
我把 OpenClaw 跑在本地三周后,发现它根本不是聊天机器人
如果你本身就是工程师、创作者,或者正在尝试把 AI 接进真实工作流,而不是只把它当聊天窗口,那 OpenClaw 值得你认真折腾一次。最开始我也把它当成一个 AI 工具,但真正把它接进 Telegram、Obsidian、定时任务、本地模型和内容工作流之后,我发现自己完全想错了。如果你本职是 Android 工程、系统优化、性能分析、稳定性治理,OpenClaw 最有价值的,不是“替你答一道题”,
我把 OpenClaw 跑在本地三周后,发现它根本不是聊天机器人
最近这段时间,我一直在本地重度使用 OpenClaw。
最开始我也把它当成一个 AI 工具,但真正把它接进 Telegram、Obsidian、定时任务、本地模型和内容工作流之后,我发现自己完全想错了。
它最厉害的地方,不是回答问题,而是开始替你持续工作。
它能接消息、调工具、跑定时任务、调用不同模型、沉淀长期记忆、把结果回写 Obsidian,还能把复杂任务分发给别的 Agent。你如果只把它当聊天机器人,那基本等于只用了它 20% 的能力。
对我这种既做 Android 系统性能优化、又要做内容、运营社群、维护知识库、跟进项目、写代码的人来说,OpenClaw 最值钱的地方只有一句话:
它让我第一次有了“AI 不只是回答我,而是真的在替我持续推进工作”的感觉。
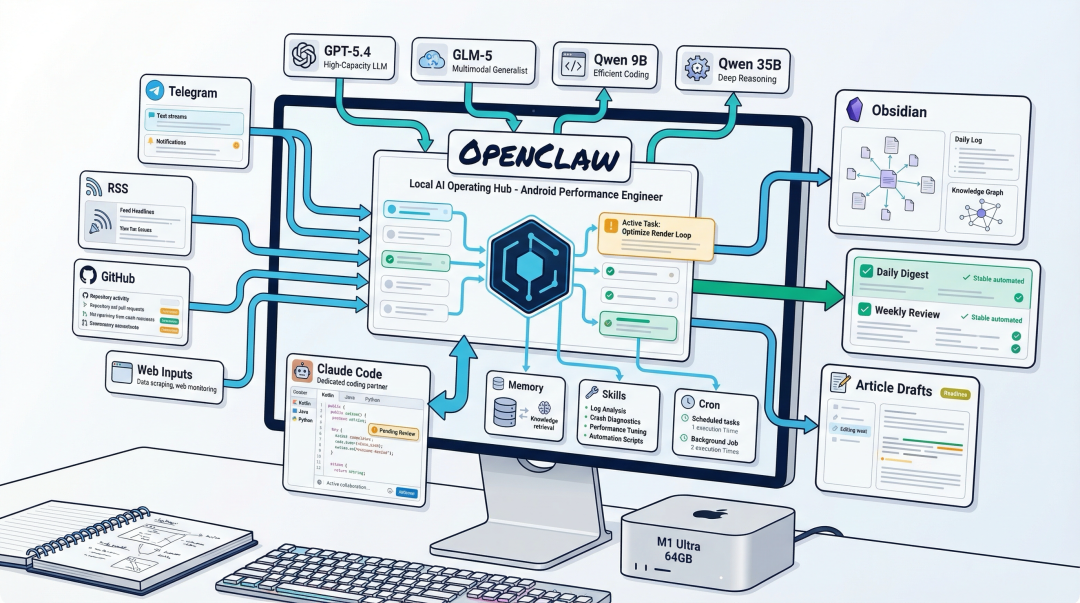
1. 我是什么时候开始真正用 OpenClaw 的?
按本地环境的初始化痕迹看,我是在 2026 年 2 月 16 日晚上开始把 OpenClaw 真正落到自己机器上的。
这不是“装来看看”的那种体验,而是一路接进自己的日常工作流:
-
• 消息入口
-
• 定时任务
-
• Obsidian 知识库
-
• 日报周报
-
• GitHub 监控
-
• 论文精读
-
• 内容素材整理
-
• 创作与复盘
所以我现在已经不把它当“一个工具”,而是把它当成:
-
• 一个本地 AI 调度层
-
• 一个定时执行系统
-
• 一个长期记忆系统
-
• 一个内容与知识的自动整理器
-
• 一个能和 Claude Code 配合工作的 AI 中枢
2. 对一个 Android 系统工程师来说,OpenClaw 到底有什么用?
如果你本职是 Android 工程、系统优化、性能分析、稳定性治理,OpenClaw 最有价值的,不是“替你答一道题”,而是帮你处理那些持续重复、跨工具、跨时间、跨上下文的工作。
我现在主要把它用在四类事情上:
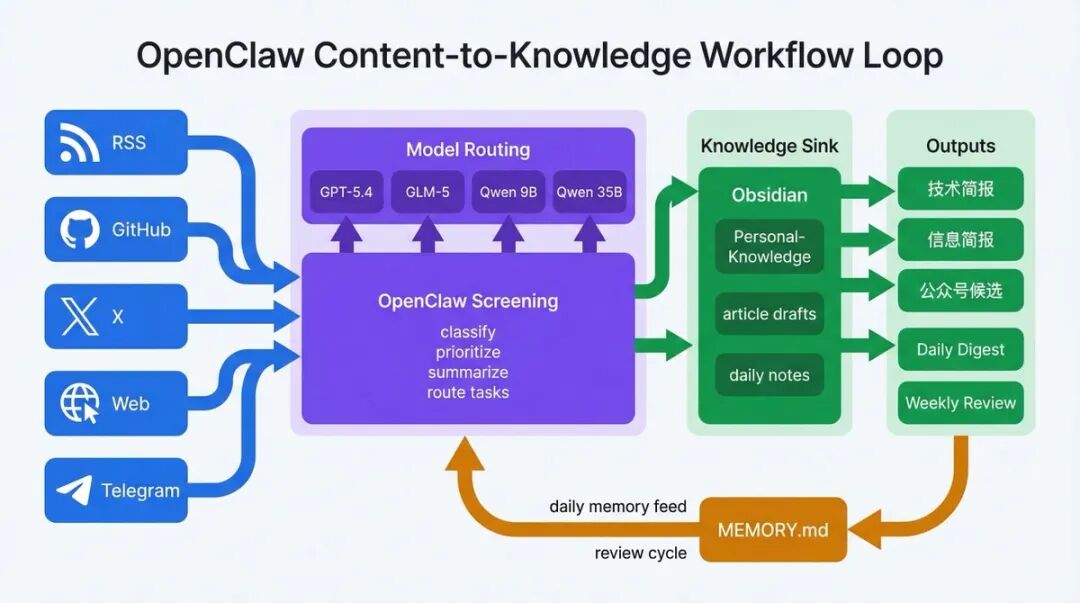
第一类:信息流自动化
比如:
-
• 每日技术简报
-
• 每日信息简报
-
• RSS 抓取
-
• 高价值内容筛选
-
• GitHub Issue / PR 监控
-
• 每日论文精读
这些事情以前不是不会做,而是太碎了,做着做着就断。OpenClaw 的价值就是把这些动作从“靠意志力”变成“靠系统默认执行”。
第二类:知识库持续整理
我平时会收很多内容:技术文章、公众号、X 长文、RSS、项目资料、自己的思考。
以前最大的问题是:
-
• 收藏了,但没整理
-
• 整理了,但找不到
-
• 找到了,也很难复用
OpenClaw 接进来之后,会持续做:
-
• 增量整理
-
• 结构修复
-
• 高价值归档
-
• 内容回顾
-
• 记忆维护
这件事对工程师特别重要,因为成长靠的不是“看过很多”,而是以后还能拿出来继续用。
第三类:日报、复盘和周检
这是很多人最容易忽略,但最有复利的一部分。
我现在让 OpenClaw 长期跑:
-
• 每日早间提醒
-
• 今天干了啥日报
-
• 日终复盘
-
• 周沉淀
-
• 项目周审
-
• 三层记忆维护
-
• 冥想 / evolution log
说白了,OpenClaw 最让我上瘾的一点就是:
它把那些“我知道很重要,但人很难长期坚持”的事情,变成了系统自动帮我做。
第四类:工程协作
它也能参与工程工作,比如:
-
• 跟踪 GitHub 仓库变化
-
• 巡检 issue / PR
-
• 整理代码上下文
-
• 调用其他 coding agent 干活
但这里我要先说结论:
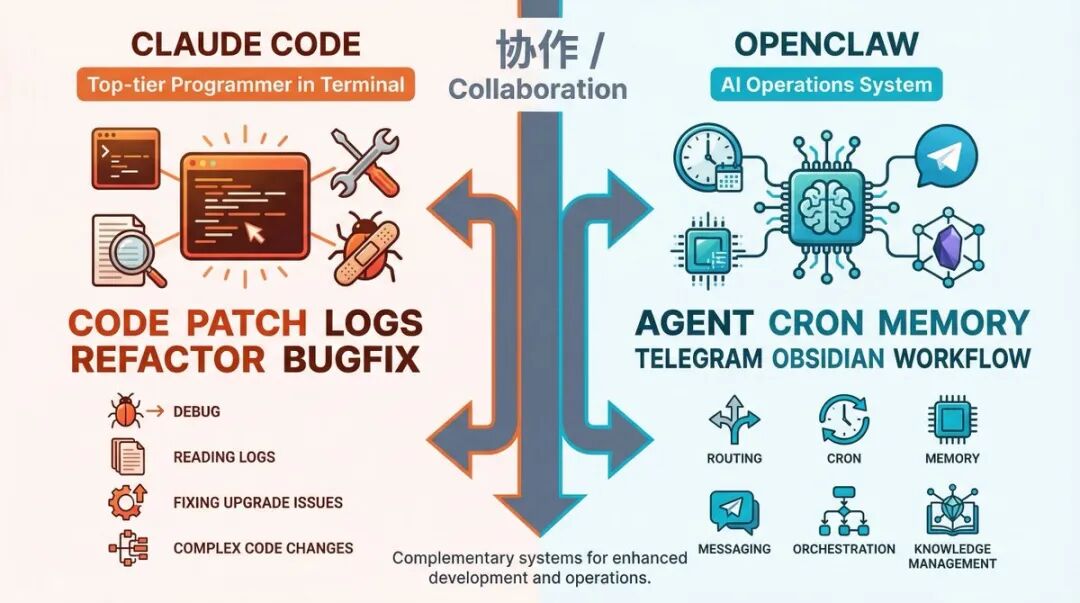
OpenClaw 不是为了替代 Claude Code,而是为了编排 Claude Code。
Claude Code 更像一个“坐在终端里的顶级程序员”;OpenClaw 更像一个“AI 运营系统”。
3. 为什么我旁边常备 Claude Code?
因为 OpenClaw 早期真的会挂。
我说得更直白一点:
-
• 升级后会报错
-
• 模型配置会出问题
-
• 定时任务会异常
-
• 某些工具链会失灵
-
• 某些路径写入会失败
-
• 旧会话和新配置不一定同步
这时候如果你只有 OpenClaw 自己,很多问题会非常烦。但如果旁边有个 Claude Code,事情就简单很多。
我的实际分工很清楚:
-
• OpenClaw:负责调度、记忆、定时、归档、消息、工作流
-
• Claude Code:负责修 bug、查日志、看报错、做复杂代码改动、升级后救火
所以我自己的真实体验是:
Claude Code 像顶级程序员,OpenClaw 像 AI 运营系统。
4. 我的本地配置是什么?
我现在这套机器是:
-
• Mac Studio
-
• M1 Ultra
-
• 64GB 内存
-
• 48 核 GPU
这套配置对本地 Agent 工作流非常舒服,因为它允许我同时跑:
-
• OpenClaw 常驻服务
-
• Ollama 本地模型
-
• Obsidian
-
• 浏览器自动化
-
• 各种脚本和知识库任务
我现在不是单模型打法,而是云端 + 本地混合分工。
模型搭配思路很简单
-
• 高质量任务上云:长文、周报、复杂总结、关键判断
-
• 高频脏活本地跑:结构化任务、巡检、批处理、日常 worker
我本地主要是这套分层:
-
• 2B:状态检查
-
• 4B:轻量巡检
-
• 9B:高频主力
-
• 27B / 35B:更重的本地任务
对我这台机器来说,9B 是最划算的日常工作马。
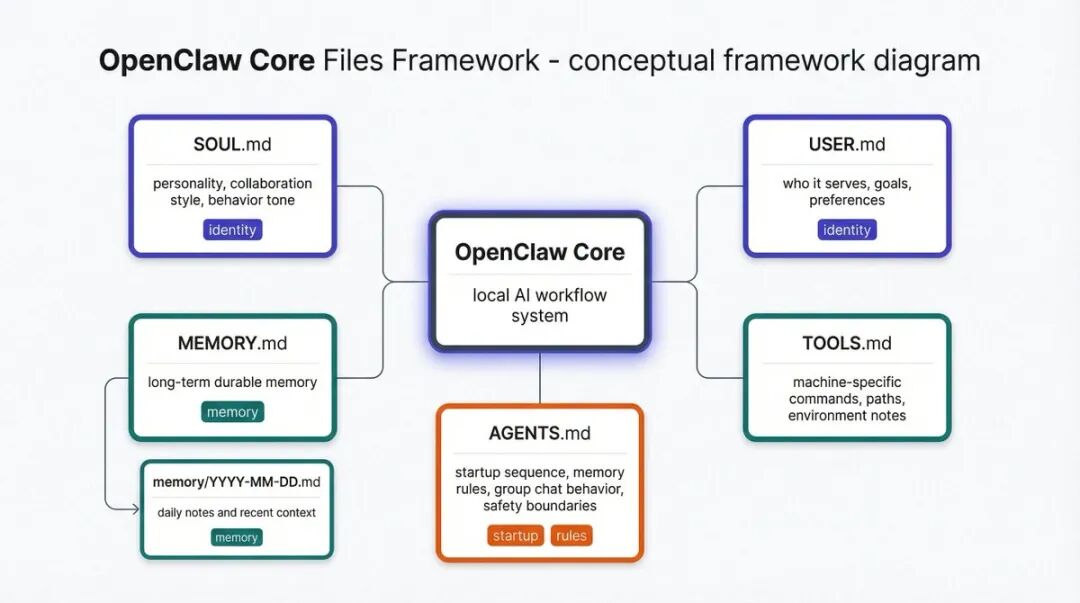
5. OpenClaw 最重要的,不只是模型,而是那几份核心文件
很多人第一次接触 OpenClaw,会把注意力放在模型、工具、命令行上。但我现在越来越觉得,它真正强大的地方,反而是那几份被文件化的规则。
我自己最看重的是这几类文件:
-
•
SOUL.md:定义它的性格、风格、做事姿态 -
•
USER.md:定义它到底在帮谁、目标是什么 -
•
AGENTS.md:定义启动流程、记忆规则、安全边界、群聊行为 -
•
MEMORY.md + memory/YYYY-MM-DD.md:一个存长期记忆,一个存每天发生了什么 -
•
TOOLS.md:记录这台机器独有的本地环境信息
所以我现在对 OpenClaw 的理解是:
它不是靠一大段系统提示词活着,而是靠一套“文件化人格 + 文件化记忆 + 文件化规则”活着。
6. Skill 机制为什么重要?
很多人把 Skill 理解成“插件”,但我觉得更准确的理解是:能力包。
一个 Skill 往往不只是多一个按钮,而是把下面这些东西一起打包了:
-
• 适合什么场景
-
• 怎么调用工具
-
• 是否依赖脚本
-
• 有哪些边界和注意事项
-
• 在什么情况下该用,什么情况下不该用
比如 Obsidian、coding-agent、RSS、技能审计这些能力,一旦装对,OpenClaw 就不再只是聊天,而是真的开始干活。
但我的建议也很明确:不要为了炫技乱装 Skill。 先装核心能力,真正跑两天,确认稳定再继续扩;涉及高权限或外联的 Skill,先审计再决定要不要上。
7. Telegram 这块,单 Agent 多群聊能用,但后期最好按职责拆
如果你只在私聊里用 OpenClaw,其实还没完全体会到它的架构价值。
它真正好玩的地方之一,是同一套系统可以接 Telegram,而且不一定只能对应一种工作方式。
方案 A:单 Agent 多群聊
优点是简单:
-
• 配置快
-
• 起步成本低
-
• 前期验证最省事
但缺点也很明显:
-
• 上下文容易串味
-
• 不同群的语气和任务容易混在一起
-
• 写作、日报、技术答疑很容易互相污染
方案 B:按职责拆成多个 Agent
这才是我现在更认可的方式。比如:
-
•
main:私聊主会话 -
•
daily:定时任务、日报、巡检、知识库类工作 -
•
writer:写作和内容精修类任务 -
• 专题 Agent:负责某个群、某条业务线或某个项目
这样做的好处是:
-
• 上下文隔离更清楚
-
• 角色边界更明确
-
• 不同群不会互相污染
-
• 后期扩展更轻松
我的建议是:前期可以单 Agent 多群聊,后期一定要按职责拆。
8. 安全不是附录,而是前置条件
这件事我非常建议一开始就讲透。
因为 OpenClaw 一旦开始接:
-
• 本地文件系统
-
• 浏览器
-
• 命令执行
-
• 外部消息入口
-
• 本地和云端模型混合调用
它就不再是一个“无害聊天框”了,而是一个真正有行动能力的系统。这个时候,安全边界一定要先立住。
我现在比较认同的几条原则是:
-
• 长期记忆要分层:像
MEMORY.md这种更私人、更稳定的信息,最好只在主会话里使用,不要在群聊上下文里乱读乱用 -
• 外部发送要谨慎:邮件、公开发帖、社交平台发布,最好默认需要确认,不要自动对外表达半成品
-
• 群聊不要越权:在群里它是参与者,不是代言人,更不是你本人
-
• Skill 不要乱装:尤其是涉及联网、执行脚本、读本地路径的能力,先审计再说
-
• 本地小模型别无脑给大权限:尤其是接网页、执行命令、读写路径时,要清楚工作区边界和工具边界
如果你后面还要接更多外部能力、浏览器自动化或者海外模型,通常还需要稳定的科学上网环境。但能力越多,越要先把边界设计好。
9. 还有一个特别关键的问题:它到底留下了什么成果?
如果文章只写“它能做什么”,读者还是容易觉得这是一套概念系统。真正有说服力的,其实是:这套系统已经在 Obsidian 里沉淀出了什么成果物。
截至我写这篇文章时,我的 Obsidian 里已经能直接看到这些成果:
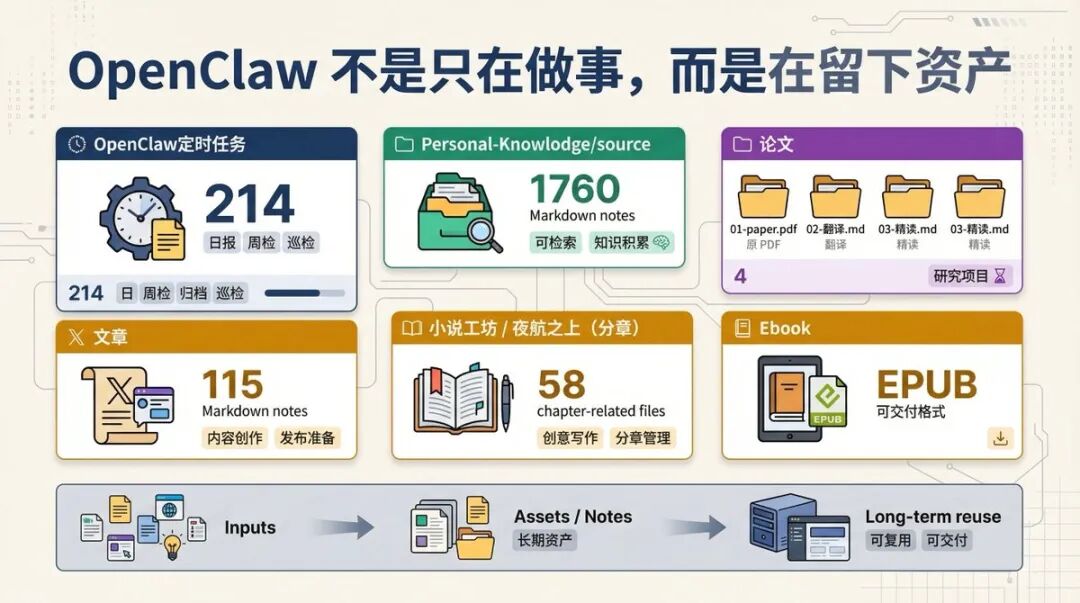
-
•
OpenClaw定时任务/下有 214 篇 Markdown,说明日报、周检、归档、巡检已经不是口号,而是持续产出 -
•
Personal-Knowlodge/source/下有 1760 篇 Markdown,知识库已经不是空目录,而是真在增长 -
•
X 文章/下有 115 篇 Markdown,高价值外部内容已经沉淀成长期素材库 -
•
论文/下有 4 个标准化论文目录,每个目录都按“原 PDF + 翻译 + 精读”来组织 -
•
小说工坊/夜航之上(分章)/下有 58 个章节相关文件,它已经进入长期创作工作流,而不只是技术任务 -
•
Ebook/里已经有实际 EPUB 成果,不只是笔记,还有可交付格式
如果你看几个具体例子,会更有感觉:
-
•
OpenClaw定时任务/每日论文精读(Android+AI)/2026-03-08-每日论文精读(Android+AI).md -
•
Personal-Knowlodge/source/2026-03-08_wechat_Android_JNI原理分析.md -
•
X 文章/2026-03-08-0800-JimProsser-My-Chief-of-Staff-Claude-Code-2029699731539255640.md -
•
论文/AI-2026-03-08-Agentic-Reasoning-Framework/01-paper.pdf + 02-翻译.md + 03-精读.md -
•
小说工坊/夜航之上(分章)/第018章-光标闪烁.md
这也是我现在最看重 OpenClaw 的地方:
它不是做完就没了,而是在不断把工作变成资产。
10. 我踩过哪些坑?
这部分非常重要,因为它决定你会不会半路放弃。
坑 1:它初期真的没那么稳
你要接受一个现实:OpenClaw 很强,但并不等于“零维护”。
我踩过的坑包括:
-
• 升级后报错
-
• 模型 allowlist 没配对
-
• 模型切换后旧会话不生效
-
• 定时任务能跑但落盘失败
-
• 外部路径权限问题
-
• 浏览器策略问题
坑 2:Node 环境不要混
我后面把运行环境统一切到了 Homebrew Node,不再混用 nvm。这个动作非常有必要,不然后面升级、重启、路径都容易乱。
坑 3:Obsidian 外部路径别乱写
这是我踩得很深的一个坑。后来我收敛成非常明确的规则:
-
• 必须绝对路径
-
• 最稳是
exec + python/pathlib落盘 -
• 不要想当然地直接
write/edit -
• 同日内容尽量追加,不要覆盖
坑 4:自动化不是越多越好
一开始很容易上头:这个也想自动化,那个也想自动化。但最后你会发现,任务太多就会带来:
-
• 重复
-
• 冲突
-
• 噪音
-
• token 成本上升
-
• 结果反而没人真正看
所以更好的策略不是“全自动化”,而是先抓最有复利的几条主线。
11. 什么样的人适合用 OpenClaw?
我觉得最适合的是三类人:
第一类:有持续输入和输出需求的人
比如:
-
• 工程师
-
• 独立开发者
-
• 技术博主
-
• 社群运营者
-
• 研究型创作者
第二类:愿意折腾工作流的人
如果你对“自动化、系统化、结构化”天然感兴趣,OpenClaw 会越用越顺手。
第三类:想把 AI 真正接进工作流的人
如果你不是只想问几个问题,而是真的想做:
-
• 持续监控
-
• 自动整理
-
• 主动提醒
-
• 定时产出
-
• 长期记忆
-
• 跨平台内容协同
那 OpenClaw 会很有用。
12. 什么样的人不太适合?
也要说实话。
-
• 只想把它当 ChatGPT 替代品的人
-
• 不想维护环境、不想看日志的人
-
• 没有持续工作流的人
这三类人不一定用不好,但大概率感受不到它真正的价值。
13. 硬件怎么推荐?
如果你问我推荐什么机器,我会分三档说:
入门档
-
• 16GB 内存
-
• 主要跑云端模型
-
• 本地只做少量辅助
实用档
-
• 32GB 内存
-
• 能跑一部分本地模型
-
• 可以承接中轻量任务
舒服档
-
• 64GB 及以上
-
• Mac Studio / 高配工作站级机器
-
• 云端 + 本地混合长期常驻
如果你真想把 OpenClaw 跑成“长期常驻、云端+本地混合、多任务并行”的系统,64GB 这一档体验会明显更稳。
14. 我现在对 OpenClaw 的最终判断
如果只让我用一句话总结,我会这么说:
OpenClaw 最迷人的地方,不是它更会回答问题,而是它开始替你持续推进工作。
对 Android 系统工程师来说,它最有价值的地方不是取代你写代码,而是帮你把这些本来散落在各处的事情串起来:
-
• 输入
-
• 整理
-
• 归档
-
• 跟进
-
• 输出
-
• 复盘
-
• 记忆
它不是零门槛工具。
它会挂,会报错,会踩坑。
但一旦你把它跑顺,你会很明显地感受到:
以前是你在推着工作流走;后来是系统在推着你往前走。
这就是我觉得它最值得折腾的地方。
结尾
如果你本身就是工程师、创作者,或者正在尝试把 AI 接进真实工作流,而不是只把它当聊天窗口,那 OpenClaw 值得你认真折腾一次。它不一定适合所有人,但一旦跑顺,带来的不是“对话效率提升”,而是工作流层面的复利。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)