
OpenClaw那么火,但又那么贵,如何降本?只看这篇
如果你正在使用 OpenClaw,一定深有体会:这个 Agent 框架强大到让人惊叹,但每次看到账单时的心跳加速也是真实的。
原文地址:https://mp.weixin.qq.com/s/hsu9Yd-BmT459kZ50FibCA
“这是我用过最无定语强大的AI工具,但高额成本让很多朋友望而却步。”
如果你正在使用 OpenClaw,一定深有体会:这个 Agent 框架强大到让人惊叹,但每次看到账单时的心跳加速也是真实的。😰
好消息是:完全可以在不牺牲性能的前提下,将成本降到原来的 1/10 甚至更低! 今天这篇指南,将用四种实战方法,带你实现"Token自由"。
💡 先搞懂:钱到底花哪儿了?
在讲省钱方法前,我们必须先理解Token的消耗逻辑。
每次你跟 OpenClaw 对话,发过去的可不只是你的问题,而是一个完整的工作包,包含:
| 组成部分 | 说明 |
|---|---|
| 1️⃣ 系统提示词 | 给 AI 的"员工手册" |
| 2️⃣ Workspace 文件 | agent.md、user tools、memory 等配置文件 |
| 3️⃣ 对话历史 | 越聊越长,雪球效应 📈 |
| 4️⃣ 工具输出 | 抓取的网络内容、日志等 |
| 5️⃣ 你的问题 | 这才是你真正想问的 |
为什么贵? 打个比方:你招聘了一个超级员工,但每次跟他说话,都要先把公司章程、岗位 SOP、员工手册全念一遍,然后再提需求。能不贵吗?😅
省钱的本质就一句话:让每轮输入变短、变干净、变得更可控。
方法一:🗂️ QMD —— 知识管理的"精准打击"
问题:传统知识库 = Token 黑洞
以前我们把笔记资料像"填鸭"一样整篇塞给大模型,导致输入 Token 爆炸。一篇长文档轻松吃掉几千 Token,问几个问题就破产了。💸
解决方案:本地索引 + 语义检索
QMD(Queryable Markdown Database)是 Shopify 联合创始人兼 CEO Tobias Lütke (Tobi) 开发的本地语义搜索引擎。它的核心逻辑是:
“不再读全库,只读最相关的那几段。”
核心价值:
-
不要把整个文件塞给 AI,而是先用本地搜索找到最相关的片段(通常只有 2-3 句话),再把这些精准内容传给 AI
-
解决传统记忆系统把整个 MEMORY.md 文件直接塞进上下文导致的"上下文爆炸"问题
技术原理:
-
基于 TypeScript + Bun 开发,使用 node-llama-cpp 运行本地模型
-
三层混合检索:BM25 全文搜索 + 向量语义搜索 + LLM 重排序
-
所有模型在本地运行(GGUF 格式),完全离线
工作原理(两步走):
第一步:Update 索引刷新 🔍
-
自动检测哪些文件新增、修改、删除了
-
更新分段路径和元数据(相当于更新目录)
第二步:向量更新与投射 🎯
-
只把新增/变化的片段生成向量
-
投射到本地向量数据库
-
提问时计算向量相似度,提取最相关的片段
关键优势:索引建立和检索都在本地完成,不消耗云端 Token!把"读所有文件"的成本转化为"本地计算"成本。💪
实际效果:
-
📊 Token 削减:60-97%(平均 95% 以上)
-
⚡ 响应速度提升:5-50 倍
-
💰 成本降低:90-99%
-
🎯 精准度:93%(纯语义搜索仅 59%)
安装指南(超简单)
(1)安装Bun(Windows环境最好选Linux Shell安装,将OpenClaw、Bun、Qmd都安装在这个环境下)
Bun 是一款集 JavaScript/TypeScript 运行时、打包工具、测试工具和包管理器于一体的高性能工具,旨在替代 Node.js、Webpack、Jest 和 npm/yarn/pnpm 等工具,大幅提升开发和运行效率。
# 在PowerShell中执行以下命令(以管理员身份运行更佳)
powershell -c "irm bun.sh/install.ps1 | iex"
# 检查Bun版本,确认安装成功
bun --version
(2)用bun安装qmd
# 1. 安装 QMD
bun install -g @tobilu/qmd
# 2. 配置 openclaw.json
{
"memory": {
"type": "qmd",
"indexPath": "./qmd_index"
}
}
# 3. 重启网关,完成!
💰 预算控制三件套
在 openclaw.json 的 limit 字段下,有三个精准控制阀:
| 参数 | 作用 | 建议值 |
|---|---|---|
maximum_results |
最多注入几段 | 3-5 段 |
maximum_item_chars |
每段允许多长 | 500-1000 字符 |
maximum_injected_chars |
每轮总注入上限 | 2000-3000 字符 |
效果对比:
-
❌ 传统方式:上传 10 篇长文 ≈ 15,000 Token/轮
-
✅ QMD 方式:只传 3 个相关片段 ≈ 800 Token/轮
-
节省率:95%+ 🎉
关于QMD的安装配置请参考:https://2048ai.net/698a7f140a2f6a37c590f45b.html
方法二:❤️ 心跳本地化 —— 别让"监工"变成"吞金兽"
什么是心跳(Heartbeat)?
心跳是 OpenClaw 的定时唤醒机制。简单说,就是按你设置的频率(比如每 30 分钟)把 Agent 叫醒一次,让它:
-
读取
heartbeat.md清单(我的文件路径为"C:\Users\seed\.openclaw\workspace\HEARTBEAT.md") -
检查是否需要维护、提醒或执行任务
- 没事就输出"OK",有事就去干活
典型应用场景:
-
🎯 长期任务监工:防止 AI 做一步就"歇菜",定期刺激它继续推进
-
⏰ 定时提醒:日程管理、截止日期预警
-
🔄 状态维护:检查系统健康、同步数据等
为什么心跳是隐形杀手?
每次心跳都是完整的 Agent 回合,输入包含:
-
系统提示词
-
Workspace 文件(尤其是 memory.md 和 agent.md,可能很大!)
-
对话历史
-
心跳清单和提示词
算笔账:
-
心跳频率:30 分钟/次
-
每月心跳次数:1,440 次
-
每次输入 3,000 Token(保守估计)
-
每月仅心跳就消耗:432 万 Token 😱
输出可能只有"OK"两个字,但输入却是长篇大论——这买卖太亏了!
解决方案:本地小模型跑心跳
核心原则:心跳只用来"触发",不执行复杂任务。这种"低智商"任务完全可以用本地小模型搞定!
操作步骤:
1. 安装 Ollama(本地大模型运行环境)
# macOS/Linux
curl -fsSL https://ollama.com/install.sh | sh
# Windows 去官网下载安装包
2. 选择适合的本地模型(根据电脑配置)
| 电脑内存 | 推荐模型 | 特点 |
|---|---|---|
| 8GB | Qwen 2.5 3B | 轻量快速 |
| 16GB | Qwen 2.5 7B | 性价比之王 |
| 32GB+ | Qwen 2.5 14B | 更稳定智能 |
# 下载模型(示例)
ollama pull qwen2.5:7b
3. 配置 OpenClaw 使用本地模型跑心跳
在 openclaw.json 中:
{
"heartbeat": {
"model": "ollama://qwen2.5:7b",
"interval": 1800,
"tasks": ["check_status", "send_reminders"]
}
}
成本对比:
-
❌ 云端 GPT-4 跑心跳:$0.03/次 × 1,440 次 = $43.2/月
-
✅ 本地 Qwen 7B:电费几乎可以忽略 ≈ $0/月
-
节省率:100%(当然,电脑得开着 😄)
方法三:💳 能用订阅就别走 API —— 厂商政策的"漏洞"
残酷的现实:API 用量 = 账单刺客
很多厂商对 OpenClaw 的使用有限制:
-
❌ Anthropic (Claude):严禁订阅用于 OpenClaw
-
❌ Google (Gemini):同样禁止
-
✅ OpenAI:因为收购了 OpenClaw,目前仍然开放 🎉
真实案例:
我用 MiniMax API 一天花 $30,如果换成 Anthropic 最新的 Claude 3.5 Opus,同样的用量要 $500/天!一个月就是 $15,000,够买辆车了。🚗💨
订阅 vs API 的成本差异
| 使用方式 | GPT-4o | Claude 3.5 Sonnet | 适合场景 |
|---|---|---|---|
| API 用量 | $0.005/1K Token | $0.003/1K Token | 企业级稳定需求 |
| 订阅制 | $20/月 无限量 | $20/月 有额度限制 | 个人/小团队日常使用 |
关键洞察:如果你不是追求极致稳定的企业用户,订阅制的性价比碾压 API。
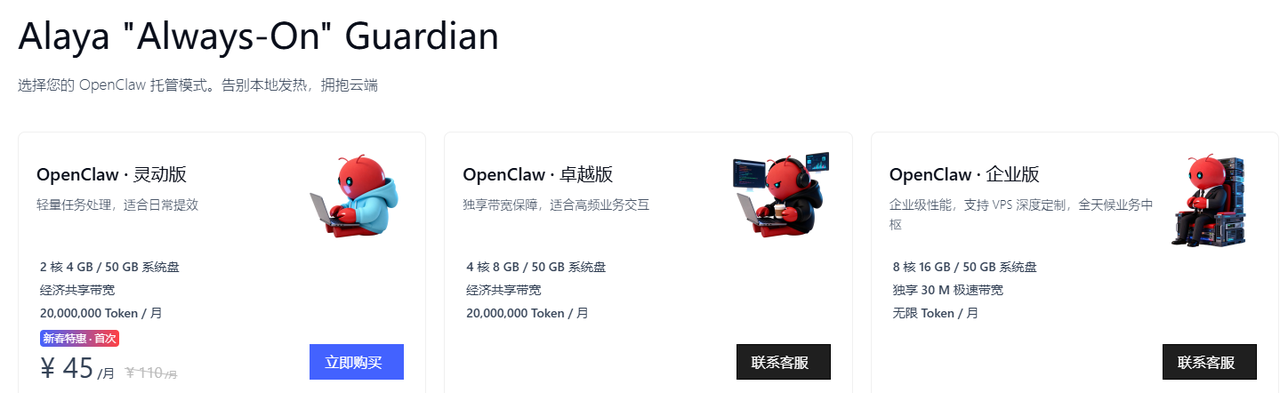
这里插入一个小小的广告,国内用户可以考虑使用AlayaNeW的托管模式的OpenClaw,也是一种订阅方式,性价比杠杠的,首月45元,后续110元/月:https://www.alayanew.com/product/openClaw
方法四:🔍 成本体检 —— 让 OpenClaw 给自己"开刀"
这是最定制化但也最有效的方法:让 OpenClaw 生成一份成本体检报告,找出隐藏的 Token 浪费。
如何生成体检报告?
直接问你的 OpenClaw:
“请给我生成一份成本分析报告,列出消耗 Token 最多的 Top 10 任务,用百分比展示。找出不合理的地方,告诉我哪些任务可以优化。”
常见"不合理"发现
根据经验,新手使用 OpenClaw 时,通常有这些成本陷阱:
| 问题类型 | 典型案例 | 优化方案 |
|---|---|---|
| 轻任务重上下文 | 查个天气却携带了 5000 字的对话历史 | 清空无关历史,使用新会话 |
| 轮询代替事件 | 每 10 分钟检查一次邮件,而不是收到邮件时触发 | 改成 Webhook 事件驱动 |
| 过度使用大模型 | 简单格式化任务也用 GPT-4 | 换 GPT-3.5 或本地模型 |
| Memory 膨胀 | memory.md 累积到 10 万字从不清理 | 定期归档,使用 QMD |
| 工具输出冗余 | 抓取网页时保留全部 HTML 而非正文 | 配置内容提取规则 |
优化双维度
流程维度:
-
轮询任务 → 事件触发(If A Then B)
-
长上下文 → QMD 精准检索
-
重复任务 → 缓存结果
模型维度:
-
复杂推理 → GPT-4/Claude 3.5
-
日常任务 → GPT-3.5/本地模型
-
心跳触发 → 本地小模型(Qwen/Llama)
实战对话示例
你:分析下我最近一周的成本消耗。
OpenClaw:📊 成本体检报告
-
Top 1:心跳检查(35%)→ 建议改用本地模型
-
Top 2:网页抓取后的全文分析(28%)→ 建议用 QMD 只传摘要
-
Top 3:每日新闻总结(20%)→ 建议换 GPT-3.5
-
Top 4:代码审查(15%)→ 保持现状
-
异常发现:有个任务每 5 分钟轮询一次 API,建议改为 Webhook
你:帮我把心跳改成用本地 Qwen 7B 运行。
OpenClaw:✅ 已更新配置,预计每月节省 $40+
🎯 总结:四招实现 Token 自由
| 方法 | 核心操作 | 节省幅度 | 难度 |
|---|---|---|---|
| 1. QMD | 本地索引 + 语义检索 | 90-95% 知识库 Token | ⭐⭐ |
| 2. 心跳本地化 | 本地小模型跑定时任务 | 100% 心跳成本 | ⭐⭐⭐ |
| 3. 订阅优先 | 用订阅代替 API | 80-90% 基础成本 | ⭐ |
| 4. 成本体检 | 让 AI 自我分析优化 | 20-50% 隐藏浪费 | ⭐⭐ |
组合使用效果最佳:
假设原来每月花费 $200
QMD 节省 $60(知识库部分)
心跳本地化节省 $40
订阅制节省 $80
体检优化节省 $20
新账单:$10-20/月 🎊
🚀 立即行动清单
今天就能做的:
-
检查
openclaw.json,确认是否在用 API 还是订阅 -
安装 QMD,把知识库从"填鸭"改成"精准投喂"
-
让 OpenClaw 生成你的第一份成本体检报告
本周完成的:
-
安装 Ollama,下载 Qwen 7B 模型
-
把心跳任务迁移到本地模型
-
清理膨胀的 memory.md 和对话历史
最后想说:OpenClaw 的强大值得被更多人体验,不应该被成本门槛阻挡。希望这篇指南能帮你卸下"Token焦虑",真正释放 AI Agent 的潜力。
如果你成功降低了成本,或者有其他省钱妙招,欢迎在评论区分享!👇
觉得有用?别忘了点赞、收藏、转发给还在被账单困扰的朋友~
保持关注,我们下期再见! 👋✨

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)