
大数据助力公共卫生危机预测
大数据分析通过整合多源数据、构建预测模型、实时监测和优化干预措施,显著提升了公共卫生危机的应对能力。未来,随着人工智能和物联网技术的发展,公共卫生管理将更加精准和高效。
·
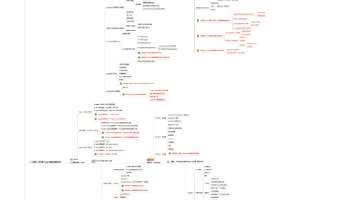
大数据分析在公共卫生危机预测与应对中的应用
公共卫生危机的预测与应对需要高效的数据处理和分析能力。大数据分析技术通过整合多源数据,构建预测模型,为公共卫生部门提供决策支持。以下从数据采集、模型构建、实时监测和干预措施等方面探讨具体方法。
数据采集与整合
公共卫生危机涉及流行病学、环境、社会经济等多维度数据。数据来源包括:
- 医疗系统数据:电子健康记录(EHR)、医院就诊数据、实验室检测结果。
- 社交媒体数据:Twitter、微博等平台的舆情信息。
- 环境数据:气象数据、空气质量指数(AQI)。
- 移动设备数据:GPS轨迹、手机信令数据。
使用Python的pandas库可以高效整合多源数据:
import pandas as pd
# 加载医疗数据
medical_data = pd.read_csv('medical_records.csv')
# 加载社交媒体数据
social_media_data = pd.read_json('twitter_posts.json')
# 合并数据
merged_data = pd.merge(medical_data, social_media_data, on='timestamp')
构建预测模型
机器学习模型可用于预测疾病传播趋势。常用的算法包括:
- 时间序列模型:ARIMA、LSTM。
- 分类模型:随机森林、支持向量机(SVM)。
以下是一个基于LSTM的流行病预测示例:
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# 准备数据
def create_dataset(data, time_steps=10):
X, y = [], []
for i in range(len(data) - time_steps):
X.append(data[i:i+time_steps])
y.append(data[i+time_steps])
return np.array(X), np.array(y)
# 假设cases是历史病例数据
cases = np.array([100, 150, 200, 250, 300, 350, 400, 450, 500, 550])
X, y = create_dataset(cases, time_steps=3)
# 构建LSTM模型
model = Sequential()
model.add(LSTM(50, activation='relu', input_shape=(3, 1)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
# 训练模型
model.fit(X, y, epochs=200, verbose=0)
实时监测与预警
实时数据流处理技术(如Apache Kafka)可用于监测疫情动态。结合可视化工具(如Tableau或Matplotlib),可以快速生成预警报告。
import matplotlib.pyplot as plt
# 模拟实时数据
time_points = range(1, 11)
cases = [100, 150, 200, 250, 300, 350, 400, 450, 500, 550]
# 绘制趋势图
plt.plot(time_points, cases, marker='o')
plt.xlabel('Days')
plt.ylabel('Cases')
plt.title('Epidemic Trend')
plt.show()
干预措施优化
基于大数据的模拟可以评估不同干预措施的效果。例如,通过Agent-Based Modeling(ABM)模拟社交距离政策的影响。
import mesa
class EpidemicModel(mesa.Model):
def __init__(self, N):
self.num_agents = N
self.schedule = mesa.time.RandomActivation(self)
self.grid = mesa.space.MultiGrid(10, 10, True)
for i in range(self.num_agents):
a = PersonAgent(i, self)
self.schedule.add(a)
x = self.random.randrange(self.grid.width)
y = self.random.randrange(self.grid.height)
self.grid.place_agent(a, (x, y))
class PersonAgent(mesa.Agent):
def __init__(self, unique_id, model):
super().__init__(unique_id, model)
self.state = 'Susceptible'
def step(self):
neighbors = self.model.grid.get_neighbors(self.pos, moore=True, include_center=False)
for neighbor in neighbors:
if neighbor.state == 'Infected':
if self.random.random() < 0.1:
self.state = 'Infected'
数据隐私与伦理
在利用大数据时,需遵守隐私保护法规(如GDPR)。匿名化技术和差分隐私是常见解决方案。以下是一个简单的数据匿名化示例:
import hashlib
def anonymize_data(column):
return column.apply(lambda x: hashlib.sha256(x.encode()).hexdigest())
# 匿名化姓名列
medical_data['patient_name'] = anonymize_data(medical_data['patient_name'])
总结
大数据分析通过整合多源数据、构建预测模型、实时监测和优化干预措施,显著提升了公共卫生危机的应对能力。未来,随着人工智能和物联网技术的发展,公共卫生管理将更加精准和高效。
更多推荐
 3
3 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)