
CrewAI 全面详解:多智能体协作框架从入门到实战
CrewAI是一款基于LangChain构建的开源多智能体编排框架,旨在通过模拟现实团队协作模式,协调多个AI智能体分工合作,高效完成内容创作、市场分析等复杂任务。其兼容主流大语言模型(如OpenAI、Google Gemini等)及各类工具(如网络搜索、PDF解析),可让开发者快速搭建多智能体系统。核心优势体现在角色驱动设计(智能体有明确角色定位)、智能协作机制(自主委派任务与共享信息)、灵活工
CrewAI 是一款开源多智能体编排框架,核心目标是通过模拟现实世界团队协作模式,协调多个 AI 智能体(Agent)分工合作,高效完成复杂任务(如内容创作、市场分析、客户支持等)。它基于 LangChain 构建,兼容主流工具与大语言模型(LLM),同时提供更高层次的 “团队协作” 抽象,让开发者无需关注底层细节即可快速搭建多智能体系统。

一、CrewAI 核心基础
1.1 什么是 CrewAI?
- 定位:由 João Moura 开发的开源框架,专注于多智能体协同,弥补单一 LLM 在复杂任务中 “能力单一、效率低下” 的问题。
- 核心逻辑:模拟人类团队分工 —— 每个智能体(Agent)扮演特定角色(如研究员、撰稿人、分析师),通过预设流程(Flow)协作完成任务(Task),最终由 “团队(Crew)” 统一调度。
- 兼容性:基于 LangChain 构建,支持 OpenAI、Anthropic、Google Gemini、本地模型(如 Ollama)等主流 LLM,同时可集成网络搜索、PDF 解析、向量数据库(Qdrant/Milvus)等工具。
- 官方资源:
1.2 核心优势
CrewAI 的核心竞争力在于 “协作能力” 与 “易用性”,具体体现在以下 6 点:
- 角色驱动设计:每个 Agent 有明确的
role(角色)、goal(目标)和backstory(背景故事),LLM 可基于角色定位生成更贴合场景的输出(如 “SEO 专家” 会优先考虑关键词优化)。 - 智能协作机制:Agent 之间可自主委派任务、共享信息(如 “研究员” 将数据交给 “分析师”,“分析师” 再将结论交给 “报告撰写者”),无需人工干预。
- 灵活工具集成:支持开箱即用工具(如 DuckDuckGo 搜索、SerperDev 搜索),也可通过
BaseTool类封装自定义工具(如 PDF 解析、向量数据库检索)。 - 生产级特性:内置内存管理(记忆对话上下文)、知识库(RAG 集成)、可观测性(详细日志)和权限控制,满足企业级需求。
- 多样化流程编排:支持顺序(sequential)、并行(parallel)、分层(hierarchical)等工作流模式,可通过
Flow类实现条件逻辑、循环和状态管理。 - 低门槛上手:提供简洁的 API 和 YAML 配置支持,开发者可通过纯 Python 代码或 “Python+YAML” 混合方式快速搭建系统,无需深入底层多智能体逻辑。
1.3 典型应用场景
CrewAI 适用于 “需要多步骤、多角色协作” 的复杂任务,常见场景包括:
- 内容创作:研究(找热点)→ 撰写(写文章)→ 编辑(优化内容)→ 发布(生成格式)的全流程自动化。
- 市场分析:数据收集(爬取行业报告)→ 竞品分析(对比产品功能)→ 趋势预测(生成可视化报告)。
- 客户支持:初步应答(客服专员)→ 技术排查(技术专家)→ 解决方案推送(知识库调用)。
- 自动化工作流:数据处理(清洗 Excel)→ 决策(判断风险)→ 执行(发送邮件通知)。
- 学术研究:文献检索(PDF 解析)→ 数据提取(关键结论汇总)→ 论文大纲生成(结构化输出)。
二、CrewAI 核心概念与架构
CrewAI 的架构围绕 “组件化” 设计,核心组件包括 Agent(代理)、Task(任务)、Crew(团队)、Flow(流程),以及 Tool(工具)和 LLM(语言模型),各组件协同构成完整的多智能体系统。
2.1 架构概览
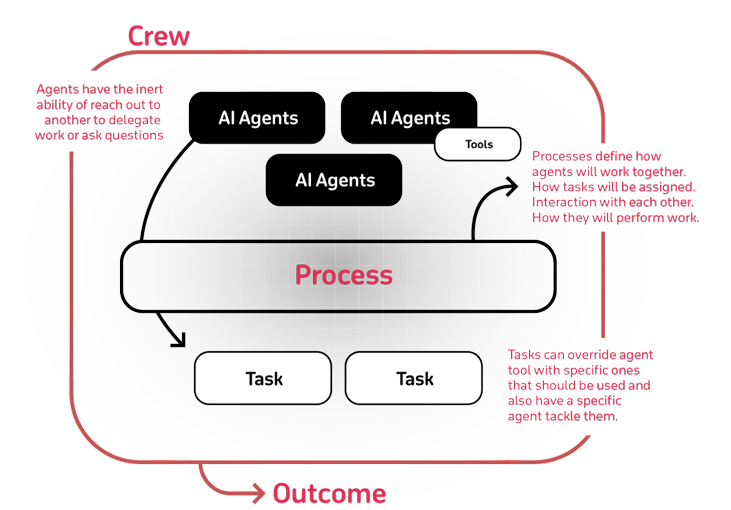
2.2 核心组件详解
1. Agent(代理):“团队成员”
Agent 是 CrewAI 的核心执行单元,相当于 “团队中的具体角色”,每个 Agent 有明确的职责和能力边界。
关键属性(必选 / 可选)
| 属性 | 类型 | 作用 | 示例 |
|---|---|---|---|
role |
字符串 | 定义 Agent 的角色(需明确,避免宽泛) | "SEO 内容优化专家"(而非 “助手”) |
goal |
字符串 | 明确 Agent 的任务目标(可含动态参数,如 {query}) |
"优化文章关键词密度,提升 Google 搜索排名前 10" |
backstory |
字符串 | 提供角色背景(增强 LLM 角色代入感) | "你有 8 年 SEO 经验,曾帮助电商网站流量提升 300%,熟悉 Google 算法" |
tools |
列表 | Agent 可调用的工具(按需分配,避免过载) | [ddgs_text_search, pdf_tool](搜索工具 + PDF 解析工具) |
llm |
LLM 实例 | 驱动 Agent 的语言模型(需提前配置 API 密钥、模型名称) | deepseek_llm()(自定义的 DeepSeek 模型实例) |
memory |
布尔值 | 是否启用记忆(记住对话上下文,适合多轮协作) | True(客服场景需记忆客户历史问题) |
verbose |
布尔值 | 是否输出详细日志(调试用) | True(开发阶段启用,生产阶段可关闭) |
allow_delegation |
布尔值 | 是否允许 Agent 将任务委派给其他 Agent(默认 True) |
False(技术专家角色不允许委派,需亲自处理) |
代码示例:创建 Agent
from crewai import Agent, LLM
# 1. 先配置 LLM(以 DeepSeek 为例)
def deepseek_llm(**kwargs):
return LLM(
model="deepseek/deepseek-chat", # 模型名称
api_key="sk-xxx", # 你的 API 密钥
api_base="https://api.deepseek.com/v1", # API 基础地址
model_kwargs={"llm_provider": "deepseek"} # 模型提供商
)
# 2. 创建“研究员 Agent”(负责网络搜索)
researcher_agent = Agent(
role="市场趋势研究员",
goal="收集 {industry} 行业的 2024 年最新趋势数据,包括市场规模、增长驱动因素",
backstory="你是拥有 5 年行业研究经验的分析师,擅长通过网络搜索获取权威数据(如 Statista、行业报告),并提炼关键结论",
tools=[ddgs_text_search], # 导入提前封装的 DuckDuckGo 搜索工具
llm=deepseek_llm(),
verbose=True
)
# 3. 创建“报告撰写 Agent”(负责生成文档)
writer_agent = Agent(
role="市场报告撰写专家",
goal="将研究员提供的趋势数据整理为 Markdown 格式报告,包含执行摘要、数据图表建议、行动建议",
backstory="你是专业商业报告撰写者,曾为 Fortune 500 公司撰写行业分析报告,擅长将复杂数据转化为清晰易懂的内容",
llm=deepseek_llm(),
verbose=True
)三、CrewAI 安装与环境配置
CrewAI 支持 Windows、Linux、macOS 系统,核心依赖是 Python 3.10+,安装方式简单,且提供 “纯 Python 代码” 和 “Python+YAML 配置” 两种实现方式。
3.1 系统要求
- Python 版本:3.10 及以上(推荐 3.11,兼容性更好)。
- 包管理器:pip(默认)或 uv(更快的包管理工具)。
- 依赖库:
crewai(核心框架)、crewai-tools(内置工具)、llama-index(工具集成)、pydantic(数据模型)等。
3.2 基础安装
通过 pip 安装核心包:
# 安装 CrewAI 核心框架
pip install crewai
# 安装内置工具库(可选,含搜索、爬取等工具)
pip install crewai-tools
# 安装常用依赖(PDF 解析、向量库等)
pip install markitdown chonkie qdrant-client sentence-transformers
3.3 两种实现方式
方式 1:纯 Python 代码实现(适合快速测试)
通过直接编写 Python 代码创建 Agent、Task、Crew,无需额外配置文件,适合简单场景或新手入门。
完整示例:多智能体内容创作
from crewai import Agent, Task, Crew, Process, LLM
from crewai_tools import DuckDuckGoSearchTool
# 1. 配置 LLM(以 OpenAI GPT-3.5 为例)
def openai_llm(**kwargs):
return LLM(
model="gpt-3.5-turbo",
api_key="sk-xxx", # 你的 OpenAI API 密钥
model_kwargs={"llm_provider": "openai"}
)
# 2. 定义工具(DuckDuckGo 搜索)
search_tool = DuckDuckGoSearchTool()
# 3. 创建 Agent
# 3.1 话题研究员(找热点)
topic_agent = Agent(
role="话题研究专家",
goal="挖掘 {topic} 相关的 2024 年热点话题,包括目标受众兴趣点、关键词建议",
backstory="你是内容策略师,擅长通过网络搜索识别趋势,曾为科技博客提供热门话题建议",
tools=[search_tool],
llm=openai_llm(),
verbose=True
)
# 3.2 内容撰稿人(写文章)
writer_agent = Agent(
role="科技博客撰稿人",
goal="基于研究结果撰写 1000 字博客,结构清晰(含标题、小标题、实用建议)",
backstory="你是获奖科技撰稿人,擅长将复杂技术转化为通俗内容,文章阅读量平均超 10 万",
llm=openai_llm(),
verbose=True
)
# 3.3 编辑(优化内容)
editor_agent = Agent(
role="内容编辑",
goal="审核文章:修正语法错误、优化逻辑、确保关键词自然融入",
backstory="你是严谨的内容编辑,有 10 年科技领域编辑经验,注重文章准确性和可读性",
llm=openai_llm(),
verbose=True
)
# 4. 创建 Task
research_task = Task(
description="研究 {topic} 的 2024 年热点:1. 当前讨论焦点;2. 目标受众(25-35 岁程序员)兴趣点;3. 高搜索量关键词",
agent=topic_agent,
expected_output="Markdown 格式的研究报告,含 3 点核心结论"
)
write_task = Task(
description="基于研究报告撰写博客:标题需吸引眼球,内容分 3-4 个小标题,结尾含 3 条实用建议",
agent=writer_agent,
context=[research_task],
expected_output="1000 字博客草稿(Markdown 格式)"
)
edit_task = Task(
description="审核博客:1. 修正语法/拼写错误;2. 优化段落逻辑;3. 确保关键词自然融入;4. 调整标题吸引力",
agent=editor_agent,
context=[write_task],
expected_output="最终博客(Markdown 格式)",
output_file="ai_blog_2024.md"
)
# 5. 创建 Crew 并执行
content_crew = Crew(
agents=[topic_agent, writer_agent, editor_agent],
tasks=[research_task, write_task, edit_task],
process=Process.sequential,
verbose=True
)
# 启动团队(传入话题参数)
content_crew.kickoff(inputs={"topic": "大模型在编程中的应用"})
方式 2:Python+YAML 配置实现(推荐生产场景)
通过 YAML 文件定义 Agent 和 Task 的配置,Python 代码负责加载配置、创建 Crew,便于维护和版本控制(适合复杂项目)。
步骤 1:生成项目结构
通过 crewai create 命令快速生成标准项目结构:
# 创建名为 "content_crew" 的项目
crewai create crew content_crew
生成的项目结构如下:
content_crew/
├── knowledge/ # 知识库(如 PDF、文档)
├── src/
│ └── content_crew/
│ ├── config/ # YAML 配置文件
│ │ ├── agents.yaml # Agent 配置
│ │ └── tasks.yaml # Task 配置
│ ├── tools/ # 自定义工具
│ │ └── __init__.py
│ ├── __init__.py
│ ├── crew.py # Crew 逻辑
│ └── main.py # 项目入口
├── .env # 环境变量(API 密钥等)
├── pyproject.toml # 依赖配置
└── README.md
步骤 2:编写 YAML 配置
-
agents.yaml(定义 Agent 角色、目标、背景):
# 话题研究员 Agent topic_researcher: role: "话题研究专家" goal: "挖掘 {topic} 相关的 2024 年热点话题,包括目标受众兴趣点、关键词建议" backstory: "你是内容策略师,擅长通过网络搜索识别趋势,曾为科技博客提供热门话题建议" tools: ["duckduckgo_search"] # 引用工具(需在 Python 中注册) # 内容撰稿人 Agent content_writer: role: "科技博客撰稿人" goal: "基于研究结果撰写 1000 字博客,结构清晰(含标题、小标题、实用建议)" backstory: "你是获奖科技撰稿人,擅长将复杂技术转化为通俗内容,文章阅读量平均超 10 万" # 编辑 Agent content_editor: role: "内容编辑" goal: "审核文章:修正语法错误、优化逻辑、确保关键词自然融入" backstory: "你是严谨的内容编辑,有 10 年科技领域编辑经验,注重文章准确性和可读性" -
tasks.yaml(定义 Task 描述、输出、绑定 Agent):
# 研究任务 research_topic: description: "研究 {topic} 的 2024 年热点:1. 当前讨论焦点;2. 目标受众(25-35 岁程序员)兴趣点;3. 高搜索量关键词" expected_output: "Markdown 格式的研究报告,含 3 点核心结论" agent: "topic_researcher" # 绑定到话题研究员 # 撰写任务 write_blog: description: "基于研究报告撰写博客:标题需吸引眼球,内容分 3-4 个小标题,结尾含 3 条实用建议" expected_output: "1000 字博客草稿(Markdown 格式)" agent: "content_writer" # 绑定到撰稿人 context: ["research_topic"] # 依赖研究任务 # 编辑任务 edit_blog: description: "审核博客:1. 修正语法/拼写错误;2. 优化段落逻辑;3. 确保关键词自然融入;4. 调整标题吸引力" expected_output: "最终博客(Markdown 格式)" agent: "content_editor" # 绑定到编辑 context: ["write_blog"] # 依赖撰写任务 output_file: "ai_blog_2024.md"
步骤 3:Python 代码加载配置并执行
-
crew.py(加载 YAML 配置,创建 Crew):
from crewai import Agent, Task, Crew, Process, LLM from crewai.project import CrewBase, agent, crew, task from crewai_tools import DuckDuckGoSearchTool # 配置 LLM def openai_llm(**kwargs): return LLM( model="gpt-3.5-turbo", api_key="sk-xxx", model_kwargs={"llm_provider": "openai"} ) # 加载工具 search_tool = DuckDuckGoSearchTool() @CrewBase class ContentCrew: # 加载 YAML 配置文件路径 agents_config = "config/agents.yaml" tasks_config = "config/tasks.yaml" # 配置 LLM llm = openai_llm() # 注册 Agent(绑定工具) @agent def topic_researcher(self) -> Agent: return Agent( config=self.agents_config["topic_researcher"], tools=[search_tool], # 为研究员添加搜索工具 llm=self.llm, verbose=True ) @agent def content_writer(self) -> Agent: return Agent( config=self.agents_config["content_writer"], llm=self.llm, verbose=True ) @agent def content_editor(self) -> Agent: return Agent( config=self.agents_config["content_editor"], llm=self.llm, verbose=True ) # 注册 Task @task def research_topic(self) -> Task: return Task(config=self.tasks_config["research_topic"]) @task def write_blog(self) -> Task: return Task(config=self.tasks_config["write_blog"]) @task def edit_blog(self) -> Task: return Task(config=self.tasks_config["edit_blog"]) # 注册 Crew @crew def crew(self) -> Crew: return Crew( agents=self.agents, tasks=self.tasks, process=Process.sequential, verbose=True ) -
main.py(项目入口,启动 Crew):
from src.content_crew.crew import ContentCrew if __name__ == "__main__": # 创建 Crew 实例 content_crew = ContentCrew() # 启动任务(传入话题参数) content_crew.crew().kickoff(inputs={"topic": "大模型在编程中的应用"})
步骤 4:运行项目
# 进入项目根目录
cd content_crew
# 运行入口文件
python -m src.content_crew.main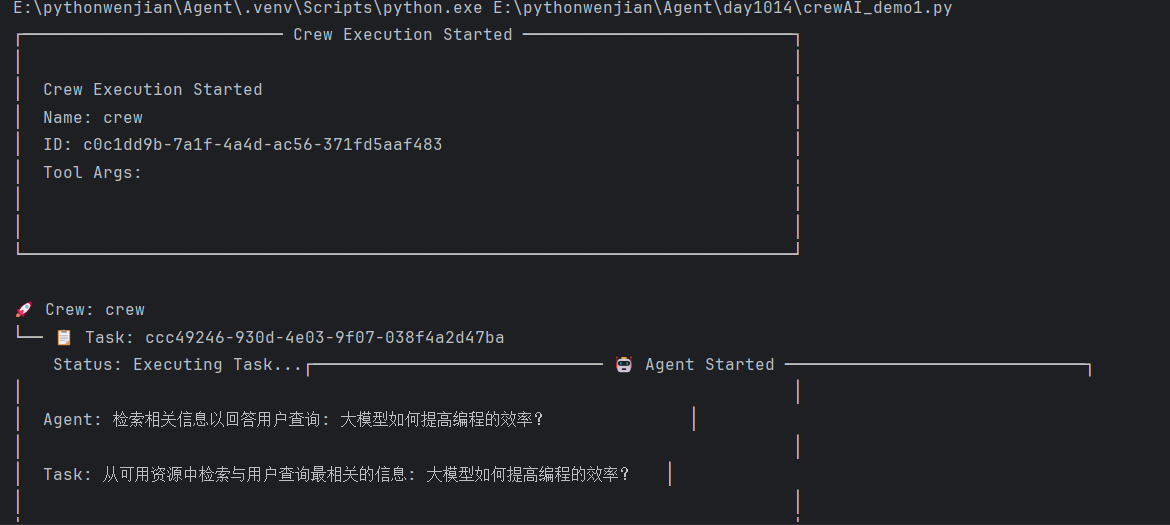
接下来我们就项目加装一些功能:
DDGS 中文文本搜索工具实现
在 CrewAI 开发中,网络搜索工具是 “研究员类 Agent” 的核心能力支撑,以下为基于 DuckDuckGo(DDGS)的中文文本搜索工具完整实现,可直接集成到现有 Agent 中,用于获取实时、权威的外部数据(如行业趋势、热点话题、案例素材等)。
一、工具核心功能与定位
该工具通过duckduckgo_search库实现中文网络文本搜索,支持指定搜索关键词、结果数量,返回 Markdown 格式的结构化结果(含标题、摘要、链接),核心价值在于:
- 为 “研究员 Agent” 提供实时数据获取能力,解决 LLM “知识时效性不足” 的问题(如获取 2025 年 AI 行业最新趋势);
- 结果自动格式化,便于后续 Agent(如撰稿 Agent、分析 Agent)直接复用,减少数据整理成本;
- 包含异常处理(如搜索失败、无结果),确保工具调用稳定性,符合 CrewAI 工具设计的 “可靠性原则”、。
二、完整工具代码实现
"""
CrewAI工具模块 - DDGS中文文本搜索工具
用于为Agent提供中文网络搜索能力,返回Markdown格式结构化结果
"""
from __future__ import annotations
import logging
from typing import List, Dict, Optional
# 从CrewAI导入工具装饰器,用于将普通函数转换为Agent可调用的工具
from crewai.tools import tool
# 导入DDGS库,实现DuckDuckGo搜索功能
from duckduckgo_search import DDGS
# 初始化日志记录器,用于捕获工具调用过程中的异常(如搜索失败)
logger = logging.getLogger(__name__)
@tool("DDGS Text Search") # 工具名称,Agent配置时需引用此名称
def ddgs_text_search(query: str, max_results: int = 10) -> str:
"""
使用DuckDuckGo进行中文网络文本搜索,返回Markdown格式结果,适配CrewAI Agent调用。
Args:
query: 搜索关键词(必填,需具体,如“2025 AI大模型技术突破”而非“AI趋势”)
max_results: 最大返回条数(可选,默认10条,建议根据任务需求调整,避免结果过载)
Returns:
格式化的搜索结果字符串(Markdown列表,含标题、摘要、链接),异常时返回明确提示
"""
# 1. 输入校验:避免空关键词导致无效搜索
if not query or not query.strip():
return "> 搜索关键词为空,请提供有效内容(如“2025电动汽车市场规模”)。"
try:
# 2. 初始化DDGS客户端,执行搜索(指定中文地区、中度安全过滤)
with DDGS() as ddgs:
raw_results: List[Dict[str, str]] = list(
ddgs.text(
keywords=query.strip(), # 清理关键词前后空格
region="zh-cn", # 限定中文地区结果,确保相关性
safesearch="moderate", # 中度安全过滤,屏蔽违规内容
max_results=max_results # 限制结果数量,避免Agent处理压力
)
)
except Exception as exc:
# 3. 异常捕获:记录日志并返回友好提示(便于调试和Agent决策)
logger.exception(f"DDGS搜索失败,关键词:{query}")
return f"> 搜索失败:{str(exc)}(建议检查网络连接或调整关键词)。"
# 4. 无结果处理:返回明确提示,避免Agent因空数据报错
if not raw_results:
return f"> 未找到与“{query}”相关的结果(建议优化关键词,如补充时间范围、领域)。"
# 5. 结果格式化:转换为Markdown列表,便于后续Agent读取和复用
result_lines: List[str] = [f"**共找到 {len(raw_results)} 条相关结果:**\n"]
for idx, item in enumerate(raw_results, 1):
# 提取结果中的核心字段(标题、链接、摘要),处理空值
title = item.get("title", "未获取到标题").strip()
href = item.get("href", "无链接")
# 摘要截取前220字符,替换换行符,避免格式混乱
body = (item.get("body") or "无摘要")[:220].strip().replace("\n", " ")
# 拼接单条结果(Markdown格式,含序号、标题、摘要、链接)
result_lines.append(
f"{idx}. **{title}** \n"
f" 摘要:{body}... \n"
f" 原文链接:{href}\n"
)
# 6. 返回最终格式化结果
return "\n".join(result_lines)
三、工具集成到 Agent 的示例
该工具需绑定到 “具备搜索需求的 Agent”(如研究员 Agent、市场分析 Agent),遵循 CrewAI “工具按需分配” 的最佳实践(避免给无需搜索的 Agent 分配该工具,如撰稿 Agent、编辑 Agent)。以下为集成到 “AI 行业研究员 Agent” 的代码示例:
from crewai import Agent, LLM
# 导入上述实现的DDGS搜索工具
from tools import ddgs_text_search
# 1. 配置驱动Agent的LLM(以DeepSeek为例)
def deepseek_llm(**kwargs):
return LLM(
model="deepseek/deepseek-chat",
api_key="sk-xxx", # 替换为你的API密钥
api_base="https://api.deepseek.com/v1",
model_kwargs={"llm_provider": "deepseek"}
)
# 2. 创建“AI行业研究员Agent”,绑定DDGS搜索工具
ai_researcher_agent = Agent(
role="AI行业研究员",
goal="收集{topic}相关的2025年最新数据,包括技术突破、市场规模、典型案例",
backstory="你是拥有5年AI行业研究经验的分析师,擅长通过网络搜索获取权威数据(如Statista、艾瑞咨询报告),并提炼关键结论",
tools=[ddgs_text_search], # 仅分配搜索工具,符合“工具不过载”原则
llm=deepseek_llm(),
verbose=True # 启用详细日志,便于调试工具调用过程
)
四、使用注意事项
- 依赖安装:使用前需安装
duckduckgo_search库,执行命令:
pip install duckduckgo_search- 关键词设计:建议搜索关键词包含 “时间范围”“领域” 等限定词(如 “2025 生成式 AI 教育应用案例”),减少无关结果;
- 结果数量控制:根据任务复杂度调整
max_results(简单任务 3-5 条,复杂任务 8-12 条),避免结果过多导致 Agent 处理效率下降; - 日志启用:开发阶段建议保留
logger.exception日志(便于定位搜索失败原因),生产阶段可根据需求关闭、。
通过该工具,Agent 可实时获取外部数据,有效解决 LLM “知识滞后” 问题,是 CrewAI 实现 “动态数据驱动任务” 的关键组件之一。
基于 MarkItDown 的 PDF 解析工具完善与封装
一、工具封装的必要性(关联文档核心逻辑)
在 CrewAI 开发中,直接使用基础解析代码无法被 Agent 调用 —— 文档明确 “工具需通过BaseTool类封装或@tool装饰器转换”,且需符合 “输入参数结构化、输出可复用、异常可捕获” 的工具设计原则()。封装后的工具可绑定到 “研究员 Agent”“文档分析 Agent” 等角色,用于提取 PDF 中的知识(如技术文档、行业报告),解决 LLM “无法直接读取本地文件” 的局限。
二、完整代码(含基础解析 + 增强特性)
"""
CrewAI工具模块 - PDF文本解析工具
基于MarkItDown实现PDF文本提取,符合CrewAI工具规范(、)
支持异常处理、结果格式化,可直接集成到Agent
"""
from __future__ import annotations
import logging
import os
from typing import Type, Optional
# 1. 导入CrewAI工具核心依赖(文档指定基础类与数据模型规范)
from crewai.tools import BaseTool
from pydantic import BaseModel, Field, ConfigDict
# 2. 导入PDF解析核心库(文档推荐MarkItDown用于PDF解析,)
from markitdown import MarkItDown
from markitdown.errors import MarkItDownError # 捕获MarkItDown专属异常
# 初始化日志(便于调试PDF解析失败原因,符合文档“可观测性”要求,)
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
# 3. 定义工具输入模型(结构化输入,避免参数混乱,)
class PDFParserToolInput(BaseModel):
"""PDF解析工具的输入参数模型(文档要求工具输入需显式定义,)"""
pdf_path: str = Field(
..., # 必选参数
description="本地PDF文件的绝对路径(如C:\\Users\\hp\\OneDrive\\桌面\\新建 DOCX 文档 (3).pdf),需确保路径无中文空格或特殊字符"
)
max_text_length: Optional[int] = Field(
None,
description="可选参数,限制输出文本长度(如10000表示最多输出10000字符),None表示输出完整文本"
)
# 4. 封装PDF解析工具类(继承BaseTool,符合CrewAI工具标准,)
class PDFParserTool(BaseTool):
"""
基于MarkItDown的PDF文本解析工具
功能:提取本地PDF中的纯文本内容,返回格式化字符串
适配场景:Agent读取PDF文档(如技术手册、行业报告)并基于内容生成分析结果
"""
# 工具核心标识(Agent配置时需引用此名称,)
name: str = "PDF Text Parser Tool"
# 工具功能描述(帮助LLM判断是否调用该工具,需具体,)
description: str = (
"用于提取本地PDF文件中的纯文本内容,支持大文件解析;"
"适用于当Agent需要读取PDF文档(如技术文档、报告、题库)以获取信息时调用;"
"输入需提供PDF文件的绝对路径,输出为格式化的纯文本(去除PDF格式符、保留段落结构)。"
)
# 绑定输入模型(确保输入参数合规,)
args_schema: Type[BaseModel] = PDFParserToolInput
# 允许额外配置(文档推荐保留灵活性,)
model_config = ConfigDict(extra="allow")
def __init__(self):
super().__init__()
# 初始化MarkItDown解析器(文档标准初始化方式,)
self.md_parser = MarkItDown()
def _validate_pdf_path(self, pdf_path: str) -> bool:
"""
输入路径校验(补充文档未提及的前置校验,避免解析失败)
校验逻辑:路径存在 + 是PDF文件 + 有读取权限
"""
# 校验路径是否存在
if not os.path.exists(pdf_path):
logger.error(f"PDF路径不存在:{pdf_path}")
return False
# 校验是否为PDF文件(通过后缀判断)
if not pdf_path.lower().endswith(".pdf"):
logger.error(f"文件非PDF格式:{pdf_path}")
return False
# 校验是否有读取权限
if not os.access(pdf_path, os.R_OK):
logger.error(f"无PDF文件读取权限:{pdf_path}")
return False
return True
def _format_extracted_text(self, raw_text: str, max_length: Optional[int]) -> str:
"""
结果格式化(符合文档“工具输出需便于Agent复用”原则,)
处理逻辑:去除多余空行、限制长度、添加格式标识
"""
# 去除连续空行,保留段落结构
formatted_text = "\n".join([line.strip() for line in raw_text.splitlines() if line.strip()])
# 限制文本长度(避免Agent处理超大数据时效率下降,)
if max_length and isinstance(max_length, int) and max_length > 0:
if len(formatted_text) > max_length:
formatted_text = formatted_text[:max_length] + f"\n\n(注:文本已截断,原始长度{len(formatted_text)}字符,当前保留{max_length}字符)"
# 添加结果标识(便于Agent区分“解析结果”与其他内容)
final_text = f"=== PDF解析结果(文件路径:{self.current_pdf_path}) ===\n{formatted_text}"
return final_text
def _run(
self,
pdf_path: str,
max_text_length: Optional[int] = None
) -> str:
"""
工具核心执行逻辑(文档要求工具需实现_run方法,)
流程:路径校验 → 解析PDF → 结果格式化 → 返回结果
"""
# 保存当前解析路径(用于格式化输出)
self.current_pdf_path = pdf_path
# 步骤1:校验输入路径(前置拦截无效输入,)
if not self._validate_pdf_path(pdf_path):
return f"> PDF解析失败:无效的PDF路径({pdf_path}),请检查路径是否存在、是否为PDF文件、是否有读取权限。"
try:
# 步骤2:执行PDF解析(文档标准解析调用方式,)
logger.info(f"开始解析PDF:{pdf_path}")
parse_result = self.md_parser.convert(pdf_path)
# 步骤3:提取纯文本(文档指定通过text_content属性获取解析结果,)
raw_text = parse_result.text_content
if not raw_text.strip():
return f"> PDF解析完成,但未提取到任何文本(可能是扫描件PDF或空白PDF,路径:{pdf_path})。"
# 步骤4:格式化结果(便于Agent后续处理,)
formatted_text = self._format_extracted_text(raw_text, max_text_length)
logger.info(f"PDF解析成功,提取文本长度:{len(raw_text)}字符(路径:{pdf_path})")
return formatted_text
# 捕获MarkItDown专属异常(如格式错误、加密PDF,)
except MarkItDownError as e:
logger.exception(f"MarkItDown解析PDF失败(路径:{pdf_path})")
return f"> PDF解析失败(MarkItDown错误):{str(e)}(可能是加密PDF或损坏文件)。"
# 捕获其他通用异常(如内存不足、IO错误,)
except Exception as e:
logger.exception(f"未知错误导致PDF解析失败(路径:{pdf_path})")
return f"> PDF解析失败(未知错误):{str(e)}(建议检查PDF文件完整性)。"
# 5. 测试代码(文档推荐工具需附带测试逻辑,便于验证功能,)
def test_pdf_parser_tool():
"""测试PDF解析工具(替换为你的PDF路径即可运行)"""
# 初始化工具
pdf_tool = PDFParserTool()
# 测试参数(替换为你的本地PDF路径)
test_pdf_path = r"C:\Users\hp\OneDrive\桌面\新建 DOCX 文档 (3).pdf"
# 执行解析
result = pdf_tool._run(
pdf_path=test_pdf_path,
max_text_length=5000 # 限制输出5000字符(可选)
)
# 打印结果
print("="*50)
print("PDF解析工具测试结果:")
print("="*50)
print(result)
# 运行测试(直接执行脚本即可验证)
if __name__ == "__main__":
test_pdf_parser_tool()
三、工具集成到 CrewAI Agent 的示例(文档标准流程)
封装后的工具需绑定到 “需要读取 PDF 的 Agent”(如 “文档研究员 Agent”),完全遵循文档 “工具按需分配” 原则(—— 不建议给无需 PDF 解析的 Agent 分配该工具,如 “内容撰稿 Agent”)。以下为集成示例:
from crewai import Agent, LLM
# 导入上面封装的PDF解析工具
from tools.pdf_parser_tool import PDFParserTool
# 1. 配置LLM(文档标准配置方式,以DeepSeek为例,)
def deepseek_llm(**kwargs):
return LLM(
model="deepseek/deepseek-chat",
api_key="sk-xxx", # 替换为你的API密钥
api_base="https://api.deepseek.com/v1",
model_kwargs={"llm_provider": "deepseek"}
)
# 2. 初始化PDF解析工具
pdf_parser_tool = PDFParserTool()
# 3. 创建“PDF文档研究员Agent”(绑定工具,)
pdf_researcher_agent = Agent(
role="PDF文档研究员",
goal="从指定PDF文件中提取关键信息,整理为结构化摘要(如核心结论、数据、案例)",
backstory="你是专注于PDF文档分析的研究员,擅长从技术手册、行业报告中提炼关键内容,能识别文本中的核心数据与逻辑关系",
llm=deepseek_llm(),
tools=[pdf_parser_tool], # 仅分配PDF解析工具(符合“工具不过载”原则,)
verbose=True # 启用日志,便于查看工具调用过程
)
# 4. 创建“PDF解析任务”(绑定Agent,)
pdf_analysis_task = Task(
description="""解析PDF文件并生成摘要:
1. 读取PDF路径:{pdf_path}
2. 提取核心内容:包括文档主题、关键结论(3-5条)、重要数据(如有)
3. 输出格式:Markdown列表,每条内容标注来源(如“第2章提及:XXX”)
4. 若未提取到文本,直接返回“无法解析该PDF文件”""",
expected_output="Markdown格式的PDF摘要,含文档主题、核心结论、数据标注",
agent=pdf_researcher_agent,
inputs={"pdf_path": r"C:\Users\hp\OneDrive\桌面\新建 DOCX 文档 (3).pdf"} # 传入你的PDF路径
)
四、关键注意事项
- 依赖安装:需先安装
markitdown库(文档指定命令,),执行:
若安装失败,可使用镜像源:pip install markitdownpip install markitdown -i https://pypi.tuna.tsinghua.edu.cn/simple - 支持的 PDF 类型:文档提及该工具仅支持 “可复制文本的 PDF”(),扫描件 PDF(图片格式)无法提取文本,需先通过 OCR 工具转换为可编辑 PDF。
- 大文件处理:若 PDF 超过 100MB,建议通过
max_text_length限制输出长度(如max_text_length=20000),避免 Agent 处理超时(符合文档 “性能优化” 中 “控制数据量” 原则,)。 - 路径格式:Windows 系统需使用 “绝对路径 + 原始字符串(r 前缀)”(如你提供的
r"C:\Users\hp\OneDrive\桌面\新建 DOCX 文档 (3).pdf"),避免路径中的反斜杠被识别为转义字符。
更多推荐

 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)