本地化部署deepseek指南(Hugging Face部署/Ollama部署)
本文是本地化部署DeepSeek大语言模型的详细指南,涵盖环境准备、模型下载、部署运行等关键步骤。
本文是本地化部署DeepSeek大语言模型的详细指南,涵盖环境准备、模型下载、部署运行等关键步骤:
一、环境准备
1. 硬件要求
- GPU配置(推荐):
- DeepSeek-7B:单卡至少16GB显存(如RTX 3090/4090、A100-20GB)
- DeepSeek-67B:多卡环境,单卡至少24GB显存(如4×A100-40GB)
- CPU配置(仅用于测试,速度极慢):
- 至少32GB内存,推荐64GB以上
- 硬盘空间:至少预留50GB(7B模型约15GB,67B模型约130GB)
2. 软件依赖
- 操作系统:Linux(推荐Ubuntu 20.04/22.04)或Windows(需WSL2)
- Python:3.8~3.11
- CUDA:11.7+(如需GPU加速,需匹配NVIDIA驱动)
- 其他工具:git、pip
二、基础环境安装
1. 安装Python及虚拟环境
# 安装Python
sudo apt update && sudo apt install python3 python3-pip python3-venv
# 创建虚拟环境
python3 -m venv deepseek-env
source deepseek-env/bin/activate # Linux/Mac
# 或 Windows: deepseek-env\Scripts\activate
2. 安装PyTorch
根据CUDA版本选择对应命令(参考PyTorch官网):
# 示例:CUDA 11.8
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# CPU-only版本(不推荐)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
三、使用Hugging Face部署DeepSeek
DeepSeek模型开源在Hugging Face Hub,可通过huggingface-cli或直接下载。
1. 安装Hugging Face工具
pip install transformers accelerate sentencepiece huggingface-hub
2. 登录Hugging Face(需注册账号并同意模型协议)
huggingface-cli login
# 按提示输入Hugging Face令牌(在官网个人设置中获取)
3. 下载模型(以DeepSeek-7B-Chat为例)
from transformers import AutoModelForCausalLM, AutoTokenizer
# 下载并加载模型(首次运行会自动下载,耗时较长)
model_name = "deepseek-ai/deepseek-chat"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto", # 自动分配设备(GPU/CPU)
torch_dtype="auto" # 自动选择数据类型
)
4. 手动下载(可选)
若网络不稳定,可从DeepSeek官网或Hugging Face手动下载模型文件,解压后指定本地路径加载:
model = AutoModelForCausalLM.from_pretrained(
"./local/deepseek-chat", # 本地模型路径
device_map="auto"
)
四、使用Ollama部署DeepSeek(推荐新手)
Ollama是一款轻量级大模型部署工具,支持一键运行多种开源模型,包括DeepSeek,极大简化部署流程。
1. 安装Ollama
-
Linux:
curl https://ollama.com/install.sh | sh -
macOS:
从Ollama官网下载.dmg安装包,或使用Homebrew:brew install ollama -
Windows:
从官网下载.exe安装包,或通过WSL2安装Linux版本
2. 启动Ollama服务
# 启动服务(后台运行)
ollama serve &
# 验证服务是否正常运行
curl http://localhost:11434
# 正常响应应为:Ollama is running
3. 运行DeepSeek模型
Ollama支持多种DeepSeek模型,包括:
deepseek:基础对话模型(7B参数)deepseek-coder:代码生成模型deepseek-vl:多模态视觉语言模型
登录Ollama官网点击Models,搜索模型(以deepseek为例子),点击 r1 模型。
在展开的页面中,点击右上角复制按钮。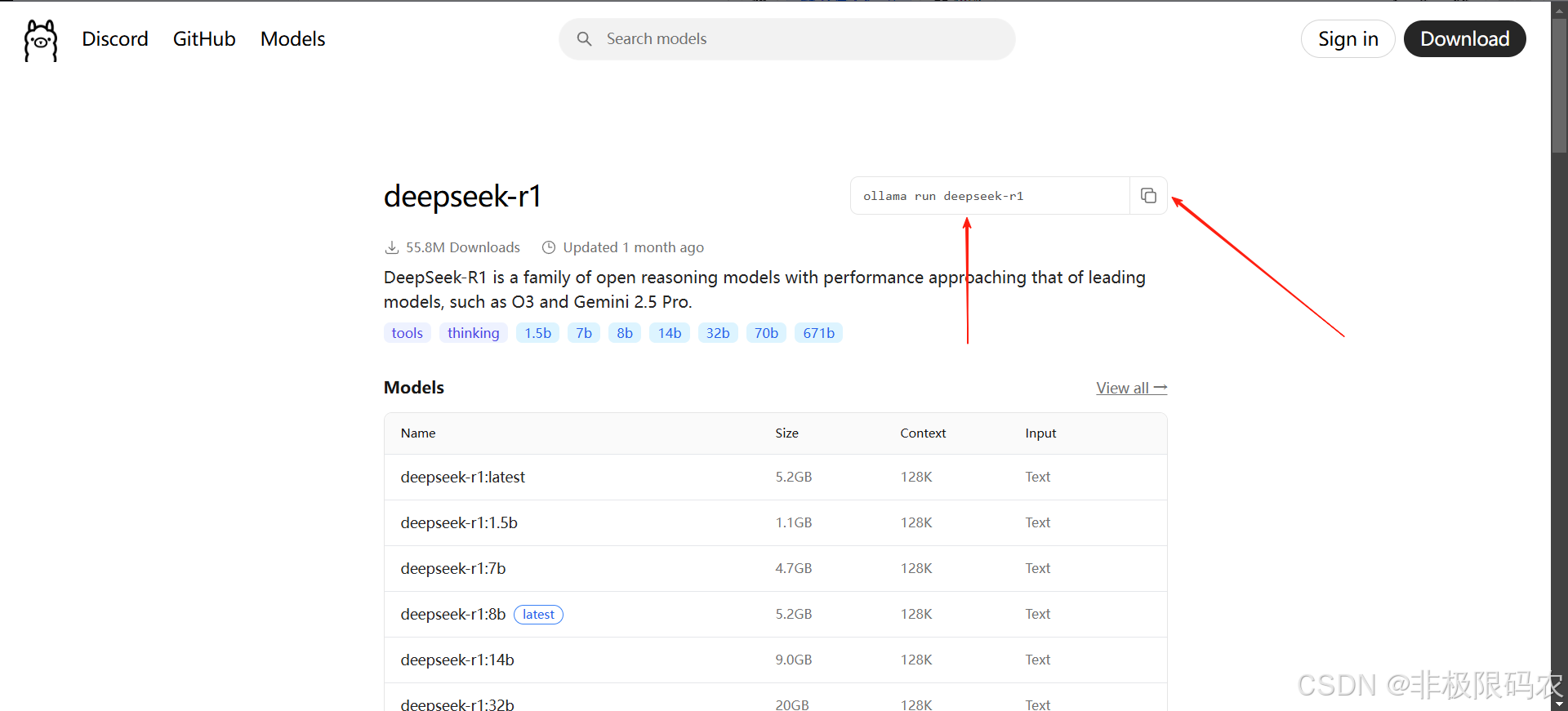
# 将复制到的内容粘贴并运行DeepSeek对话模型(首次运行会自动下载)
ollama run deepseek-r1
# 模型加载完成后,直接输入问题进行交互
>>> 你好,请介绍一下自己
4. 自定义模型配置(可选)
创建模型配置文件(如deepseek-custom.Modelfile):
FROM deepseek
PARAMETER temperature 0.7
PARAMETER max_tokens 2048
SYSTEM "你是一个专业的AI助手,专注于技术问题解答"
构建并运行自定义模型:
ollama create deepseek-custom -f deepseek-custom.Modelfile
ollama run deepseek-custom
5. 通过API调用Ollama部署的模型
Ollama内置API服务,可通过HTTP请求调用:
发送请求示例:
curl http://localhost:11434/api/generate -d '{
"model": "deepseek",
"prompt": "解释一下机器学习中的过拟合现象",
"stream": false
}'
Python调用示例:
import requests
import json
def call_ollama(prompt, model="deepseek"):
url = "http://localhost:11434/api/generate"
data = {
"model": model,
"prompt": prompt,
"stream": False
}
response = requests.post(url, json=data)
return json.loads(response.text)["response"]
# 使用示例
print(call_ollama("什么是Docker容器?"))
五、模型运行与测试
1. 基础推理示例
def generate_response(prompt, max_length=200):
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_length=max_length,
temperature=0.7, # 控制随机性,0~1
do_sample=True
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# 测试对话
prompt = "你好,请介绍一下DeepSeek模型"
print(generate_response(prompt))
2. 优化显存占用
-
量化加载(推荐4-bit/8-bit量化):
pip install bitsandbytesmodel = AutoModelForCausalLM.from_pretrained( model_name, device_map="auto", load_in_4bit=True, # 4-bit量化,显存需求降低75% # load_in_8bit=True, # 8-bit量化,显存需求降低50% quantization_config=BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16 ) ) -
梯度检查点:
model.gradient_checkpointing_enable()
六、部署为API服务(可选)
使用FastAPI构建简单API接口:
1. 安装依赖
pip install fastapi uvicorn
2. 编写API服务代码(main.py)
from fastapi import FastAPI
from pydantic import BaseModel
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
app = FastAPI()
model_name = "deepseek-ai/deepseek-chat"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
load_in_4bit=True
)
class PromptRequest(BaseModel):
prompt: str
max_length: int = 200
@app.post("/generate")
def generate(request: PromptRequest):
inputs = tokenizer(request.prompt, return_tensors="pt").to(model.device)
outputs = model.generate(** inputs, max_length=request.max_length, temperature=0.7)
return {"response": tokenizer.decode(outputs[0], skip_special_tokens=True)}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
3. 启动服务
python main.py
通过http://localhost:8000/docs访问API测试界面。
七、常见问题解决(Hugging Face相关)
-
显存不足:
- 改用更小的模型(如7B→1.3B)
- 启用4-bit量化
- 减少生成文本长度(
max_length)
-
下载速度慢:
- 使用Hugging Face镜像(如
https://hf-mirror.com) - 手动下载模型文件后本地加载
- 使用Hugging Face镜像(如
-
推理速度慢:
- 确保使用GPU加速(检查
model.device是否为cuda) - 降低
max_length或使用temperature=0(确定性生成)
- 确保使用GPU加速(检查
八、常见问题解决(Ollama相关)
-
Ollama模型下载慢:
# 设置代理(示例) export HTTPS_PROXY=http://localhost:7890 ollama run deepseek -
更改Ollama默认端口:
OLLAMA_HOST=0.0.0.0:8080 ollama serve -
查看已安装的模型:
ollama list -
删除模型释放空间:
ollama rm deepseek
九、两种部署方式对比
| 特性 | Ollama部署 | Hugging Face部署 |
|---|---|---|
| 操作难度 | 简单(单命令) | 中等(需代码知识) |
| 灵活性 | 一般 | 高(可深度定制) |
| 资源占用 | 较低(优化较好) | 较高 |
| 适合人群 | 新手、快速部署 | 开发者、二次开发 |
| 启动速度 | 快 | 较慢(首次加载) |
根据需求选择合适的部署方式:快速体验推荐Ollama,开发定制推荐Hugging Face方法。
十、注意事项
- 模型许可证:DeepSeek遵循Apache 2.0协议,允许商业使用,但需遵守开源协议
- 定期更新:关注DeepSeek官方仓库获取最新模型和工具
- 安全部署:公开服务时建议添加身份验证和请求限制
通过以上步骤,即可在本地环境部署DeepSeek模型并进行测试或二次开发。根据实际硬件条件调整配置,可获得更优的运行效果。
希望本文可以提供帮助,具体内容仅供参考。

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)