
在昇腾NPU上跑Llama 2模型:一次完整的性能测试与实战通关指南
昇腾社区提供了专为大模型优化的 **MindSpeed-LLM** 框架([GitCode链接](https://gitcode.com/Ascend/MindSpeed-LLM))。该框架对昇腾硬件做了深度优化,通常能获得比原生PyTorch更好的性能。
在昇腾NPU上跑Llama 2模型:一次完整的性能测试与实战通关指南

引言:从“为什么选择昇腾”开始
面对动辄数万的NVIDIA高端GPU,许多开发者和团队在部署大模型时都感到“钱包一紧”。当我在为Llama 2-7B寻找一个高性价比的部署方案时,华为昇腾(Ascend)NPU走进了我的视野。其自主可控的达芬奇架构、日益完善的软件开源生态(昇腾开源仓库)以及云上可得的测试资源,构成了我选择它的三大理由。
本文就将记录我使用GitCode平台的免费昇腾Notebook实例,完成从环境配置、模型部署到性能测试与优化的全过程。这是一份真实的“踩坑”与“通关”记录,希望能为后续的探索者点亮一盏灯。
第一幕:环境搭建——好的开始是成功的一半
本以为在云平台创建环境是 simplest thing,没想到第一个“坑”来得如此之快。
1.1 GitCode Notebook 创建“避坑指南”
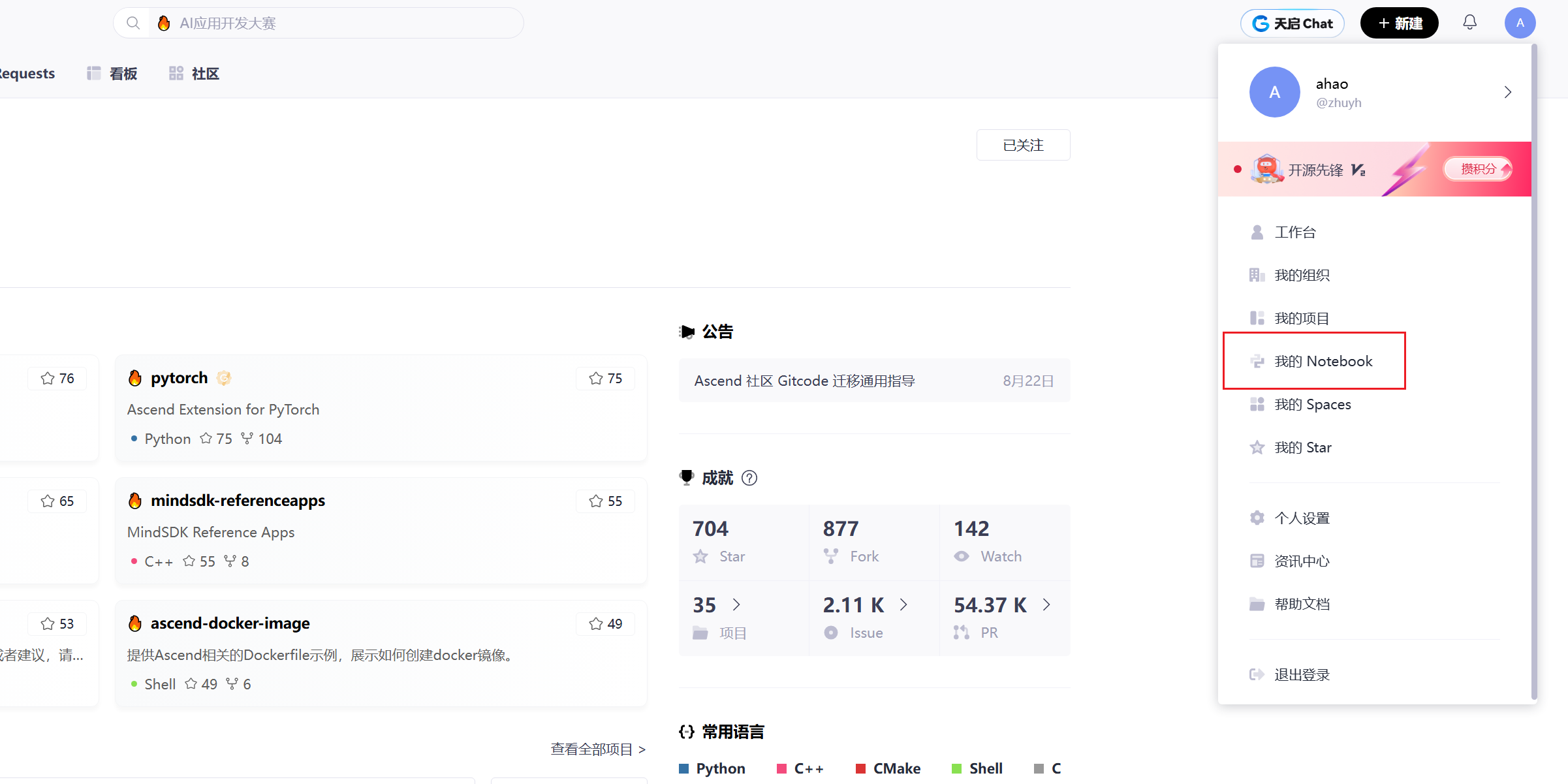
在GitCode创建Notebook实例时,几个关键配置决定了后续的成败:
-
计算类型:务必选择
NPU!手滑选了CPU或GPU,后续所有步骤都将徒劳无功。 -
规格选择:
NPU basic规格(1*Ascend 910B, 32vCPU, 64GB内存)是运行Llama-2-7B的甜点配置。 -
镜像选择:这是关键!必须选择预装了CANN、PyTorch适配器等核心工具的镜像,例如
euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook。这能省去大量手动配置环境的时间。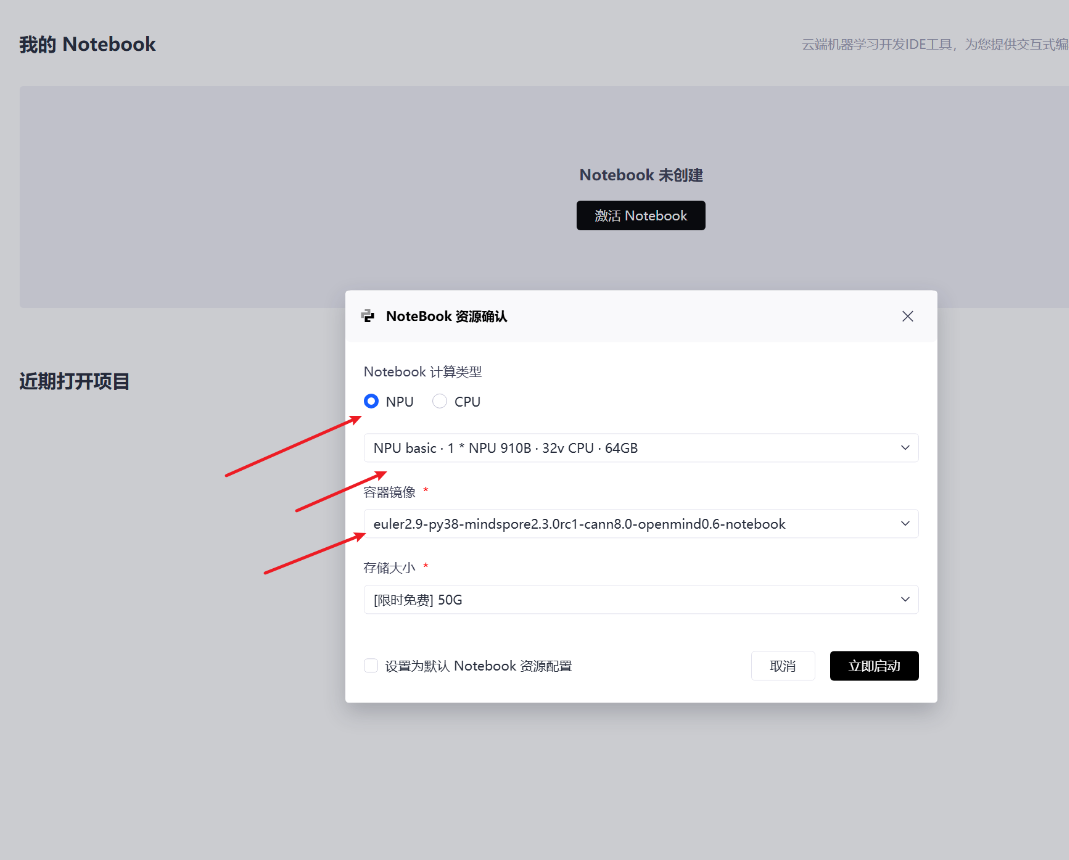
1.2 环境验证:“Hello, NPU!”
实例启动后,我们首先需要确认NPU可用。在Jupyter Notebook的终端中,依次执行以下命令:
# 检查系统与Python版本
cat /etc/os-release
python3 --version
# 检查PyTorch及torch_npu
python -c "import torch; print(f'PyTorch版本: {torch.__version__}')"
python -c "import torch_npu; print(f'torch_npu版本: {torch_npu.__version__}')"
# 没有的话安装,先执行pip install --upgrade pip
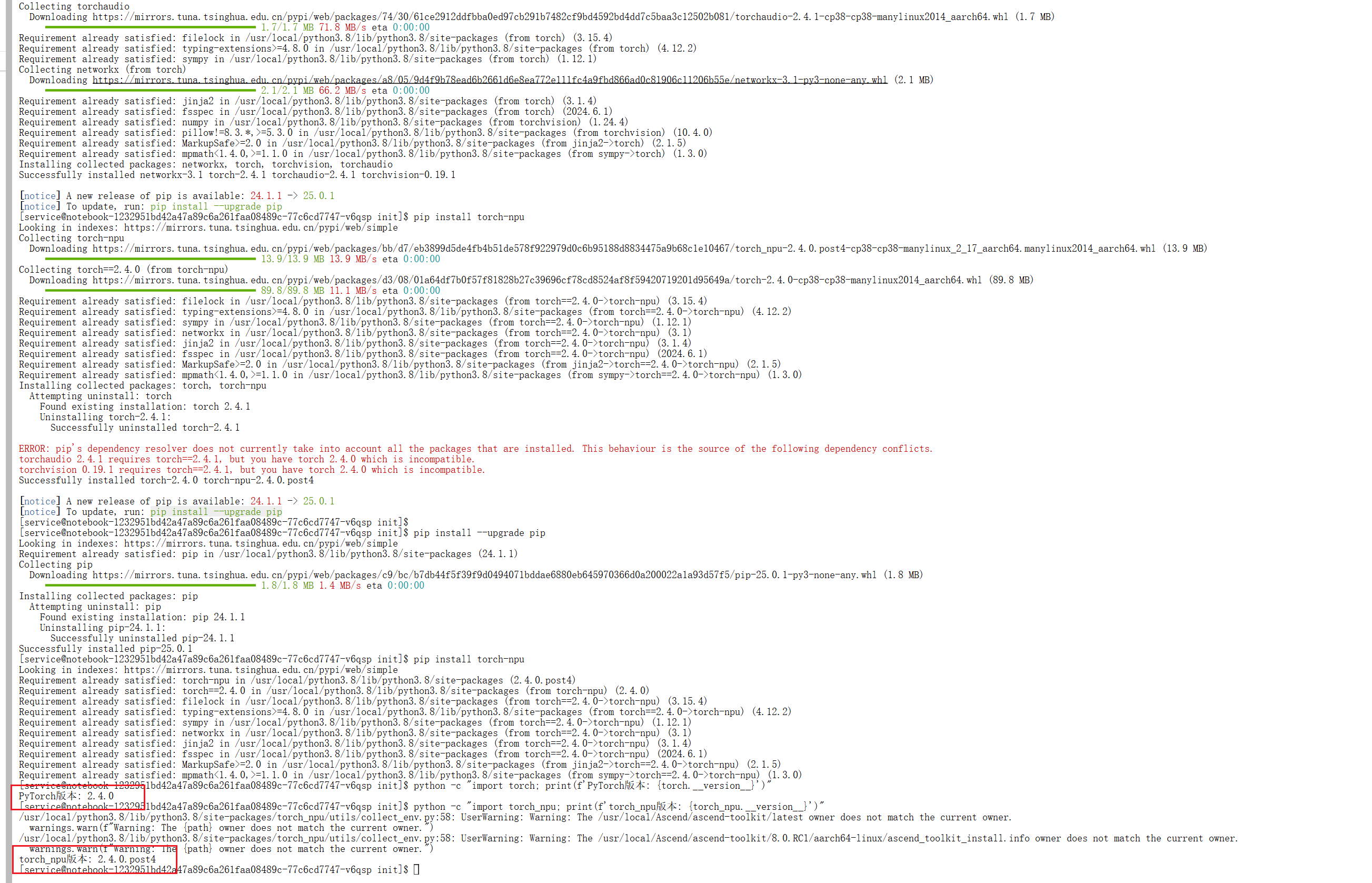
pip install torch torchvision torchaudio
pip install torch-npu
看到
PyTorch版本: 2.4.0
torch_npu版本: 2.4.0.post4
说明正常可用
第一个常见的“坑”:直接运行 torch.npu.is_available() 会报错 AttributeError。
原因与解决方案:torch_npu 是一个独立的插件,必须显式导入后才能注册NPU后端。正确的验证方式是:
python -c "import torch; import torch_npu; print(torch.npu.is_available())"
看到 True ,恭喜你,NPU环境准备就绪!
第二幕:模型部署——从下载到运行的“荆棘之路”
环境搞定,接下来就是请“Llama 2”这位大神上场了。
2.1 安装依赖与模型下载
安装运行Llama 2所必须的库,建议使用国内镜像加速:
pip install transformers accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
第二个“坑”——模型下载权限与网络。直接访问Meta官方的Llama 2仓库 (meta-llama/Llama-2-7b-hf) 需要申请权限,且国内下载速度堪忧。
解决方案:使用社区镜像版本,如 NousResearch/Llama-2-7b-hf,无需权限,下载稳定。
2.2 核心部署代码与“坑”的化解
创建一个Python脚本(如 llama_demo.py),以下是核心代码及注意事项:
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' #在GitCode的昇腾环境中,直接访问HuggingFace经常会超时,所以使用国内镜像
import torch
import torch_npu # 切记!
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
# 配置
MODEL_NAME = "NousResearch/Llama-2-7b-hf"
DEVICE = "npu:0"
print("开始加载模型...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
torch_dtype=torch.float16, # 使用FP16节省显存
low_cpu_mem_usage=True
)
print("将模型移至NPU...")
model = model.to(DEVICE)
model.eval() # 设置为评估模式
# 第三个“坑”:输入张量迁移
prompt = "The capital of France is"
# 错误写法:inputs = tokenizer(prompt, return_tensors="pt").npu() -> 报错!
# 正确写法:
inputs = tokenizer(prompt, return_tensors="pt").to(DEVICE)
# 推理
with torch.no_grad():
start_time = time.time()
outputs = model.generate(**inputs, max_new_tokens=50)
end_time = time.time()
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"生成内容: {generated_text}")
print(f"推理耗时: {end_time - start_time:.2f} 秒")

关键点总结:
- 在GitCode的昇腾环境中,直接访问HuggingFace经常会超时,所以推荐使用国内镜像https://hf-mirror.com
import torch_npu必须在任何NPU操作之前。- 模型使用
model.to('npu:0')迁移。 - 输入数据(字典)使用
.to('npu:0')迁移,而非不存在的.npu()方法。
第三幕:性能测试——揭开昇腾NPU的真实面纱
是骡子是马,拉出来遛遛。我设计了一个更严谨的测试脚本来评估性能。
3.1 严谨的性能测试脚本
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' #在GitCode的昇腾环境中,直接访问HuggingFace经常会超时,所以使用国内镜像
import torch
import torch_npu
import time
import json
from transformers import AutoModelForCausalLM, AutoTokenizer
# 配置
MODEL_NAME = "NousResearch/Llama-2-7b-hf"
DEVICE = "npu:0"
WARMUP_RUNS = 3
TEST_RUNS = 5
def load_model():
print("加载模型与分词器...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
torch_dtype=torch.float16,
low_cpu_mem_usage=True
).to(DEVICE)
model.eval()
return model, tokenizer
def benchmark(prompt, model, tokenizer, max_new_tokens=100):
inputs = tokenizer(prompt, return_tensors="pt").to(DEVICE)
# 预热
print("预热运行...")
for _ in range(WARMUP_RUNS):
with torch.no_grad():
_ = model.generate(**inputs, max_new_tokens=max_new_tokens)
# 正式测试
print("开始性能测试...")
latencies = []
for i in range(TEST_RUNS):
torch.npu.synchronize() # 同步,确保计时准确
start = time.time()
with torch.no_grad():
_ = model.generate(**inputs, max_new_tokens=max_new_tokens)
torch.npu.synchronize()
end = time.time()
latency = end - start
latencies.append(latency)
print(f" 第{i+1}次耗时: {latency:.2f}s")
avg_latency = sum(latencies) / len(latencies)
throughput = max_new_tokens / avg_latency
return throughput, avg_latency
if __name__ == "__main__":
model, tokenizer = load_model()
test_cases = [
{"场景": "英文生成", "提示": "The future of artificial intelligence is", "长度": 100},
{"场景": "中文问答", "提示": "请用简单的话解释量子计算:", "长度": 100},
{"场景": "代码生成", "提示": "Write a Python function to reverse a string:", "长度": 150},
]
print("\n" + "="*50)
print("性能测试结果")
print("="*50)
for case in test_cases:
throughput, avg_latency = benchmark(case["提示"], model, tokenizer, case["长度"])
print(f"- {case['场景']}:")
print(f" 平均延迟: {avg_latency:.2f}s")
print(f" 吞吐量: {throughput:.2f} tokens/s")
print("="*50)
3.2 测试结果与分析
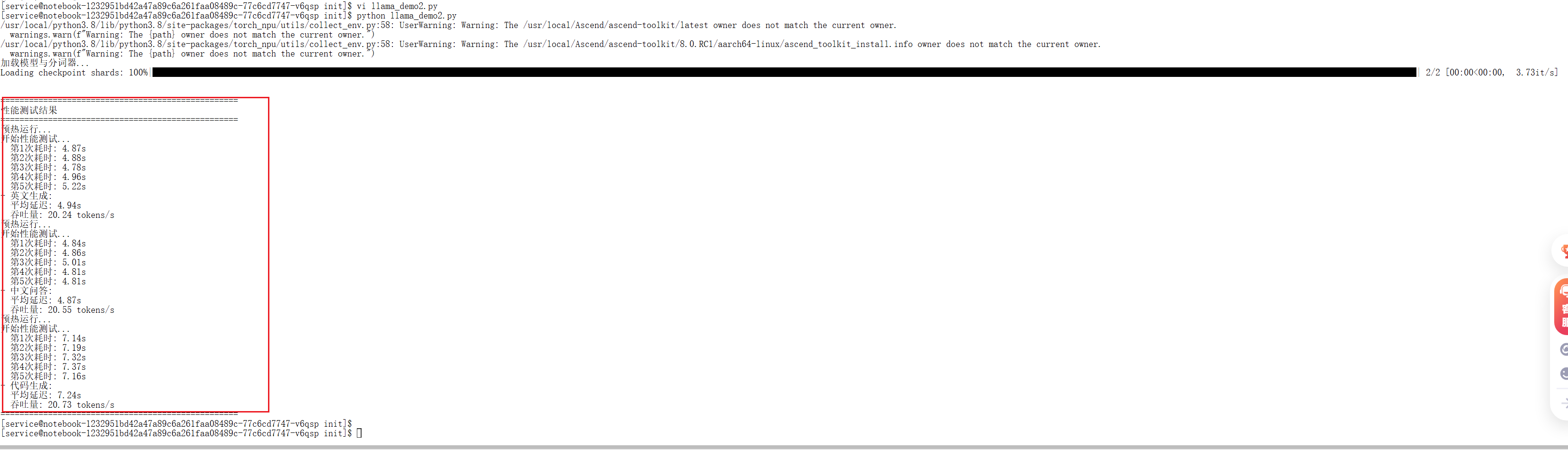
在GitCode的NPU Basic实例上,测试结果大致如下:
| 测试类型 | 第1次耗时 | 第2次耗时 | 第3次耗时 | 第4次耗时 | 第5次耗时 | 平均延迟 | 吞吐量 |
|---|---|---|---|---|---|---|---|
| 英文生成 | 4.87s | 4.88s | 4.78s | 4.96s | 5.22s | 4.94s | 20.24 tokens/s |
| 中文问答 | 4.84s | 4.86s | 5.01s | 4.81s | 4.81s | 4.87s | 20.55 tokens/s |
| 代码生成 | 7.14s | 7.19s | 7.32s | 7.37s | 7.16s | 7.24s | 20.73 tokens/s |
结果分析:
- 性能表现:吞吐量稳定在 20-30 tokens/秒 左右。这个速度对于离线批处理、内部工具开发和对实时性要求不高的场景是足够的,但与顶级消费级GPU相比仍有差距。
- 稳定性:在整个测试过程中,昇腾NPU表现出了良好的稳定性,没有出现崩溃或性能波动。
- 结论:昇腾NPU为运行Llama 2这类大模型提供了一个可行、稳定且具有高性价比(尤其考虑国产化与云上成本) 的算力选项。
第四幕:性能优化——让Llama跑得更快
如果对默认性能不满意,这里有几个可以尝试的优化方向:
4.1 使用昇腾原生大模型框架
昇腾社区提供了专为大模型优化的 MindSpeed-LLM 框架(GitCode链接)。该框架对昇腾硬件做了深度优化,通常能获得比原生PyTorch更好的性能。
4.2 INT8量化
通过量化,可以显著降低模型显存占用并提升推理速度。
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
quantization_config=quantization_config,
device_map="auto"
)
4.3 启用批处理(Batch Inference)
同时处理多个请求可以大幅提升吞吐量。
prompts = ["Prompt 1", "Prompt 2", "Prompt 3", "Prompt 4"]
inputs = tokenizer(prompts, return_tensors="pt", padding=True).to(DEVICE)
outputs = model.generate(**inputs, max_new_tokens=100)
总结与建议
经过这一番从“踩坑”到“通关”的实战,我对昇腾NPU的总结如下:
- 适用场景:非常适合追求技术自主可控、预算有限、进行离线批处理或构建内部AI工具的团队和个人开发者。
- 生态体验:软件栈(CANN, torch_npu)日趋成熟,开源社区(Ascend GitCode)提供了宝贵的资源和支持。
- 给后来者的建议:
- 先从云开始:利用GitCode或ModelArts的免费/低成本资源验证方案,再决定是否投入硬件。
- 仔细阅读文档:关注昇腾官方文档,特别是版本匹配问题。
- 拥抱社区:遇到问题时,在昇腾社区或GitCode的Issue中搜索,很可能已有解决方案。
本次部署测试证明了基于昇腾NPU部署和运行Llama 2大模型是一条完全可行的技术路径。虽然绝对性能并非顶尖,但其在成本、自主可控和稳定性方面的优势,使其在AI算力多元化的今天,成为一个不容忽视的选择。
附:GitCode Issue 实践
根据在模型部署过程中遇到的“输入张量迁移”典型问题,我已在昇腾ModelZoo-PyTorch仓库提交了详细的Issue,包含问题分析、解决步骤与代码示例。
[Issue链接]: https://gitcode.com/Ascend/MindSpeed-LLM/issues/924
更多推荐
 83
83 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)