【LangChain RAG从零学】Overview
【LangChain RAG从零学】Overview
前言
- 该篇为【LangChain RAG从零学】的第一章,旨在记录学习RAG的过程
RAG基本概念
什么是检索增强LLM
- 检索增强LLM (Retrieval Augmented LLM),就是给LLM提供数据库,对于用户的问题 (Query),通过信息检索技术,先从外部数据库中检索出和用户问题相关的信息,然后让LLM结合这些信息 (Context)来生成结果
- 本质上属于提示词工程

- 传统的信息检索工具 (Google/Bing),只有检索功能;LLM通过预训练,将大量数据和知识嵌入进模型参数中,具有记忆能力
- 增强检索LLM处于两者之间,将检索到的相关信息打包放入LLM的工作内存中,即为LLM的上下文窗口 (Context Window)
解决的问题
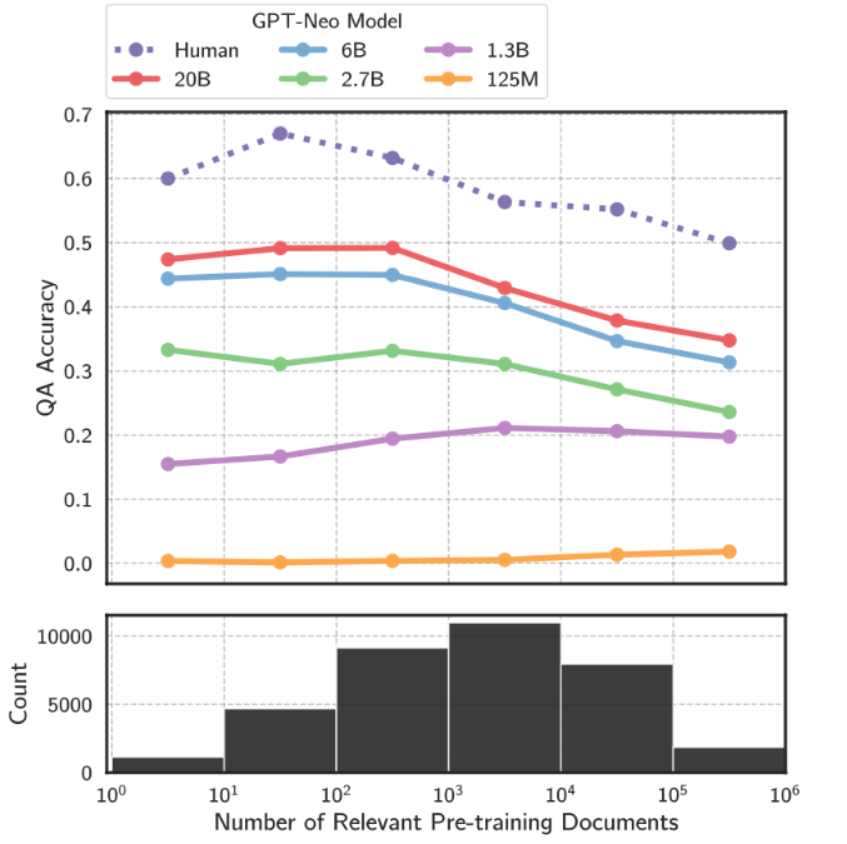
长尾知识
-
对于一些相对通用的大众知识,LLM通常能够生成比较准确的结果,而对于一些长尾知识,生成的回答就不那么可靠
-
研究发现:在预训练阶段中,相关的文档越多,LLM事实性的回答就越准确
-
为了解决这个问题,我们很容易想到的解决方案就是在训练数据中加入更多的长尾知识和增大模型的参数量
-
但这两种方法是不经济的且没有复用性,而通过检索的方法把相关信息在LLM推理时加入到上下文窗口中,回复准确性高且经济
私有数据
-
通用LLM预训练阶段使用的数据都是公开的数据,不包含私有数据,因此对于私有领域的知识是有所欠缺的
-
虽然可以在预训练阶段加入私有数据进行训练,但有研究表明:通过一些特有攻击手段会让LLM敏感数据泄露
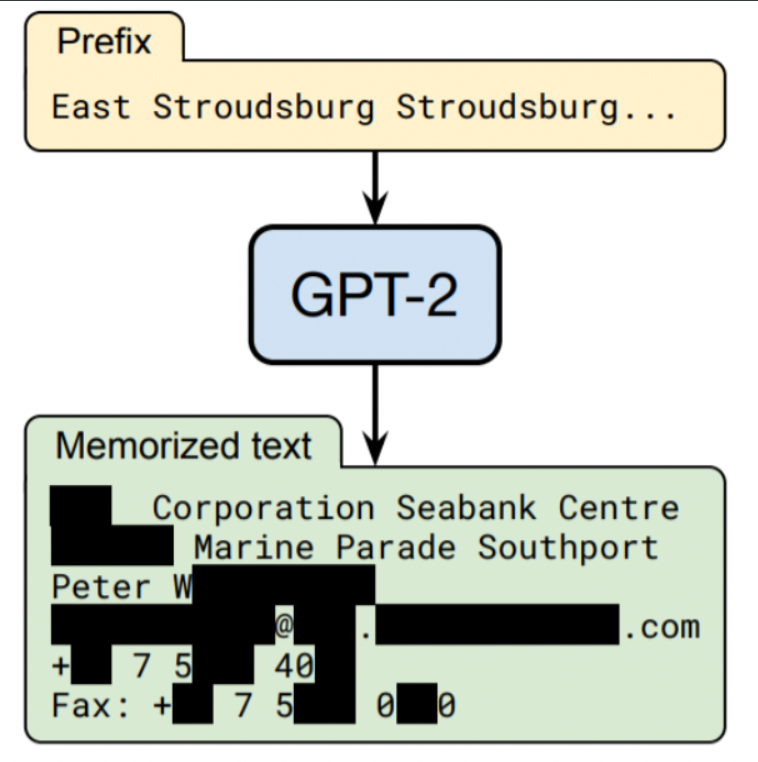
- 实践表明:较大规模的模型比较小规模的模型更容易受到攻击
数据新鲜度
-
由于LLM学习的数据来自预训练数据,所以LLM学到的知识很容易过时
-
如果把可以频繁更新的知识作为外部知识库,在LLM推理时进行检索,就可以在不重复训练的基础上提高回答准确度
关键模块
数据和索引模块
数据获取
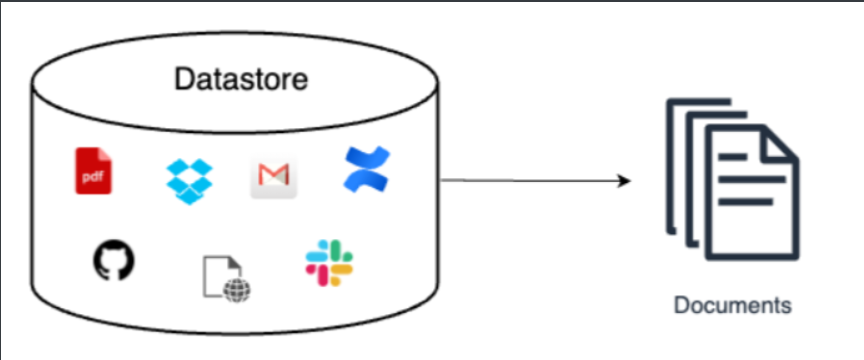
- 数据获取模块一般是将多种来源、多种类型和格式的外部数据转换为一个统一的文档对象
- 文档对象除了包括原始的文本内容外还会带上文档的元信息,可以用于后期的检索和过滤
- 元信息可以借助NLP技术获得,如关键词抽取、实体识别、文本分类等
文本分块
- 文本分块是将长文本切分成片段的过程
- 考虑到LLM的上下文长度是有限制的;同时只匹配相关的文本段可以为后续生成过滤一些不需要的噪声
- 文本分块的好坏影响着后续生成的质量,好的切分策略很重要
分块实现方法
- 将原始文本切分为小的语义单元,句子级别或者段落级别
- 将小的语义单元融合成更大的块,直到达到设定的块的大小(Chunk Size),就将该块作为独立的文本片段
- 迭代构建下一个文本片段,一般相邻的文本片段之间会设置重叠,以保持语义的连贯性
LangChain相应实现
from langchain.text_splitter import CharacterTextSplitter
from langchain.text_splitter import RecursiveCharacterTextSplitter, Language
# text split
text_splitter = RecursiveCharacterTextSplitter(
# 设置一个较小的块大小
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
# code split
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON,
chunk_size=50,
chunk_overlap=0
)
# markdown split
md_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.MARKDOWN,
chunk_size=60,
chunk_overlap=0
)
数据索引
-
索引是一个经过特殊处理和优化的数据结构,用于快速检索出与用户查询相关的文本内容
-
链式索引:通过链表的结构对文本块进行顺序索引
-
树索引:将一组节点(文本块)构建成具有层级的树状索引
-
关键词索引:从每个节点中提取出关键词,构建了每个关键词到相应节点的多对多关系
-
向量索引:利用文本嵌入模型(Text Embedding Model)将文本映射为高维空间的一个向量
查询和检索模块
查询变换
- 查询文本的表达影响着检索结果,直接使用原始的查询文本可能会导致查询效果差
- 需要对查询文本进行一些变换,以获得更好的搜索结果
- 具体的方法在下一章中详细介绍
排序和后处理
通过检索之后可能会获得很多相关文档,需要进行筛选和排序
- 基于相似度分数进行过滤和排序
- 基于关键词进行过滤
- 基于返回的相关文档和相关性得分重新排序
- 基于时间排序,如只筛选最新的相关文档
回复生成模块
回复生成策略
- stuff(全部填充):将检索到的所有文档片段一次性的填充到Prompt中的特定位置({context})
- Map-Reduce(映射-合并):将检索到的每个文档片段与问题结合并行地发给LLM,让LLM生成初步回答然后合并起来发给LLM最后生成一个最终统一地文档
- Refine(迭代):将问题和第一个文档片段发给LLM,然后将初步回答和问题加上第二个文档发送给LLM,重复这个过程
手动搭建
环境设置
-
LangSmith:监控每一步地输出过程,便于调试
-
Google AI Studio:免费调用大模型API
代码实现
! pip install langchain_community tiktoken langchainhub chromadb langchain langchain-google-genai
import os
# 配置LangSmith
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = 'https://api.smith.langchain.com'
os.environ['LANGCHAIN_API_KEY'] = 'YOUR_API_KEY'
# 配置Gemini API密钥
os.environ["GOOGLE_API_KEY"] = "YOUR_API_KEY"
import bs4
import os
from langchain import hub
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_google_genai import ChatGoogleGenerativeAI, GoogleGenerativeAIEmbeddings
# 加载文档
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
- 抓取目标网站中的特定信息(一篇关于Agent的Blog)
- Beautiful Soup过滤筛选:class属性,文章标题、元信息和内容
# 文本分块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# 嵌入模型 - 选择效果最好的模型 text-embeding-004
vectorstore = Chroma.from_documents(documents=splits,embedding=GoogleGenerativeAIEmbeddings(model="models/text-embedding-004"))
retriever = vectorstore.as_retriever()
# Prompt
# 拉取prompt模板
prompt = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash", temperature=0)
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# Question
rag_chain.invoke("What is Task Decomposition?")
结果分析
- 最终结果
Task decomposition is breaking down a complex task into smaller, simpler subtasks. This can be achieved through prompting techniques like Chain of Thought, or by using external planners. It improves model performance and allows for easier problem-solving.

- 检索结果
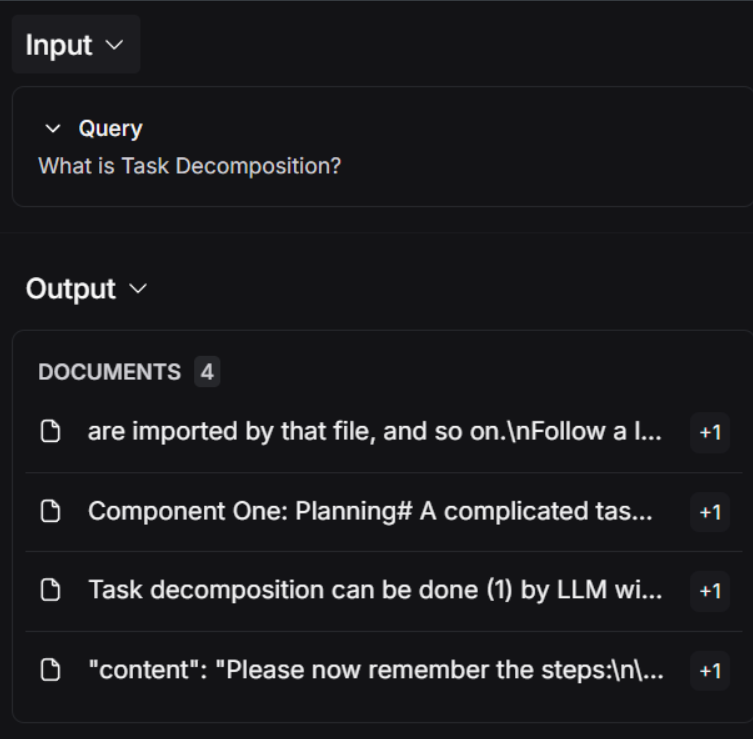
- 清洗后结果
are imported by that file, and so on.\nFollow a language and framework appropriate best practice file naming convention.\nMake sure that files contain all imports, types etc. The code should be fully functional. Make sure that code in different files are compatible with each other.\nBefore you finish, double check that all parts of the architecture is present in the files.\n"
Component One: Planning#
A complicated task usually involves many steps. An agent needs to know what they are and plan ahead.
Task Decomposition#
Chain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.
Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.
Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
Another quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain Definition Language (PDDL) as an intermediate interface to describe the planning problem. In this process, LLM (1) translates the problem into “Problem PDDL”, then (2) requests a classical planner to generate a PDDL plan based on an existing “Domain PDDL”, and finally (3) translates the PDDL plan back into natural language. Essentially, the planning step is outsourced to an external tool, assuming the availability of domain-specific PDDL and a suitable planner which is common in certain robotic setups but not in many other domains.
Self-Reflection#
"content": "Please now remember the steps:\n\nThink step by step and reason yourself to the right decisions to make sure we get it right.\nFirst lay out the names of the core classes, functions, methods that will be necessary, As well as a quick comment on their purpose.\n\nThen you will output the content of each file including ALL code.\nEach file must strictly follow a markdown code block format, where the following tokens must be replaced such that\nFILENAME is the lowercase file name including the file extension,\nLANG is the markup code block language for the code's language, and CODE is the code:\n\nFILENAME\n```LANG\nCODE\n```\n\nPlease note that the code should be fully functional. No placeholders.\n\nYou will start with the \"entrypoint\" file, then go to the ones that are imported by that file, and so on.\nFollow a language and framework appropriate best practice file naming convention.\nMake sure that files contain all imports, types etc. The code should be fully
- 最终prompt构建(模板+相关文档)
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: What is Task Decomposition?
Context: are imported by that file, and so on.\nFollow a language and framework appropriate best practice file naming convention.\nMake sure that files contain all imports, types etc. The code should be fully functional. Make sure that code in different files are compatible with each other.\nBefore you finish, double check that all parts of the architecture is present in the files.\n"
Component One: Planning#
A complicated task usually involves many steps. An agent needs to know what they are and plan ahead.
Task Decomposition#
Chain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.
Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.
Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
Another quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain Definition Language (PDDL) as an intermediate interface to describe the planning problem. In this process, LLM (1) translates the problem into “Problem PDDL”, then (2) requests a classical planner to generate a PDDL plan based on an existing “Domain PDDL”, and finally (3) translates the PDDL plan back into natural language. Essentially, the planning step is outsourced to an external tool, assuming the availability of domain-specific PDDL and a suitable planner which is common in certain robotic setups but not in many other domains.
Self-Reflection#
"content": "Please now remember the steps:\n\nThink step by step and reason yourself to the right decisions to make sure we get it right.\nFirst lay out the names of the core classes, functions, methods that will be necessary, As well as a quick comment on their purpose.\n\nThen you will output the content of each file including ALL code.\nEach file must strictly follow a markdown code block format, where the following tokens must be replaced such that\nFILENAME is the lowercase file name including the file extension,\nLANG is the markup code block language for the code's language, and CODE is the code:\n\nFILENAME\n```LANG\nCODE\n```\n\nPlease note that the code should be fully functional. No placeholders.\n\nYou will start with the \"entrypoint\" file, then go to the ones that are imported by that file, and so on.\nFollow a language and framework appropriate best practice file naming convention.\nMake sure that files contain all imports, types etc. The code should be fully
Answer:
参考文献

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐


 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)