
OpenClaw - 01 打造高效的个人助手必备的配置调整
很多人在部署完 OpenClaw 并成功对接 Discord 或 Telegram 后,发现它能正常对话就觉得“大功告成”了。但事实上,默认状态下的 OpenClaw 仅发挥了其不到 20% 的潜力。剩下的 80%,隐藏在那些你可能从未深入触碰过的配置文件与架构设计中。
文章目录
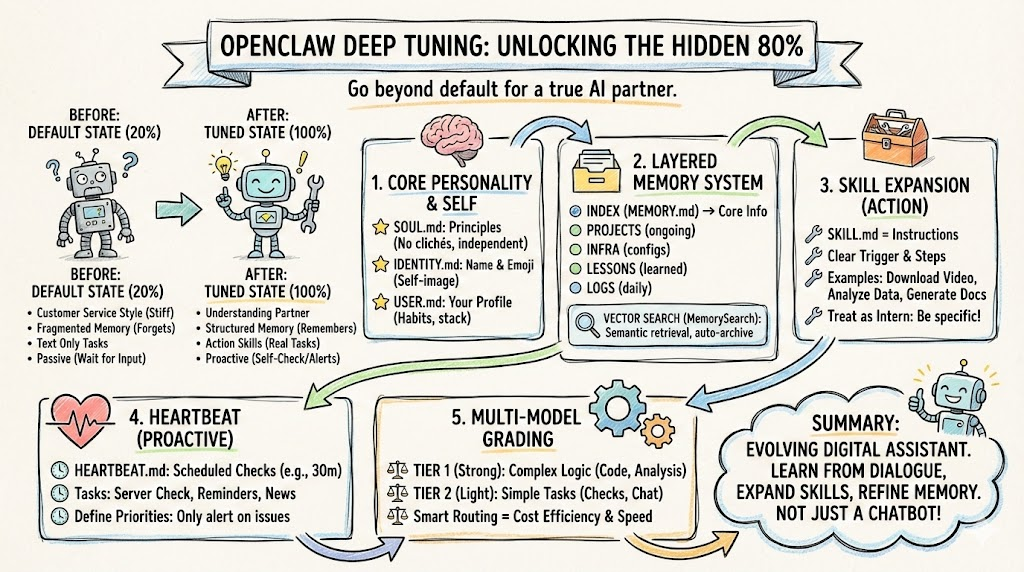
很多人在部署完 OpenClaw 并成功对接 Discord 或 Telegram 后,发现它能正常对话就觉得“大功告成”了。但事实上,默认状态下的 OpenClaw 仅发挥了其不到 20% 的潜力。剩下的 80%,隐藏在那些你可能从未深入触碰过的配置文件与架构设计中。
本文将深入探讨如何通过人格设定、分层记忆体系构建以及 Skill 扩展,对 OpenClaw 进行深度调教,让它真正成为一个懂你、有记忆、且具备实战能力的 AI 伙伴。
一、 为什么要调整配置?
在开始动手之前,我们先通过对比来看看调整配置前后的显著差异:
| 维度 | 默认状态 | 深度调整后 |
|---|---|---|
| 回复风格 | 充满“客服味”,话术僵硬 | 像一位了解你习惯的默契搭档 |
| 记忆能力 | 对话是碎片化的,经常“失忆” | 记得上周的讨论,甚至能查阅历史教训 |
| 任务执行 | 仅限于文本对话 | 具备下载视频、查股票、巡检服务器等实战技能 |
| 主动性 | 问一个答一个,完全被动 | 能够定期自检并在关键时刻主动提醒 |
二、 核心人格注入:构建 AI 的“自我意识”
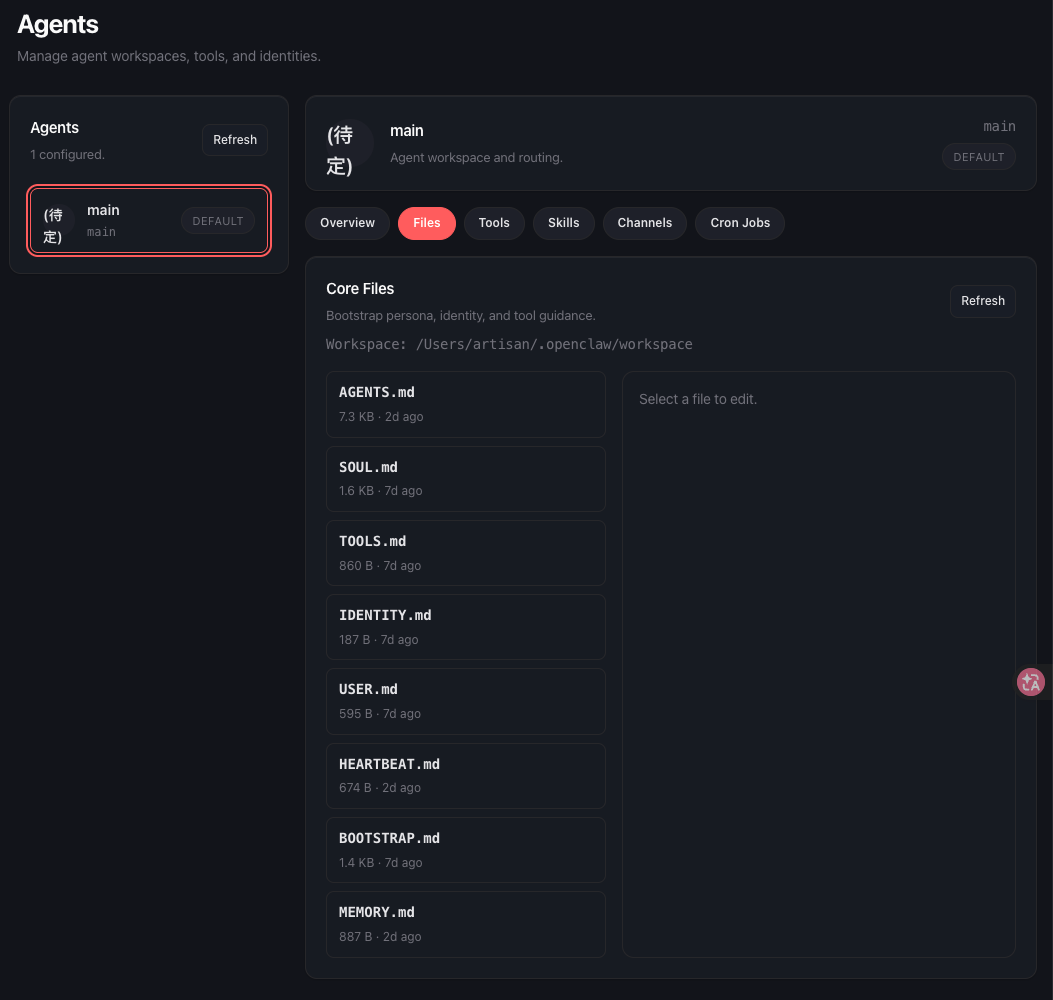
OpenClaw 的 workspace 目录下有三个定海神针般的文件,它们决定了 AI “是谁”以及“如何与你相处”。
1. SOUL.md:赋予灵魂与原则
默认的 SOUL.md 通常是空模板,这导致 AI 往往倾向于扮演标准的 AI 助手。通过定义核心原则,你可以彻底改变它的语言风格。
- 示例配置:
# 核心原则
- 拒绝陈词滥调:别说"很高兴帮助您",直接进入正题。
- 独立思考:允许持有观点和偏好,而非绝对中立。
- 优先自研:先尝试自行检索或推理,无法解决再向用户提问。
- 效率至上:根据任务复杂度调整篇幅,简洁且精准。
2. IDENTITY.md:确立身份认同
给你的 AI 起一个名字并分配一个 Emoji。这不仅是形式主义,更有助于 AI 在多轮对话中保持一致的“自我认知”。
3. USER.md:建立用户画像
在 USER.md 中详细记录你的技术栈、时区和沟通习惯。
- 作用: 避免 AI 在你深夜休息时发送非紧急通知,或者向一个写 Python 的开发者推荐 Java 的库。
三、 打造分层记忆体系:让 AI 永不遗忘
这是提升 AI 体验最关键的一环。很多人错误地将所有信息堆叠在 MEMORY.md 中,导致其变成无法阅读的流水账。
1. 结构化记忆设计
建议采用分层记忆架构,让 AI 在检索信息时更加高效:
- MEMORY.md (索引层):仅存放最核心信息及指向其他文件的索引,不堆砌细节。
- memory/projects.md (项目层):记录当前正在进行的各个项目状态与待办事项。
- memory/infra.md (基础层):存储服务器配置、常用 API 地址等速查信息。
- memory/lessons.md (经验层):归纳踩过的坑与技术方案的优劣评价。
- memory/YYYY-MM-DD.md (日志层):记录每日发生的具体事项。
2. 引入向量语义检索 (MemorySearch)
通过配置 memorySearch,AI 无需翻遍日志,即可通过语义匹配找到精准的回忆。
-
配置参考: 在
openclaw.json中配置 embedding API(推荐使用 SiliconFlow 的免费 bge-m3 模型)。"memorySearch": { "enabled": true, "provider": "openai", "remote": { "baseUrl": "你的embedding API地址", "apiKey": "你的key" }, "model": "BAAI/bge-m3" } -
自动归档: 开启
compaction.memoryFlush,当上下文接近上限时,AI 会自动将关键信息写入日志,防止重要记忆丢失。
四、 Skill 扩展:让 AI 走出对话框
OpenClaw 的强大之处在于其可扩展的 Skill 系统。每一个 Skill 本质上是一个包含 SKILL.md 的文件夹,AI 会根据你的指令按图索骥地执行。
1. 常见的实战 Skill 案例
https://github.com/hesamsheikh/awesome-openclaw-usecases
- 视频下载:识别链接并自动调用脚本下载。
- PPT/文档生成:根据提纲直接产出格式化文件。
- 金融分析:调用量化接口分析股票趋势。
- 自动化摘要:每日定时抓取并总结行业热点。
2. 如何编写高质量的 Skill
https://github.com/VoltAgent/awesome-openclaw-skills
编写 Skill 时,请将 AI 视为一个**“高智商但没经验的实习生”**:
- 清晰度第一:在
SKILL.md中明确写出触发条件、具体的执行步骤以及预期的输出格式。 - 消除模糊性:模糊的指令会导致 AI 执行结果不稳定。越细致的流程指引,产出越可靠。
五、 Heartbeat 心跳:让 AI 从“被动”转向“主动”
大多数 AI 助手是“问答式”的,你不说话,它就永远静默。OpenClaw 的心跳机制打破了这种僵局,赋予了 AI 时间感。
1. 工作原理
OpenClaw 默认每隔一段时间(通常为 30 分钟)会向 AI 发送一个心跳信号。默认状态下,AI 只会简单回复 HEARTBEAT_OK,不执行任何操作。
2. 激活主动性
要让心跳发挥作用,你需要修改 HEARTBEAT.md。你可以通过这个文件告诉 AI,每次“心跳”时它应该检查哪些事项。
-
示例应用场景:
-
服务巡检:每小时检查一次你的个人网站或 API 是否在线,宕机则立即在 Telegram 报警。
-
任务提醒:检查
memory/projects.md中的待办事项,是否有即将到期的任务。 -
新闻简报:在每天固定的时间点(通过计算心跳次数或读取系统时间),自动抓取科技资讯并推送摘要。
-
调教建议:在
HEARTBEAT.md中定义清晰的优先级。告诉 AI 只有发现“异常”或满足“特定时间点”时才主动发消息,避免变成骚扰机器。
六、 多模型分级:性能与成本的最优解
在复杂的工作流中,如果所有任务都调用顶级模型 ,成本会迅速飙升;如果全用廉价模型,任务成功率又无法保证。
1. 核心思路
OpenClaw 支持针对不同复杂度的任务分配不同的模型。
- 强模型(Tier 1):处理逻辑复杂、代码编写、深度长文本分析等任务。
- 轻量模型(Tier 2):处理心跳巡检、简单的格式转换、闲聊或初步的信息筛选。
2. 配置实现
在 openclaw.json 中,你可以通过配置不同的 provider 和 model 来实现分级。
- 智能路由:你可以设定当调用特定 Skill 时才激活强模型。例如,日常心跳检测使用 DeepSeek-V3(极低成本),而当你发送“分析这段架构代码”时,系统自动路由至 Claude 4.5。
- Embedding 分级:对于记忆检索(Memory Search),推荐使用专门的 Embedding 模型(如 SiliconFlow 提供的免费
bge-m3),这比直接调用通用大模型的 Embedding 接口响应更快且零成本。
七、 总结:持续进化的工作流
调教 OpenClaw 不是一蹴而就的,而是一个持续迭代的过程。
- 从对话中学习:利用
compaction机制让它自动总结对话教训。 - 按需扩展:当你发现某个操作频繁出现时,就为其编写一个 Skill。
- 精简索引:定期手动清理
MEMORY.md,保持索引层的纯净。
通过上述调整,你的 OpenClaw 将不再是一个只会聊天的机器人,而是一个真正懂你、能帮你处理复杂事务的数字助手。


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 50
50 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)