
LLM - Claude Skills:从通才 AI 到可复用的领域专家
摘要:Claude Skills 是可复用的专家能力单元,包含指令、知识和工具,解决现有AI应用中的Prompt复用难、工作流固化等问题。通过渐进式披露机制,Skill仅在必要时加载相关信息,避免上下文污染。开发者可通过六步流程创建Skill,包括定义元数据、设计专家工作流等。相比Sub-Agents和MCP,Skills更轻量,适合垂直任务场景,能实现模型在不同专家模式间的灵活切换,提升AI应用
文章目录
为何还需要 Skills?
即便已经有成熟的 API 和 Tool Use,很多团队仍在遭遇这些问题:
- Prompt 一次性;每开一个新会话,就要重新「教」模型一遍背景和规则。
- 复杂工作流难以固化;不同人写的 Prompt 风格各异,很难沉淀成可维护资产。
- 很多能力是「人肉复制」的:某个同事调好了一个 prompt,只能截图/复制发群里。
Anthropic 为此引入了 Claude Skills:把**「角色设定 + 领域知识 + 工具能力」**打包成一个可复用的技能单元,让模型在需要时自动切换到对应专家模式。
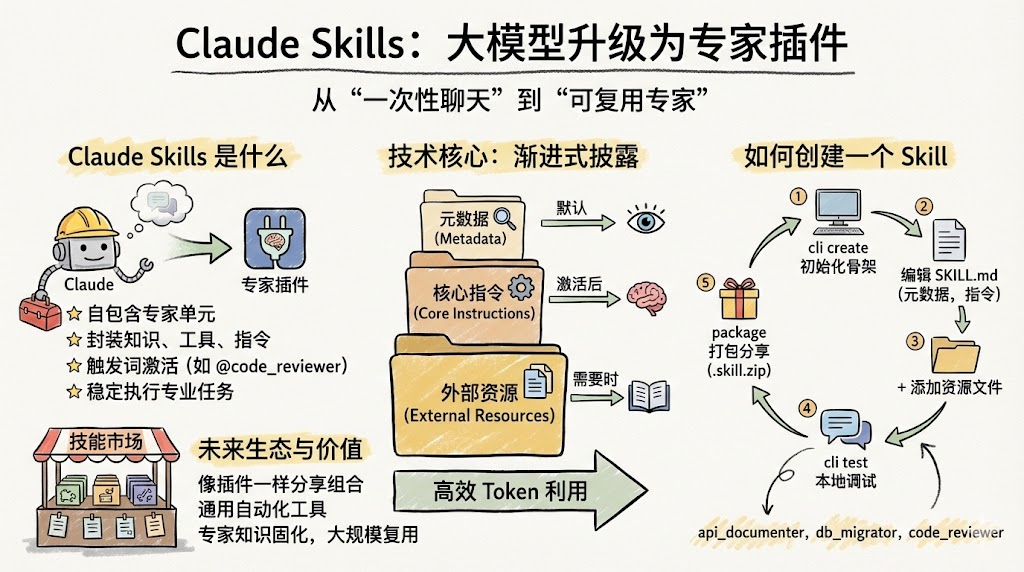
一、Claude Skills 是什么?
https://platform.claude.com/docs/en/agents-and-tools/agent-skills/overview
1.1 一句话定义
Claude Skill 就是一个可被模型调用的「专家能力单元」,包含指令、知识和工具,并可以在不同项目中复用。
一个 Skill 通常包括三类内容:
- 核心指令(Instructions):定义「你是谁、要干什么、怎么干」,例如「你是一名资深代码审查工程师」。
- 相关知识(Knowledge):以文档、示例、API 定义等形式存在,作为按需查阅的知识库。
- 可用工具(Tools):例如
read_file、run_sql之类的函数/接口,帮模型与外部世界交互。
当用户在对话中输入 @code_reviewer 之类的触发词时,Claude 会「加载」对应 Skill,并在后续多轮对话中按其中定义的工作流行为。
1.2 Skills、Sub-Agent、MCP 有何不同?
很多团队已经在用「Agent 编排」或「RAG/MCP」,容易混淆这些概念。可以先看一个对比:
| 特性 | Claude Skills | Sub-Agents(子代理) | MCP / Model-graded Context |
|---|---|---|---|
| 调用方式 | 模型基于上下文自动决定是否调用 | 上层 Agent 显式派发调用 | 模型按协议主动请求、评估上下文 |
| 主要目的 | 封装可复用专家能力与工作流 | 拆分复杂任务、并行处理子任务 | 动态获取长上下文中的关键信息 |
| 复杂度 | 低,工程接入成本小 | 高,需要设计 Agent 协作机制 | 中,需要实现协议和检索/评分逻辑 |
| 典型场景 | 代码审查、迁移、文档生成等垂直任务 | 多 Agent 协同的复杂项目管理 | 大量文档/数据库中的知识查找 |
更通俗一点的类比:
- Skills:给模型装「职业证书」,比如 DBA、文档工程师、法务。同一个模型,根据调用的 Skill 不同,切换不同工作模式。
- Sub-Agents:给模型配一群「下属」,每个下属擅长不同子任务,由上级 Agent 分工协调。
- MCP:给模型接上「知识总线」,需要什么数据,就按协议去问不同的后端系统。
三者可以协同使用:一个 Skill 内部完全可以调用 MCP 数据源,也可以在复杂 Agent 系统中把一个 Skill 当成「特定角色」。
二、技术底座:渐进式披露与 SKILL.md 结构
2.1 Skill 在文件系统中的样子
从工程角度看,一个 Skill 就是一个文件夹,核心是 SKILL.md,辅以若干资源文件:
SKILL.md:必选,定义元数据、工具、核心指令,是 Skill 的「大脑」。- 资源文件:可选,如
api_docs.md、style_guide.md、examples.py等,作为扩展知识。
这种基于文件系统的设计,让 Skill 可以自然地放入 Git 仓库、走 CI/CD、打包发版。
2.2 渐进式披露:只在必要时加载信息
如果每次调用 Skill 都把所有文档和代码塞进上下文,会严重浪费 token、干扰注意力。 为此,Claude Skills 采用了 渐进式披露(Progressive Disclosure) 机制,把信息分为三层:
-
元数据(Metadata)
- 内容:
SKILL.md顶部 frontmatter,例如name、activation_words、usage等。 - 用法:每轮对话,模型只看到所有 Skill 的元数据,用极少的 token 判断「要不要激活某个 Skill」。
- 内容:
-
核心指令(Instructions)
- 内容:frontmatter 下面的主体,描述角色、目标、思考过程、输出格式等。
- 用法:当某个 Skill 被激活时,这部分才会进入上下文,成为模型的长期「职业设定」。
-
外部资源(Resources)
- 内容:Skill 文件夹中的其他文件,如 API 文档、规范、示例等。
- 用法:默认不加载,由模型通过工具(如
read_file)按需读取,类似「查阅手册」而非「一次性塞满」。
这种分层带来的好处是:
- 日常对话几乎不增加 token 消耗,仅扫描简短元数据。
- 真正执行任务时,也只加载必要指令和局部资源,避免上下文污染。
- 可以在一个 Skill 后挂接非常大的知识库,而不受上下文窗口直接限制。
三、六步构建你的第一个 Skill
下面以官方示例 api_documenter 为主线,演示完整从 0 到 1 流程,适合已经在用 Claude API 的团队直接对照迁移。
3.1 前置准备
在开始之前,你需要完成两件事:
- 安装 CLI:
pip install claude-skills-sdk。 - 配置好 Anthropic API Key,使 CLI 能正常调用模型测试 Skill 行为。
3.2 第一步:创建 Skill 骨架
在项目中执行:
claude-skills create api_documenter
CLI 会生成一个 api_documenter 目录,其中包括初始版 SKILL.md 以及示例资源文件。
目录大致类似:
api_documenter/
├─ SKILL.md
├─ examples/
└─ docs/
3.3 第二步:填写 SKILL.md 元数据与工具定义
打开 api_documenter/SKILL.md,先完善 frontmatter 段落:
---
name: api_documenter
version: 1.0
activation_words:
- "@api_documenter"
usage: |
Helps you write high-quality documentation for your APIs.
tools:
- name: read_file
description: Reads the content of a file in the current directory.
parameters:
- name: filename
type: string
description: The name of the file to read.
---
这一段信息会被放在元数据层,用于:
- 告诉模型这个 Skill 叫什么、做什么。
- 定义触发词:用户输入
@api_documenter时优先激活该 Skill。 - 描述可用工具:这里声明了一个
read_file工具,供技能过程按需读取文件。
3.4 第三步:设计核心指令(专家 persona + 工作流)
接下来是在 frontmatter 下方撰写主体指令,决定这个「专家」怎么工作。一个典型的 api_documenter 指令结构是:
You are the world's best API documenter. Your mission is to take a piece of code
and produce clear, concise, and user-friendly API documentation for it.
**Your Process:**
1. **Initial Analysis:** When the user provides code, first read it to understand
its high-level purpose. Identify the main functions, classes, and their parameters.
2. **Ask for Context (if needed):** If the code is ambiguous, ask clarifying
questions. For example: "What is the expected input for this function?"
3. **Read Supporting Files:** The user might provide filenames of related files.
Use the `read_file` tool to read their content for more context.
4. **Generate Documentation:** Based on your analysis, generate the documentation
in Markdown format. The documentation should include:
- A one-sentence summary.
- A section for each function with its parameters, types, and descriptions.
- A code example.
5. **Review and Refine:** Before outputting, review the documentation for clarity,
accuracy, and completeness.
这里有几个关键设计点:
- 先定义清晰的 persona(世界顶级文档工程师),影响整体风格与质量。
- 把思考过程拆成明确步骤,类似「伪状态机」,减少大模型自由发挥的模糊空间。
- 明确输出格式(Markdown + 必备块),方便后端系统解析和渲染。
- 明确引导何时使用工具(第 3 步),发挥渐进式披露优势。
3.5 第四步:添加资源文件(可选但强烈建议)
在实际项目中,你很可能有以下材料:
- API 设计规范,如 REST 命名约定、错误码设计要求等。
- 现有优秀文档示例,作为风格参考。
- 项目内特有的 Domain 规则。
这些内容都可以放到 Skill 文件夹下,如 style_guide.md、api_conventions.md 等,然后在指令中写明:
Before generating documentation, read
style_guide.mdusingread_fileand follow it strictly.
这样既不占用默认上下文,又能在需要时让模型查阅详细规范。
3.6 第五步:本地沙箱测试
完成初版 Skill 后,可以用 CLI 的 test 命令进入沙箱环境调试:
claude-skills test ./api_documenter
CLI 会打开一个交互界面,类似一个只加载当前 Skill 的 Chat:
You are now in a sandboxed environment for the 'api_documenter' skill.
Type your message to begin.
> @api_documenter Please document this Python function:
> def get_user(user_id: int) -> dict:
> # ... implementation ...
> return {"id": user_id, "name": "Test User"}
在这里你可以多轮对话,观察 Skill 是否:
- 主动提出合理的澄清问题。
- 生成符合预期结构的 Markdown 文档。
- 正确使用
read_file等工具查阅资源。
根据输出逐步迭代 SKILL.md 里的流程描述与约束。
3.7 第六步:打包发布
当你对效果满意后,可以使用:
claude-skills package ./api_documenter
生成一个 api_documenter.skill.zip 文件,它就是可分发的技能包:
- 可以上传到内部平台或集成到后端服务中。
- 可以在多环境、多项目之间复制复用。
- 可以像依赖一样管理版本号(例如
1.0.1、1.1.0)。
Anthropic 还规划了 evaluate 命令,用于运行预设测试用例自动评估 Skill 修改是否引入回归,这对大团队协作非常重要。
四、三个典型实战 Skill 模板
下面梳理三个实用度很高、也适合改造成你自己版本的模板:数据库迁移助手、代码审查专家、测试用例生成器。
4.1 数据库迁移助手:db_migrator
目标:安全、高效地生成和执行数据库迁移脚本,适合 CI/CD、变更评审场景。
核心元数据示例:
---
name: db_migrator
activation_words: ["@db_migrator"]
usage: |
Helps with database migrations. Can read schema files and generate migration scripts.
tools:
- name: read_file
description: Read a file like a schema.
- name: run_sql
description: Execute a SQL command against the database.
---
核心指令可以包含:
- 首先使用
read_file获取当前 schema 定义。 - 生成迁移脚本时,显式列出每一步变更(新增/修改/删除)。
- 在执行前,必须 用自然语言解释脚本影响,并请求用户「明确确认」。
- 只有收到明确同意后,才允许调用
run_sql。
亮点在于把 安全护栏写死在 Skill 逻辑里,避免业务方在多个调用点重复实现安全流程。
4.2 代码审查专家:code_reviewer
目标:作为一个「内嵌 Staff Engineer」,对 PR 或代码片段给出有条理的审查意见。
元数据示例:
---
name: code_reviewer
activation_words: ["@code_reviewer"]
usage: |
Critique code and suggest improvements based on our company's style guide.
tools:
- name: read_file
description: Read a file, e.g., 'style_guide.md'.
---
指令建议包含:
- 指定 persona:「你是公司资深工程师,以建设性反馈著称」。
- 要求先通过
read_file('style_guide.md')加载公司代码规范。 - 从逻辑错误、性能隐患、可读性、风格一致性等维度给出结构化反馈。
- 建议附上具体修改建议、行号/片段引用,并保持语气友好。
这种 Skill 适合:在 CI 中自动跑一轮「AI code review」,或在 IDE 插件中以一键命令触发。
4.3 测试用例生成器:test_writer
目标:针对某个函数/类生成高覆盖率的单元测试代码。
这个 Skill 可以只依赖指令,不需要外部工具:
---
name: test_writer
activation_words: ["@test_writer"]
usage: |
Generates unit tests for a given piece of code.
---
指令中的流程可以是:
- 分析代码逻辑,枚举所有可能路径/分支。
- 为每条路径生成测试用例,包括正常路径、边界条件、错误处理等。
- 输出完整可运行的测试文件,符合指定测试框架(pytest、JUnit 等)。
这种纯指令 Skill 的优势是:实现简单、迁移成本极低,适合作为你团队的第一个试点 Skill。
五、从「能用」到「好用」:设计与团队实践
5.1 三大核心设计原则
Anthropic 在文中总结了三条关键原则,决定一个 Skill 的上限:
-
保持指令简洁(Be Concise)
- 核心逻辑写在
SKILL.md里,但避免冗长段落;细节移入外部资源。 - 每句话都有明确目的,方便调试与版本对比。
- 核心逻辑写在
-
明确自由度(Degrees of Freedom)
- 用「必须(must)」指明刚性约束,如输出格式、关键安全步骤。
- 用「可以(may)」给出可选策略,留出 AI 创造空间。
-
善用渐进式披露(Embrace Progressive Disclosure)
- 默认所有文档都是「按需查阅」而非「一股脑喂入」。
- 在指令中用「如果…则 read_file 某某文档」的方式,引导模型触发工具。
5.2 高级模式:结构化输出与工作流建模
随着 Skill 增多,可以尝试一些更系统化的模式:
- 结构化输出:要求以 JSON/YAML 输出,便于后端解析,如:
{"summary": "...","issues": [...], "migration_plan": [...]}。
- 状态机式工作流:在指令中定义状态集合和转移规则,每轮输出都附上当前状态和下一步建议。
- 模板填充:预定义好报告/文档模板,让模型只负责填空,极大减少输出波动。
这些模式非常适合与现有微服务和前端 UI 结合,把 Skill 变成可视化的「流程节点」。
5.3 团队协作与安全实践
在已经大规模使用 Claude API 的团队里推进 Skills,建议:
- 把每个 Skill 当成一个小型「子项目」,入 Git 管理,走代码评审。
- 在 CI 中增加「Skill 打包与冒烟测试」步骤,防止指令调整引入回归。
- 对所有具备副作用的工具(如发送邮件、执行 SQL)统一要求:
- 清晰解释即将执行的操作;
- 要求用户用明确语句确认;
- 对高风险操作增加「模拟执行」模式。
六、面向未来的 Skills 生态
6.1 技能市场与「能力组件化」
Skills 很可能催生一个类似「插件市场」的生态。
可以想象的图景包括:
- 开放的 Skill 市场:领域专家发布
@sql_optimizer、@wechat_title_writer等技能,供他人直接下载使用。 - 企业内部 Skill 仓库:把各业务线的 SOP、合规规则、技术规范封装成一组 Skill,统一在内部平台调用。
- 跨模型复用:虽然 Skills 目前针对 Claude,但这种「结构化指令 + 渐进式披露 + 工具定义」的模式,可以迁移到其他大模型生态。
6.2 从聊天机器人到自动化平台
更宏观地看,Skills 标志着大模型从「聊天机器人」向「通用自动化工具」迈出了一大步:
- 能力不再是临时 prompt,而是版本化的、可部署的「能力组件」。
- 人类专家知识可以通过 Skill 固化下来,被无限复制到不同产品与流程中。
- AI 开发逐步向「组装能力组件」靠拢,而不是每个场景都从头 prompt。
这对已经在用 Claude API 的团队意味着:可以把 Skills 当成下一代「服务层」,用来承载专家经验与跨项目共用逻辑。
结语
如果你已经在项目中使用 Claude API,建议从下面几个切入点开始试验 Claude Skills:
- 给现有代码审查/文档生成流程加一个专用 Skill,把散落的 prompt 收敛成统一规范。
- 为高风险操作(数据库迁移、批量修改)做一个带安全护栏的 Skill,把审批逻辑写进 Skill。
- 在团队内部搭一个「Skill 仓库」,让不同项目共享这些专家能力。
当第一个 Skill 跑起来,你会明显感受到:模型不再是「忘性很大的通才」,而是能被持续打磨、版本化迭代的「团队专家」。这就是 Claude Skills 想带来的根本变化。


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 34
34 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)