
OpenClaw × PaddleOCR:开箱即用!将文档解析 Skill 能力注入你的 Agent 工具
同时, PaddleOCR 被封装为标准化 Skill 后,它能够被 Agent 动态调度与调用,更好参与系统的工具决策流程,被复用于不同的业务工作流,以及与其他 Skill 灵活组合,形成更强大的复合能力。这是一次能力形态的全面升级:PaddleOCR 从一个独立的 SDK 或 API 服务,转变为可编排、可组合、可复用的标准化 Skill 节点。——仅需直接在 OpenClaw 的标准化框架内

如果你正关注 Agent 基础设施与工具编排的最新动态, OpenClaw 很可能是你近期的关注焦点。它正在定义一种新范式:可组合的 Skill —— 模型不再通过孤立 API 调用,而是通过标准化能力节点,像组件一样拼接出完整的智能工作流。在这一生态中,文档解析成为关键的高频能力入口。无论是知识入库、流水线处理、RAG 数据准备还是复杂内容理解,都始于精准的 OCR 与版面分析。
现在,我们正式宣布:PaddleOCR 文档解析 Skill 正式上架 ClawHub!大家期待已久的重要能力节点已经就位!
开发者可以在 OpenClaw 中直接调用 PaddleOCR,将图像或 PDF 的解析与结构化能力,无缝嵌入 Agent 工作流与自动化管线。这是一次能力形态的全面升级:PaddleOCR 从一个独立的 SDK 或 API 服务,转变为可编排、可组合、可复用的标准化 Skill 节点。
Skill 直达地址 👉
https://clawhub.ai/Bobholamovic/paddleocr-doc-parsing

开箱即用
解锁文档智能新场景
传统集成 OCR 能力往往需要部署推理服务、管理环境依赖、封装接口、处理数据转换等大量工程精力。而在 ClawHub 的 Skill 编排范式下,这些成本被大幅降低。PaddleOCR 可以作为一个标准的、可被直接调用的能力节点,无缝融入你的智能系统:
-
成为 Agent 的“眼睛”,使其真正具备阅读和理解文档的能力;
-
作为自动化流水线的核心组件,处理各类文档输入;
-
充当 RAG 流程的高质量数据摄取入口,提升知识库构建效率;
-
扮演知识抽取流水线的关键模块,从文档中直接提取结构化信息。
文档,从此不再是需要复杂预处理的外部数据,而转变为智能系统内可被直接消费的结构化数据资产。
该 Skill 基于 PaddleOCR 文档解析 API 构建,凭借最新多模态文档解析模型 PaddleOCR-VL-1.5,针对实际业务场景提供以下核心能力:
-
多格式支持:支持 PDF、JPG、PNG、BMP、TIFF 等。
-
版面分析:自动检测文本、表格、公式、标题等版面元素。
-
多语言识别:覆盖超过 110 种语言。
-
结构化输出:输出保留文档层级与语义的 Markdown 格式。

快速上手
如何在 ClawHub 中调用 PaddleOCR 文档解析 Skill
1. 安装 OpenClaw(需安装 npm):
npm install -g openclaw@latest更多安装方式可参考 OpenClaw 官网:
https://openclaw.ai/
2. 安装 ClawHub 客户端:
npm i -g clawhub更多安装方式可参考 ClawHub 官网:
https://docs.openclaw.ai/tools/clawhub
3. 使用 ClawHub CLI 安装 PaddleOCR 文档解析 skill:
clawhub install paddleocr-doc-parsing4. 修改 ~/.openclaw/openclaw.json,配置 PaddleOCR 文档解析 skill:
"skills": { ... "entries": { "paddleocr-doc-parsing": { "enabled": true, "env": { "PADDLEOCR_API_URL": "<API URL>", "PADDLEOCR_ACCESS_TOKEN": "<访问令牌>" } ... } } }其中,API URL 与访问令牌的获取方式如下:
a. 访问 PaddleOCR 官方网站:
https://www.paddleocr.com
b. 点击【API】
c. 选择【PaddleOCR-VL-1.5】
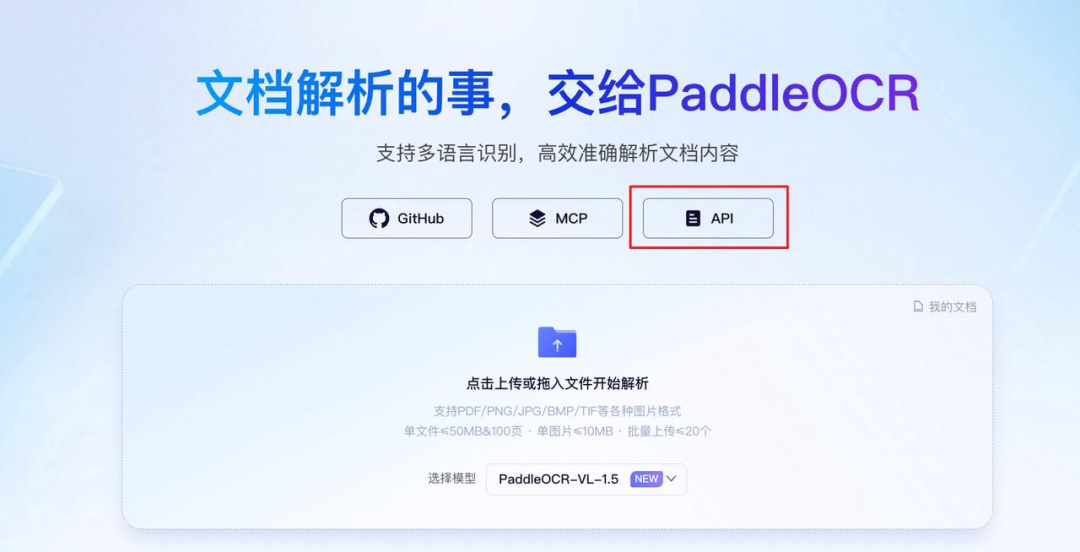
d. 打开示例代码,复制其中的 【TOKEN】(访问令牌) 和 【API_URL】
(填写PaddleOCR官方网站访问令牌-用于接口鉴权,支持申请每天免费解析数万文档页数)
e. 配置 OpenClaw 并启动网关服务:
openclaw onboard --install-daemonf. 在 OpenClaw 中使用 PaddleOCR 文档解析 skill。以下是使用例子:
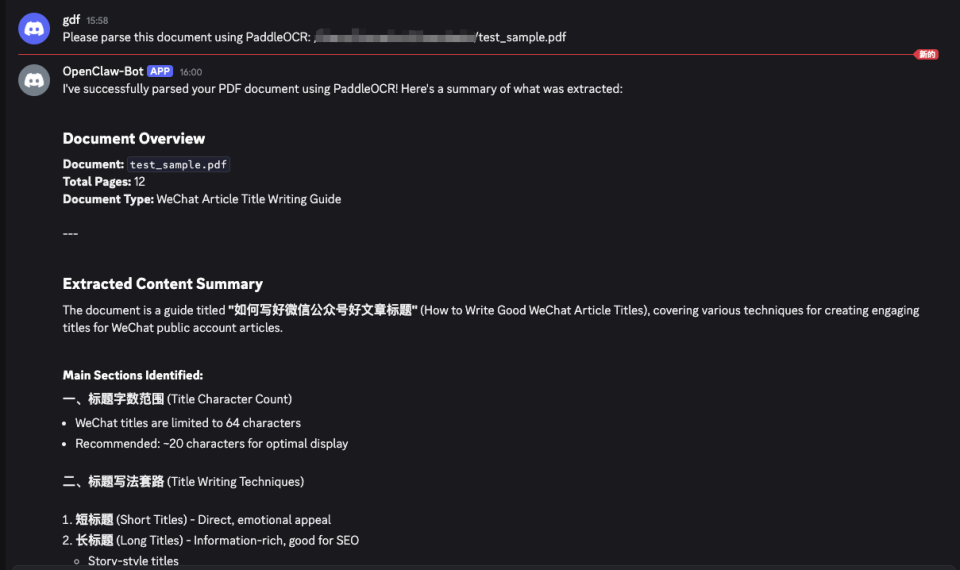
本次在 ClawHub Skill 的上架,将为你的项目集成业界领先的 OCR 能力。无需部署,无需封装,即刻开发——仅需直接在 OpenClaw 的标准化框架内,以极简配置调用 PaddleOCR,用更轻量、更标准化的方式,快速构建属于你的文档智能链路。
你能通过 PaddleOCR Skill 迅速实现:
-
快速集成:无需自建与维护 OCR 服务,即可将各类文档输入快速接入业务流。
-
无缝编排:解析能力成为标准化节点,可与检索、存储、决策等其他 Skill 协同工作,构建复杂逻辑。
-
稳定高质量输出:直接输出保留语义结构的 Markdown,显著降低后续处理成本,提升数据可索引性与可追溯性。
进入你工作流的不再是原始图像或杂乱文本,而是自带结构、可供下游任务直接使用的结构化数据。这对于知识库构建、自动化报告处理、企业文档智能分析与 RAG 数据准备等场景,能显著提升开发效率与系统能力。同时, PaddleOCR 被封装为标准化 Skill 后,它能够被 Agent 动态调度与调用,更好参与系统的工具决策流程,被复用于不同的业务工作流,以及与其他 Skill 灵活组合,形成更强大的复合能力。
基于此,文档解析从一个离线的、单点的预处理步骤,转变为一个可持续参与系统智能循环的核心能力组件。

能力已就绪,等你来玩转!现在就来试试 PaddleOCR Skill,在 PaddleOCR 广阔的开源生态里尽情发挥,一起创造更智能、更好玩的下一代应用吧!
-
关于 OpenClaw
OpenClaw 是一款免费开源的自主 AI Agent 软件,支持通过接入大语言模型执行自动化任务,并通常以消息平台聊天界面作为交互入口。其代理可在本地运行,连接各类大模型驱动跨服务工作流,并持久化配置与交互历史以实现连续行为。项目在 2026 年初因开源生态与相关社交实验项目走红,吸引了大量开发者与企业关注,体现了 AI 系统从被动响应向自主执行演进的趋势。截至2026年2月,OpenClaw 在 GitHub 上已获得超 180k 星标。
👉了解 OpenClaw:

-
关于 PaddleOCR
PaddleOCR 是百度飞桨生态中的 OCR 与文档智能引擎,提供从文本识别到文档理解的全流程解决方案。聚焦真实业务场景中的文档数字化需求,提供可规模化部署的文字识别与语义解析能力。它覆盖110+种语言的精准识别,支持图文混排、表格结构、公式符号等复杂文档元素的语义边界精准解析,能够输出符合 JSON / Markdown 等标准格式的结构化数据,实现从图像输入到后续业务系统数据处理与智能应用无缝衔接的全流程自动化。 PaddleOCR 支持 Web API 、 SDK 集成及 Docker 容器化部署等多种部署与集成方式,满足从轻量级应用到企业级系统的全场景需求,加速 AI 能力在实际业务中的落地应用。截至2026年2月,PaddleOCR 在 GitHub 上已获得超 70k 星标。
👉了解 PaddleOCR :
https://github.com/PaddlePaddle/PaddleOCR
加入我们
诚挚邀请全球相关开源项目、开发者工具链团队及各类行业伙伴,与文心大模型、飞桨共建开源生态,共同推进文档解析、知识智能与企业级AI技术的普及与落地。
与文心大模型(ERNIE)、飞桨(PaddlePaddle)开展相关开源生态合作,伙伴可获得:
-
与文心大模型、飞桨的深度技术对接与集成支持;
-
覆盖模型、框架、推理、文档解析、数据治理等全栈生态资源;
-
面向行业的联合解决方案打造与联合发布机会;
-
内容生态、市场活动、行业推广等多渠道赋能。
让我们一起,以开源与技术的力量,构建下一代智能化知识生态。




关注【飞桨PaddlePaddle】公众号
获取更多技术内容~

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)