
深度拆解:OpenClaw 为何疯狂烧 Token?RAG 真的死了吗?
理解Agent的上下文是怎么构建的、记忆检索是怎么工作的、钱到底烧在了哪里,能帮公司省掉推理费的人,才是Agent工程师真正值钱的地方。
OpenClaw是2026年初最火的开源AI Agent项目。它在不到两周内GitHub Star数量突破了17.5万。
但很多人兴奋地把它跑起来之后,都会意识到一个比较严重的问题,那就是,它实在是太烧token了。任务还没跑几个,自己的钱包已经顶不住了。
今天这篇文章,我想从OpenClaw的上下文架构出发,一层一层拆解Agent到底把钱烧在了哪里。
拆解完后,发现其实OpenClaw的上下文管理做的十分朴素,基本上就是尽量往模型的上下文窗口,硬塞所有的信息。
然后你会看到一个非常有意思的事实:随着OpenClaw开始解决这个烧钱的问题,OpenClaw的记忆系统进化,本质上往Agentic RAG方向靠拢。
这个发现,直接回答了一个行业里争论不休的问题,RAG到底死没死。
第一部分:OpenClaw 的上下文,到底装了什么
要理解OpenClaw为什么烧钱,你得先理解它每次调用模型的时候,到底往上下文窗口里塞了什么东西。
OpenClaw每次调LLM,上下文由四个部分组成:System prompt(含项目上下文、注入的workspace文件、skills列表、工具列表和工具schema)、会话历史、工具调用和工具返回的结果,以及compaction产生的压缩摘要。
1. System Prompt:每次调用都要付的「入场费」
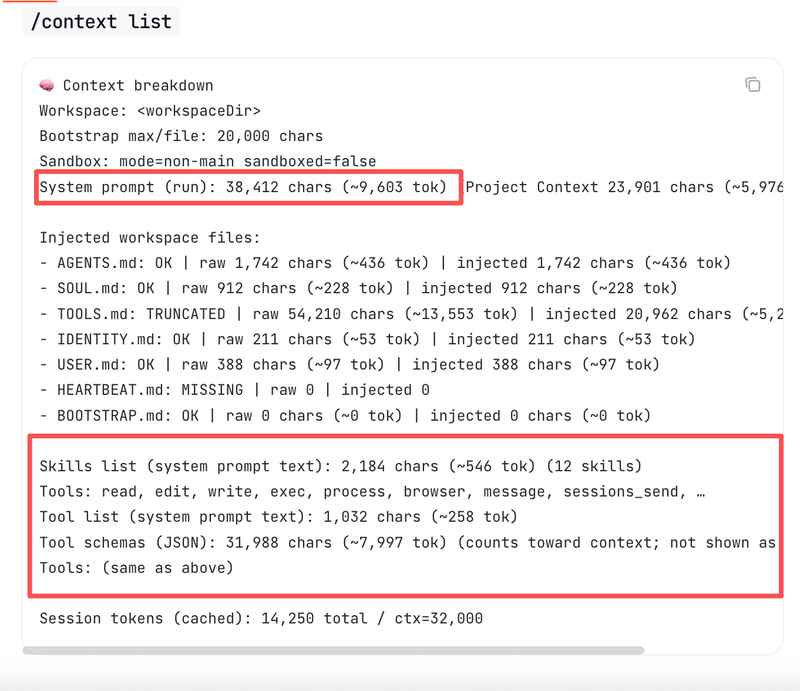
你可以直接用 /context list 指令来看看这部分的token消耗数量。
这部分消耗大约9600个token。这里消耗的token,是为了告诉模型怎么作为Agent行动,怎么使用工具、怎么推理代码、怎么和你的workspace交互。
你没有办法很大幅度的降低这部分的token,否则Agent功能就会崩掉,所以它是每次调用的固定成本。
工具schema又增加了大约8000个token。
OpenClaw能用的每一个工具,文件读写、代码执行、网页搜索等等,都需要一个JSON schema定义来告诉模型怎么调用。当你启用更多skill或者连接MCP服务器时,这个数字还会继续上涨。
光这两项,加起来就是将近1.8万token。你还没说话,「入场费」已经收了。
再看workspace文件注入: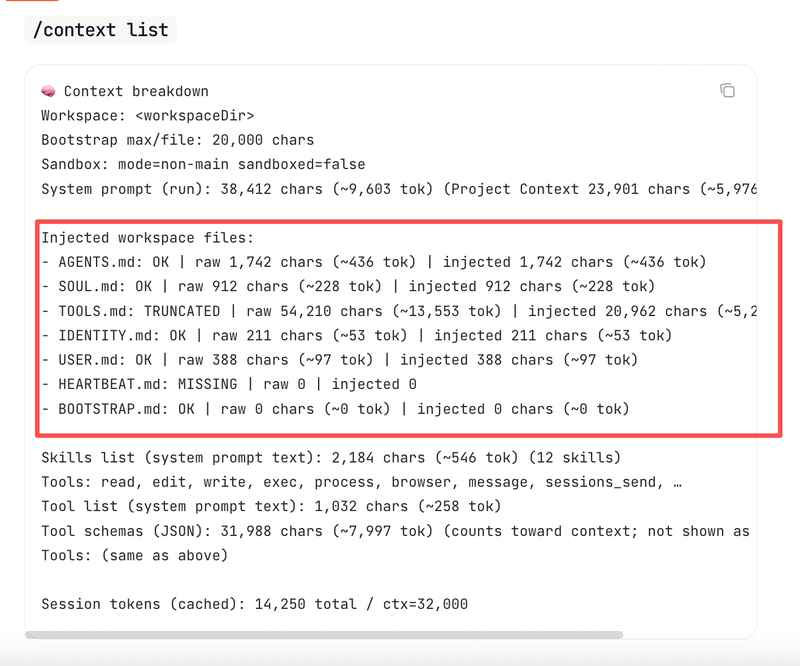
注入的workspace文件包括一系列markdown文件:
- AGENTS.md(1742字/436 token)
- SOUL.md(912字/228 token)
- TOOLS.md(原始54210字被截断到20962字/5241 token)
- IDENTITY.md(211字/53 token)
- USER.md(388字/97 token)
- 工具schema(JSON):31988字(约7997 token)
注意到没有?TOOLS.md这个文件原始有54210个字(约13553 token),但被截断到了20962字。大文件会按单文件上限被截断,默认上限是20000字。
OpenClaw还设了一个跨文件的总注入上限,默认150000字。
这说明什么?说明OpenClaw的设计者已经意识到workspace文件注入是个成本大户,所以做了截断限制。
但即便有截断,一个中等复杂度的workspace,光系统prompt部分就轻松超过14000 token。
2. Skills 列表:不是全量加载,但也不是零成本
系统prompt还包含你加入OpenClaw的Skills列表,根据Skill的规范,这个列表包含了每个Skill的名称、描述、位置。
这个列表有实际的Token开销。当然了,因为Skill是渐进式披露,所以一开始,Skill的具体Prompt不会被包含,模型只在需要的时候才去读SKILL.md。
但这部分成本也不可忽略。
具体成本是多少呢?
- 基础开销(至少有1个skill时):195字符
- 每个skill额外增加:97字符加上Skill的名称、描述、位置
粗略换算,每个skill大约消耗24个token加上你字段的实际长度。
所以如果你装了30个skill,大概额外增加1000到2000 token。不算巨大,但也不是零。
3. 会话历史:只增不减的雪球
这才是真正的坑。
每次你和OpenClaw聊天,所有历史消息都保存在 .openclaw/agents.main/sessions/ 目录下的JSONL文件里。问题是:每次新请求,OpenClaw会把整个对话历史发送给模型。
更夸张的是工具返回结果的膨胀。工具的输出结果会被永久存储在session的JSONL文件中。
一旦发生这种情况,后续的每一条消息都会拖着这些记录前进,导致Token消耗数指数级增长。
4. Compaction:安全阀,但有代价
当上下文快要爆了怎么办?OpenClaw有一个compaction机制,也就是压缩。
当session超过上下文限制时,compaction会丢弃信息,进行摘要。
解决方案是:当session接近阈值时,阈值的计算公式为:contextWindow - reserveTokensFloor - softThresholdTokens
即模型默认的上下文窗口大小减去一个最低的预留量,再减去一个提前预警缓冲量。
设置最低预留量是因为,模型进行摘要,也要消耗上下文。缓冲量相当于一个安全区,相当于一个预警。
OpenClaw会触发一个静默的agentic turn,提醒模型在compaction发生之前把持久化记忆写到磁盘上。对于200K的上下文窗口,默认设置下(20K reserve,4K soft threshold),这会在大约176K token时触发。
第二部分:记忆系统 = Agentic RAG
到这里,我们已经看到了Agent的短期记忆是怎么烧钱的。
但Agent还需要「长期记忆」,跨session的持久记忆。这才是OpenClaw架构中最有意思的部分。
OpenClaw最迷人的地方,就是它能够扮演一个对你十分了解的助手,你感觉它好像对你的一切都记得。但这个机制的实现其实特别粗暴,甚至在最初版本时,这个机制是直接靠堆积上下文进行的。
目前较新的版本才做了优化。
Markdown 文件就是 Source of Truth
OpenClaw的记忆是agent workspace中的纯Markdown文件。这些文件就是source of truth。
模型只「记住」写到磁盘上的内容。
默认的workspace布局使用两个记忆层:
- 每日日志(append-only),session启动时只加载今天和昨天的日志
- 长期策划记忆 MEMORY.md,只在主要的私有session中加载
这个设计决策是OpenClaw方案的特别之处:所有记忆都以纯Markdown文件存储在本地文件系统中。每次session结束后,AI会自动将更新写入这些Markdown日志。
我们可以打开这些Markdown文件,直接编辑它们,随时查看AI记住了什么。这些记忆对人类来说都是透明的。
检索方式:两个工具 = Agentic RAG
关键来了。这些记忆文件不是全量塞进上下文的。
OpenClaw暴露了两个工具:
memory_search:对索引片段做语义召回memory_get:针对性读取特定Markdown文件范围
这就是典型的Agentic RAG。
Agent自己决定什么时候要搜、搜什么关键词,然后把检索到的片段注入到当前的对话上下文里。不是你告诉它搜什么,是它自己判断。
混合搜索:BM25 + 向量 + MMR
检索的底层不是简单的向量匹配。而是通过混合检索进行。
- 向量搜索擅长「这意味着同一件事」的匹配,但对精确的、高信号的token(如错误字符串)很弱
- BM25正好相反:擅长精确token匹配,但不善于处理改述
混合搜索是务实的折中:同时使用两种检索信号,让「自然语言」查询和「大海捞针」查询都能得到好结果。
当向量和关键词结果都可用时,通过加权分数合并:默认权重是 vectorWeight=0.7、textWeight=0.3(归一化到和为1.0)。
结果按finalScore降序排列。
合并之后还有后处理。MMR(最大边际相关性)对结果做重排,平衡相关性和多样性,确保top结果覆盖查询的不同方面,而不是重复相同的信息。
QMD 后端:升级版本地RAG
设置 memory.backend = "qmd" 可以把内置的SQLite索引器替换成QMD:一个本地优先的搜索sidecar,结合BM25 + 向量 + 重排序。Markdown依然是source of truth;OpenClaw调用QMD进行检索。
QMD(Query Markup Documents)是Shopify创建的本地Markdown搜索引擎。
它结合三种搜索方式:BM25全文搜索处理快速关键词匹配;向量语义搜索使用本地GGUF模型找概念相似的内容;混合搜索通过Reciprocal Rank Fusion合并结果,再用本地LLM做重排序。全部本地运行,无API Key,无云依赖。
相比注入成千上万无关的token,你得到的是精准的检索:BM25做精确匹配,向量搜索做语义相似度,LLM重排做精度保证。全部本地运行,零云端成本,零数据泄露。
OpenClaw的 memory_search + memory_get + 混合搜索 + MMR + QMD,本质上就是一套完整的Agentic RAG系统,只是它被内化到了Agent的认知架构里。
为什么 RAG 不会死
讲了这么多OpenClaw的架构和成本,现在可以回答那个行业里争论不休的问题了。
2026年初,每当一个新模型发布更大的上下文窗口,社交媒体上就会冒出一波「RAG已死」的宣言。但这些宣言误解了RAG的目的,以及为什么它在AI中始终有一席之地。
OpenClaw的架构恰好给了我们一个最好的反驳案例。
理由一:最火的 Agent 自己就在用 RAG
你看到了,OpenClaw这个最火的Agent应用,在上下文管理爆炸的痛点下,依然对其记忆系统进行了RAG架构的改进。
如果RAG真的死了,为什么最成功的Agent还在用它?
理由二:成本问题
成本问题在任何情况,都是开发者需要考虑的。除非说,未来大模型的token成本无限趋近于零,否则这部分成本依然会让大部分人吃不消。
理由三:上下文窗口大了 ≠ 模型用得好了
研究一致表明,模型在远未达到其官方上下文窗口限制时就已经出现性能下降。
这就是为什么OpenClaw的memory_search只默认返回top 6条结果,每条限制在约700字符。它不是给你整个图书馆,它是给你最相关的那几页。这就是RAG的核心价值。
理由四:RAG 正在变成「上下文引擎」
RAG正在经历自己的深刻蜕变,从「检索增强生成」这一特定模式,进化为以「智能检索」为核心能力的「上下文引擎」。这个演化趋势现在已经不可逆转。
OpenClaw的整个架构,从系统prompt的workspace文件注入,到skills的懒加载,到memory_search的混合检索,到compaction前的flush。全部都是上下文工程。而上下文工程的核心,就是RAG的进化形态。
有人说得好:「声称大型LLM上下文窗口取代了RAG,就像说因为有了足够的内存就不需要硬盘了。」你的电脑有磁盘、内存和网卡,是有原因的。它们服务于不同的目的,作为一个系统一起工作。
总结
OpenClaw给我们上了一课。
它用最极致的方式验证了一件事:Agent的成本本质上是一个上下文工程问题。
系统prompt的固定税、会话历史的滚雪球、工具输出的垃圾堆积、心跳的静默消耗,所有这些成本,都指向同一个问题:你往上下文窗口里塞了多少token。
而解决这个问题的方法依然还是精准地检索和注入,这正是RAG一直在做的事情。
RAG没有死。它成为了上下文工程极其重要的一环。然后以Agentic RAG的形态,嵌入到了每一个Agent框架里。
理解Agent的上下文是怎么构建的、记忆检索是怎么工作的、钱到底烧在了哪里,能帮公司省掉推理费的人,才是Agent工程师真正值钱的地方。
转载:https://www.douyin.com/article/7612505265002401074

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 2
2 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)