你想要教程、或者想交流具体接法,也可以直接联系我:
- 邮箱:
17671460675@163.com - 微信:
17671460675 - qq:
1499831507
十八、下一篇准备写什么
如果你觉得这篇有用,后面我会继续按这个路线往下写:
- OpenClaw 的高阶玩法之 Mission Control 多任务 UI 工作流管理
- OpenClaw 的高阶玩法之 agent 创建 AI,实现自我进化
- OpenClaw 的高阶玩法之如何把 Skill、多 agent、Mission Control 组合成一套长期生产流
参考资料
- OpenClaw 多智能体官方文档:https://docs.openclaw.ai/concepts/multi-agent
- OpenClaw 子智能体官方文档:https://docs.openclaw.ai/tools/subagents
- OpenClaw Session Tool 官方文档:https://docs.openclaw.ai/zh-CN/concepts/session-tool
- OpenClaw 飞书接入文档:https://docs.openclaw.ai/channels/feishu
- OpenClaw Telegram 接入文档:https://docs.openclaw.ai/channels/telegram
- OpenClaw Discord 接入文档:https://docs.openclaw.ai/channels/discord

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)