
GPT-5.4 重磅发布:原生电脑操作登场,编程与工具调用能力全面升级,OpenClaw 将迎挑战?
OpenAI发布GPT-5.4,重点突破原生电脑操作能力。该模型整合了推理、编程和计算机操作等多项能力,支持100万token上下文窗口,能直接操作界面、发送邮件、安排日程等。相比前代,GPT-5.4在计算机操作基准测试中准确率提升30%以上,错误率降低33%,专业任务处理能力显著增强。开发者版本API价格有所上调,但效率更高。这一更新标志着AI从对话工具向工作执行体的转变,可能重塑AI代理领域的
OpenAI 正式发布 GPT-5.4,这一次,那个曾以“能力跃迁驱动行业变化”而广受关注的 OpenAI,似乎又回来了。
与以往单点功能提升不同,GPT-5.4 是一次全面整合:它将推理、编程和计算机操作等多项能力汇聚于同一代模型。换句话说,OpenAI 正尝试让一个模型同时具备“思考能力 + 编程能力 + 原生电脑操作能力”,让 AI 不仅能解决问题,还能直接执行任务。
这次更新备受关注也并非偶然。GPT-5.4 的原生电脑操作能力本身就极具话题性,再加上强化的专业任务处理能力、最高 100 万 token 的上下文窗口,以及更高效的工具调用机制,对于开发者、重度 AI 用户,甚至是想围绕 AI 构建工作流和产品的人来说,都意味着一次实打实的能力跃升。
最大看点:GPT-5.4 开始原生“用电脑”了
如果要说 GPT-5.4 最值得关注的变化,大概率就是:它开始原生具备电脑操作能力了。
OpenAI 对它的描述非常直接:这是他们首个原生具备计算机操作能力的通用模型。这意味着,模型不再只是停留在聊天框里回答问题,而是开始具备进入实际操作环节的能力。
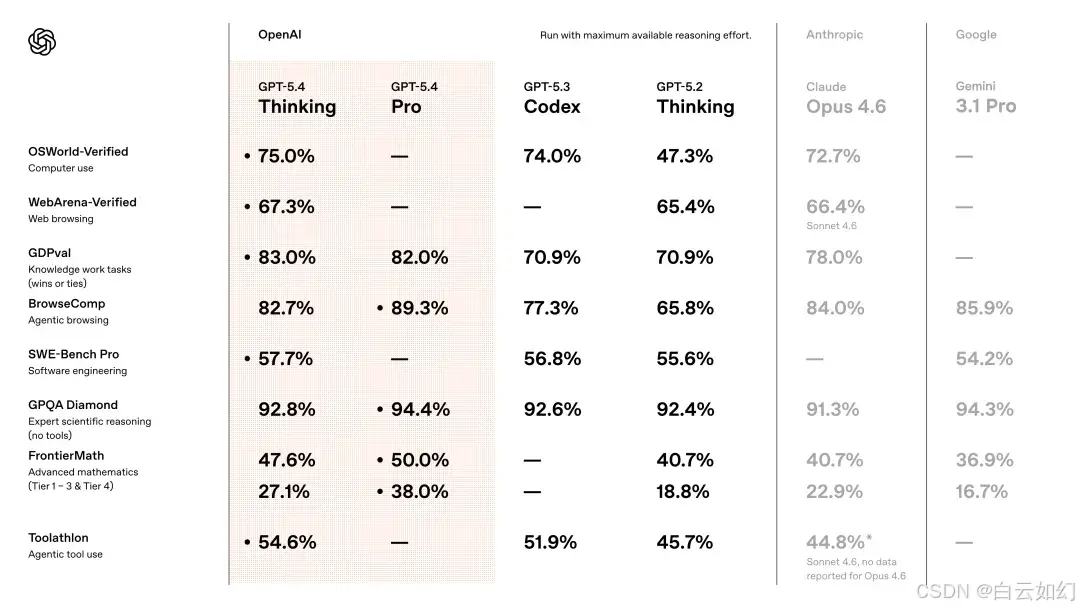
从官方公布的基准测试结果来看,GPT-5.4 在 OSWorld Verified 的 computer use 测试中,成绩从 47.3% 提升到了 75%;在 BrowseComp 上,准确率也从 65.8% 提高到了 82.7%。这说明它在执行真实数字环境任务时,已经比过去成熟了不少。
与 Codex 开始工作时会概述思路类似...
但更重要的并不是分数本身,而是它所代表的交互方式变化。所谓“电脑操作能力”,并不只是调用几个命令行指令,也不是简单执行几步预定义脚本,而是能够查看界面、理解屏幕内容、点击按钮、访问网页、发送邮件、安排日程,乃至完成一系列过去必须由人亲自操作的任务。而这些事情,恰恰是传统网页端聊天机器人很难真正做到的。
这会不会抢走 OpenClaw 一类产品的入口?
如果最近一直在关注 AI Agent 方向,那么你大概率不会对 OpenClaw 这类产品感到陌生。过去几个月,尤其是最近一段时间,“让 AI 直接操作电脑”的方案明显升温,而这背后其实指向的是同一个趋势:AI 的使用方式正在发生改变。
此前,我们更多是在浏览器里与模型交互。那时,AI 主要停留在网页端,本地电脑更像只是承载对话界面的容器,并没有真正进入工作流本身。但现在,情况已经不同了。越来越多产品开始尝试让模型接管部分电脑层面的实际操作,而 GPT-5.4 的出现,则意味着 OpenAI 亲自下场,把“操作电脑”这件事推进成了模型的原生能力。
从 OpenAI 展示的演示来看,GPT-5.4 已经能够相对熟练地完成一系列电脑操作任务,例如识别浏览器界面截图、点击交互元素、发送邮件,以及创建或调整日历安排等。
与此同时,OpenAI 还推出了一项新的实验能力——Playwright (Interactive)。这一功能允许 Codex 在 Web 和 Electron 应用中进行可视化调试,并支持开发过程中边构建、边测试。而它背后的关键支撑,正是模型获得了更直接、更原生的电脑操作能力。
OpenAI 还推出了一个新的实验能力——Playwrigh
OpenAI 研究员 SQ Mah 提到,这背后主要依赖两项能力:其一是 CUA,也就是 computer use ability(计算机操作能力);其二是模型通过图像输入生成高质量网站的能力。
从“会看图”到“会自己检查结果”,模型操作更像人在工作
与 GPT-5.3 Codex 相比,GPT-5.4 在使用 CUA 时有一个很重要的变化:它不再需要额外启动一个全新的环境来执行操作。也就是说,模型在操作上的衔接更自然,流程也更轻量。
在一些演示场景中,这种能力表现得非常直观。例如在 3D 游戏环境里,模型会主动点击界面元素、移动棋子,甚至通过真实操作来验证某条规则是否已经生效。它不是只靠“语言推断”,而是开始通过操作来确认答案。
在网站生成任务中,这种能力也很有代表性。模型可以先调用图像生成工具产出所需图片,然后再通过 CUA 打开这些图片、检查内容,并同时打开网页页面进行对照,尽量让最终生成的网站效果贴近输入参考图。这个过程更像一个真正的设计与开发协作流程,而不是一次性的静态输出。
SQ Mah 还透露,在支持持久化 CUA 后,OpenAI 发现模型在某些“自我验证”场景中的 token 消耗下降了大约三分之二。也就是说,模型不仅更会做事,也更懂得以更低成本完成检查和反馈闭环。
一度沉寂的 CUA,如今被重新推到台前
事实上,OpenAI 并不是今天才开始布局计算机操作能力。早在去年 1 月,他们就已经推出了 CUA。不过,由于安全性、稳定性和准确性等方面的顾虑,这条路线此前并没有得到太多持续曝光。
那段时间里,外界甚至一度怀疑 OpenAI 是否已经放弃了这个方向。尤其是在 GPT-4o 等项目占据大量注意力之后,CUA 几乎淡出了大众视野。再加上它长期停留在预览阶段,访问权限严格,很多开发者即便申请了也迟迟无法体验,这进一步加深了“项目被边缘化”的印象。
但从今天 GPT-5.4 的发布来看,这条路线显然不但没有被放弃,反而已经进入了新阶段。OpenAI 不仅重新强调了这项能力的重要性,还在 GitHub 上放出了新的 CUA sample app,释放出的信号非常明确:他们正在重新推进“AI 直接使用电脑”这件事。
从这个角度看,GPT-5.4 与 OpenClaw 的确有一定正面交集。双方瞄准的,都是同一个核心入口——不再让 AI 只停留在 API 和聊天窗口中,而是让它真正进入电脑操作层。
不同之处在于,OpenClaw 这类方案更多是构建在模型之外的 computer-use 框架,而 GPT-5.4 则是把能力直接做进了模型本身。后者的优势在于路径更短、整合度更高,也更容易在安全性、速度和一致性上持续优化。
如果未来主流模型在这方面持续进步,那么像 OpenClaw 这样的开源项目必然会面临更直接的竞争压力。与此同时,那些拥有资源和客户基础的大公司,也完全可能快速构建出属于自己的“电脑操作型 AI 系统”。从 agentic AI 的发展节奏来看,这确实是一个非常值得关注、也非常令人兴奋的阶段。
更适合开发者:工具搜索上线,成本和效率同时改善
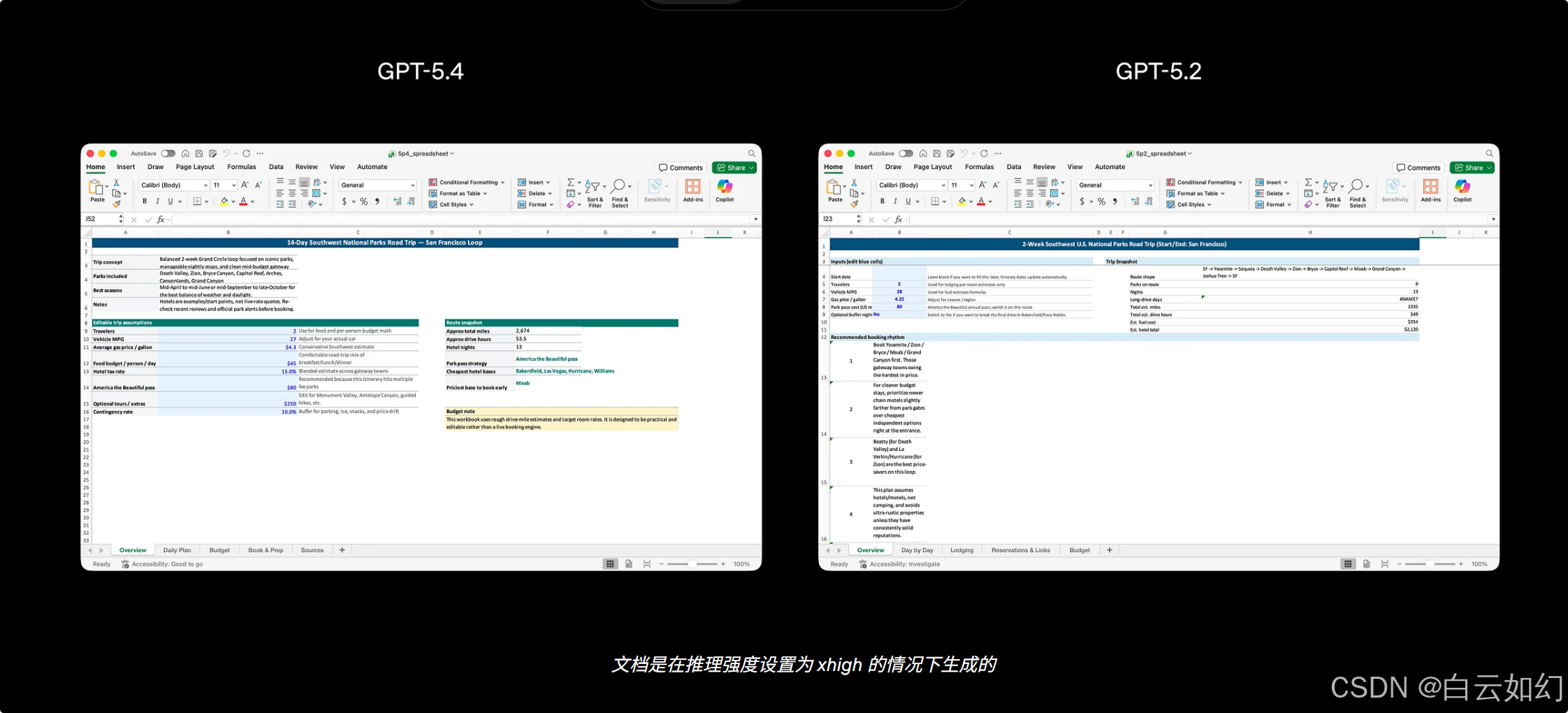
GPT‑5.4 同样优化了工具调用能力,使其在推理过程中能更准确、更高效地判断调用工具的时机与方式,这在 API 环境下尤为突出。相比 GPT‑5.2,它在 Toolathlon 基准测试中能以更少的轮次达到更高的准确率。该测试旨在评估 AI 智能体利用真实世界工具和 API 完成多步任务的能力 — 例如,智能体需要读取邮件、提取作业附件、上传并评分,最后将结果记录到电子表格中。
幻觉减少,专业场景更有实用价值
另一个值得注意的提升,是 GPT-5.4 在事实准确性上的改进。
根据 OpenAI 的说法,和 GPT-5.2 相比,GPT-5.4 在单条事实陈述上的出错概率下降了 33%,整体回答中包含错误信息的概率也降低了 18%。这类改进看起来不如“会操作电脑”那么吸睛,但对专业用户而言,反而更实际。
因为在真实工作场景中,AI 是否足够可靠,很多时候比它是否足够炫技更重要。尤其是法律、咨询、研究、金融分析等高度依赖准确性的领域,错误率的下降意味着可用性的提升。
例如在 Harvey 的 BigLaw Bench 法律文档评测中,GPT-5.4 的准确率达到 91%。这表明它在专业文本理解与处理方面,也正在向更高水平靠近。
编程能力继续增强,ChatGPT 与 Codex 的边界被进一步打通
对于开发者来说,GPT-5.4 的另一大亮点是:它正在成为 OpenAI 新的主力编程模型。
过去,很多人在使用 OpenAI 产品时常常会纠结:是直接用 ChatGPT,还是切到 Codex?而在 GPT-5.4 这一代上,这种区分正在被弱化。OpenAI 想做的显然是让用户不必频繁切换模型,而是在同一个体验里就能完成从对话到编码的全过程。
|
GPT-5.4 |
GPT-5.3-Codex |
GPT-5.2 |
|
|---|---|---|---|
|
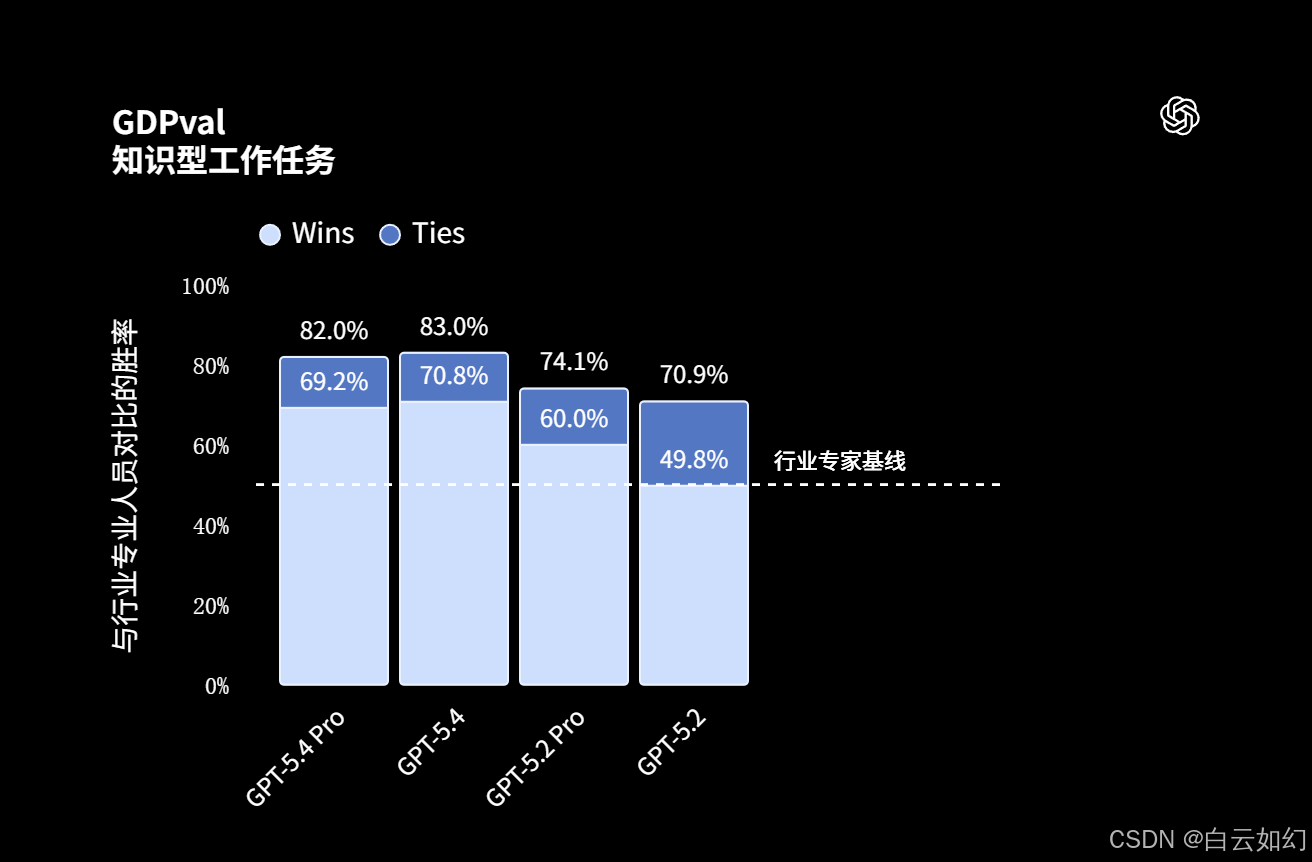
GDPval(胜出或持平) |
83.0% |
70.9% |
70.9% |
|
SWE-Bench Pro (Public) |
57.7% |
56.8% |
55.6% |
|
OSWorld-Verified |
75.0% |
74.0%* |
47.3% |
|
Toolathlon |
54.6% |
51.9% |
46.3% |
|
BrowseComp |
82.7% |
77.3% |
65.8% |
从测试结果来看,GPT-5.4 在 SWE-Bench Pro 上的表现与 GPT-5.3-Codex 持平,甚至在部分场景更强,同时速度也更快,尤其是在较低推理强度下更明显。这意味着用户在对话中可以更直接地开始写代码,而无需额外思考该调用哪个模型。
此外,Codex 还新增了 fast mode,在支持的模型上最高可带来 1.5 倍的速度提升。OpenAI 同时强调,GPT-5.4 在复杂前端任务上的表现更好,既能生成更精致的页面效果,也能更好保证功能正确性。结合不少开发者的反馈来看,这一点已经在实践中有所体现。
能力升级之外,价格也同步抬升
当然,能力增强的另一面,是价格的上调。
在 API 中,OpenAI 将 GPT-5.4 Thinking 对应为 gpt-5.4,将 GPT-5.4 Pro 对应为 gpt-5.4-pro。具体价格如下:
GPT-5.4
-
输入:$2.50 / 每 100 万 token
-
输出:$15 / 每 100 万 token
GPT-5.4 Pro
-
输入:$30 / 每 100 万 token
-
输出:$180 / 每 100 万 token
从市场横向对比来看,GPT-5.4 的 API 成本仍属于相对偏高的一档,尤其是 Pro 版本,对预算敏感型团队来说需要更谨慎评估。
此外,GPT-5.4 还有一个与长上下文相关的重要定价规则:当单次请求的输入 token 超过 272,000 时,超长上下文部分将按正常价格的 2 倍计费。这个机制也反映出,OpenAI 正在把更长上下文能力正式纳入产品设计中,但同时也希望用户为这种资源占用支付更高成本。
在 Codex 中,默认的 compaction(压缩)上限就是 272k token。也就是说,只要开发者把提示规模控制在这个范围内,就不会触发额外的长上下文费用;如果确实需要更长上下文,也可以通过调高 compaction 上限实现,只是相应请求会进入更高费率区间。
OpenAI 发言人还提到,API 里的最大输出长度依然维持在 128,000 token,没有因为这一代模型而继续上调。
至于 GPT-5.4 为什么更贵,OpenAI 给出的解释主要包括三点:首先,它在复杂任务上的综合能力提升明显,覆盖编程、电脑操作、深度研究、高级文档生成以及工具调用等多个方向;其次,这一代模型吸收了 OpenAI 技术路线图中的多项研究进展;最后,模型推理效率更高,在完成相同任务时需要的推理 token 更少。
OpenAI 同时强调,尽管GPT-5.4的价格上升了,但与不少同级别前沿模型相比,它的定价仍未脱离市场范围
普通人如何国内免费体验(不开订阅会员)
1、快速体验
手机端:微信公众号搜索“星火SparkAi助手”
电脑端:打开官网,用浏览器进入就行
https://ai.sparkaigf.com![]() http://SparkAi-新一代AIGC系统点击对话聊天 -> 新建对话 -> 切换模型 -> 搜索或下滑模型列表 -> 选择GPT-5.4相关大模型
http://SparkAi-新一代AIGC系统点击对话聊天 -> 新建对话 -> 切换模型 -> 搜索或下滑模型列表 -> 选择GPT-5.4相关大模型
2、使用说明
注册就会赠送一定量高级积分、每天签到还可以免费领取高级积分 即每天都可以免费白嫖使用
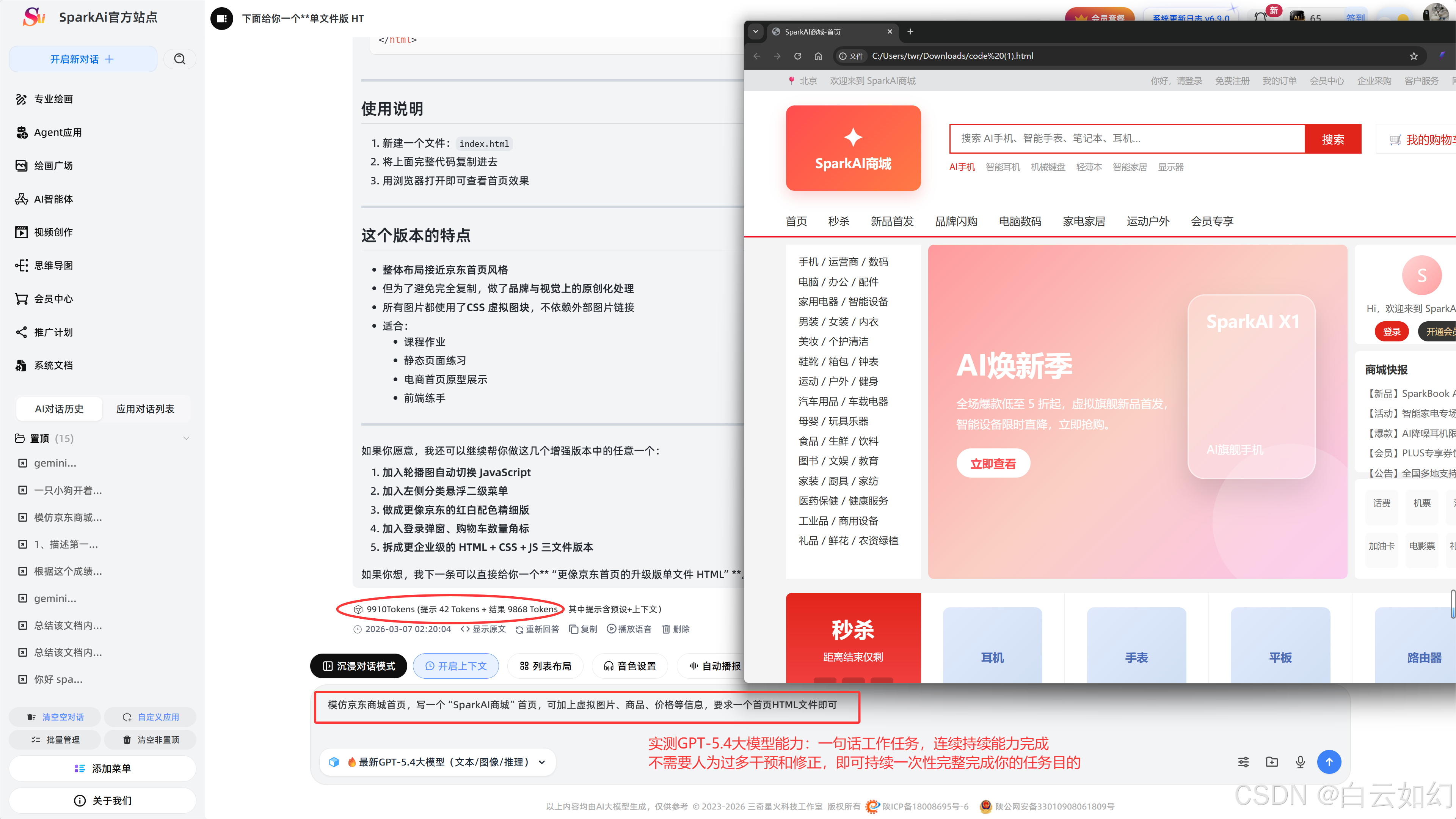
3、SparkAi系统助手实测试体验GPT-5.4大模型
实测GPT-5.4大模型能力:一句话工作任务,连续持续能力完成,不需要人为过多干预,即可持续一次性完整完成你的任务目的。
总结
这不只是一次常规更新,而是 OpenAI 对“AI 如何真正工作”的再定义
如果把 GPT-5.4 的这次升级放在一起看,会发现它的重点并不只是“更强”,而是“更接近真实工作场景”。
它不再只是一个更会回答问题的模型,而是正在向一个能推理、能写代码、会调用工具、还能直接操作电脑的通用执行体演进。对于普通用户而言,这意味着 AI 可能变得更像助手;而对于开发者和企业来说,这意味着围绕 agent 构建产品和系统的门槛正在进一步降低。
至于 OpenClaw 会不会因此被替代,现阶段还很难下结论。但可以确定的是,当模型开始原生具备电脑操作能力后,这个赛道的竞争逻辑已经发生了变化。未来比拼的,不再只是“谁能接上模型”,而是“谁能在模型能力、执行效率、安全机制和产品体验之间做出更好的整体方案”。而 GPT-5.4,显然已经把这个新阶段的门推开了。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 50
50 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)