
具身智能论文综述详读
关于一个survey的阅读内容和自己浅薄的理解
title: A Survey on Vision-Language-Action Models for Embodied AI
视觉-语言-动作模型(VLA)代表一类旨在处理多模态输入的模型,结合视觉、语言和动作模态的信息。
在语言为条件的机器人任务中,策略必须具备理解语言****指令、视觉感知环境并生成适当动作的能力,这就需要VLA的多模态能力。
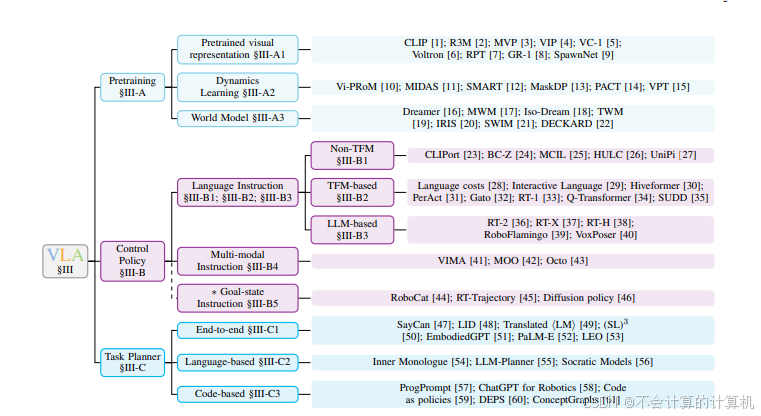
我们介绍了当前机器人系统中分层结构的分类法,包括三个主要部分:预训练、控制策略和任务计划器。预训练技术旨在增强 VLA 的特定方面,如视觉编码器或动力学模型。低级控制策略根据指定的语言命令和感知环境执行低级动作。高级任务规划器将长视距任务分解为可由控制策略执行的子任务。
问题1:如何处理多模态?
从原本的cnn和rnn联合到现在的transformer,在transformer里也有不同的处理方法:
- 单流transformer,所有的模态的token不做区分(生成token肯定还是靠embedding),合到一起去训练。
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision (ViLT) [3]
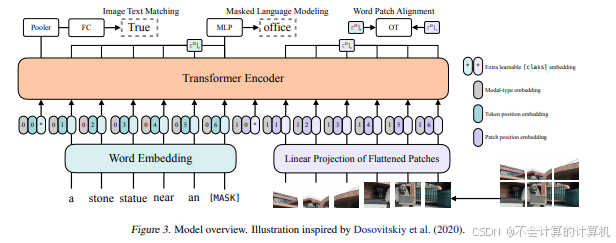
ViLT是一个简洁的单流多模态Transformer模型,其中语言和视觉模态共享的Transformer Encoder在输入时同时接受两个模态的Token。相较于UNITER,模型中嵌入器部分十分简单,语言模态的输入通过Word Embedding Matrix计算得到Word Embedding,而视觉模态则直接通过Patch Projection的方式转化为Token,每个模态的Token还加入了Position Embedding和区分模态的Modal-type embedding。在本文中,作者也提到采用单流架构的原因是双流模型会引入额外的参数。
- 多流,对于每个模态区分encoder

高级任务规划器:将任务区分成简单任务的流程
低级任务执行器:执行简单的低级任务(我认为这块也有说头)
问题2:如何提升一个vla的质量
- 预训练提升模型质量:
视觉编码器的有效性直接影响策略的性能,因为它提供有关目标类别、位置和环境可供性的关键信息。因此,许多方法都致力于对视觉编码器进行预训练,以提高 PVR 的质量。
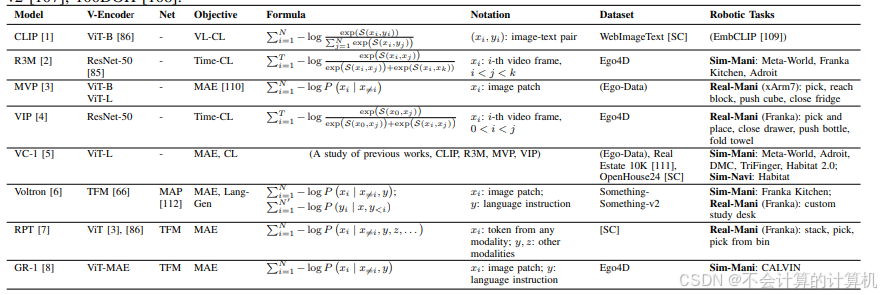
两个对预训练的量化标准:时间对比学习的目标是最小化时间上接近的视频帧之间的距离,同时增加时间上较远的帧之间的间隔。这一目标旨在创建能捕捉视频序列中时间关系的 PVR。另一方面,视频语言对齐是为了了解视频是否与语言指令相对应。这一目标丰富了 PVR 中的语义相关性。

另一个对齐应该就是做图像文本对儿
- 动态学习
动态学习包含旨在使模型了解正向或逆向动态的目标。正向动态涉及预测给定动作导致的后续状态,而逆向动态则涉及确定从先前状态过渡到已知后续状态所需的动作。一些研究方法还将这些目标定义为对混洗状态序列进行重新排序的问题。虽然正向动态模型与世界模型密切相关,不过这里特别关注利用动态学习作为辅助任务来提高主要机器人任务性能的工作。(一个是从过程推结果,一个是从结果推理了过程
- 世界模型
世界模型就是仿真建立一个世界的交互模型,本质上也是一种动态学习?
总结一下,预训练的视觉表征强调了视觉编码器的重要性,因为视觉观察在感知环境的当前状态方面起着至关重要的作用。因此,它为整个模型的性能设定了上限。在 VLA 中,一般视觉模型使用机器人或人类数据进行预训练,以增强其在目标检测、可供性图提取甚至视觉语言对齐等任务中的能力,这些任务对于机器人任务至关重要。相比之下,动态学习侧重于理解状态之间的转换。这不仅涉及将视觉观测映射到良好的状态表征,还涉及理解不同的动作如何导致不同的状态,反之亦然。现有的动态学习方法通常旨在使用简单的掩码建模或重新排序目标来捕捉状态和动作之间的关系。另一方面,世界模型旨在完全模拟世界的动态,使机器人模型能够根据当前状态将状态推广到未来的多个步骤,从而更好地预测最佳动作。因此,虽然世界模型更受欢迎,但实现起来也更具挑战性。
问题3:解决控制策略的框架问题
如何通过结构或者训练方式使得机器人学习解决问题?
- 将两个模态的东西分开来处理,图像当成位置信息,语言做指令信息分开训练
- 将学习过程中引入一些架构技术,比如机器人学习的分层分解、多模态转换器和离散潜在计划
- 策略即是视频,根据语言生成视频并做反动力学推理。
- transformer和llm可以让用户用语言监督
- PereAct提出了3d voxel能让动作学习处理更多视角观察结果,更能输出交互运动的最佳voxel(我理解是一种高级的建模方法?
建立三维体素通过多个摄像头对绝对空间坐标的统一完成对周边的环境建模;
做动作是将动作离散化到网格里,通过目标位置-旋转动作-夹爪旋转-夹爪状态进行离散化训练,将体素内的特征编码为一系列三维补丁。
具体动作:
PERACT将动作空间离散化到体素网格中,以适应6-DoF(六自由度)操作。这种离散化的动作空间包含了:
- 平移动作:即在三维空间中选取目标体素的中心作为机器人手爪的目标位置。(不过也没啥问题,就是可能精确任务不精准?
- 旋转动作:将旋转角度分离到三轴方向,每个轴的旋转被离散到5度的角度区间,从而形成离散化的旋转动作空间。
- 夹爪状态:二值离散化,即“夹持”或“放开”。
- 碰撞检测:二值化的碰撞避免状态,即机器人在执行动作时选择“避免碰撞”或“允许碰撞”。
- Gato做了多任务协调的一个统一的标准方案
- 底层新增一个动作结构层,在语言和低级动作之间,可以叫高级动作
- voxposer通过llm将语言指令翻译成可执行代码,调用vlm来获取对象坐标,采用模型预测控制为机械臂的末端执行器来生成运动规划
问题4:解决模型的动作问题
- 低级控制策略都是预测末端执行器姿势的动作,同时抽象出利用反运动学控制单个关节运动的运动规划模块。虽然这种抽象有利于更好地泛化到不同的实施方案中,但也对灵巧性造成了限制。
- 行为克隆(BC)对于连续离散处理方式都不同
- 扩散策略(diffusion policy)
基于扩散的策略利用了计算机视觉领域中扩散模型的成功。其中,扩散策略[46]是最早利用扩散进行动作生成的策略之一。SUDD为扩散策略添加了语言条件支持。Octo采用模块化设计,以适应各种类型的提示和观察。与常见的行为克隆策略相比,扩散策略在处理多模态动作分布和高维动作空间方面表现出优势。
问题4延申:diffusion policy
将机器人的视觉运动策略(visuomotor policy)表示为条件去噪扩散过程(conditional denoising diffusion process)
Diffusion Policy 可以学习动作分布得分函数的梯度(gradient of the action-distribution score),并在推理过程中通过一系列随机朗之文动力学(stochastic Langevin dynamics)步骤对该梯度场进行迭代优化
训练过程的第一步是从数据集中随机抽取未经修改的样本 x0。对于每个样本,我们随机选择一个去噪迭代 k,然后为迭代 k 采样一个具有适当方差的随机噪声 εk。噪声预测网络需要从添加了噪声的数据样本中预测噪声。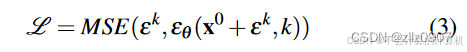
使用均方误差(MSE, Mean Squared Error)作为损失函数,来衡量网络的预测值 𝜖𝜃(𝑥0+𝜖𝑘,𝑘) 和实际噪声 𝜖𝑘 之间的差异。
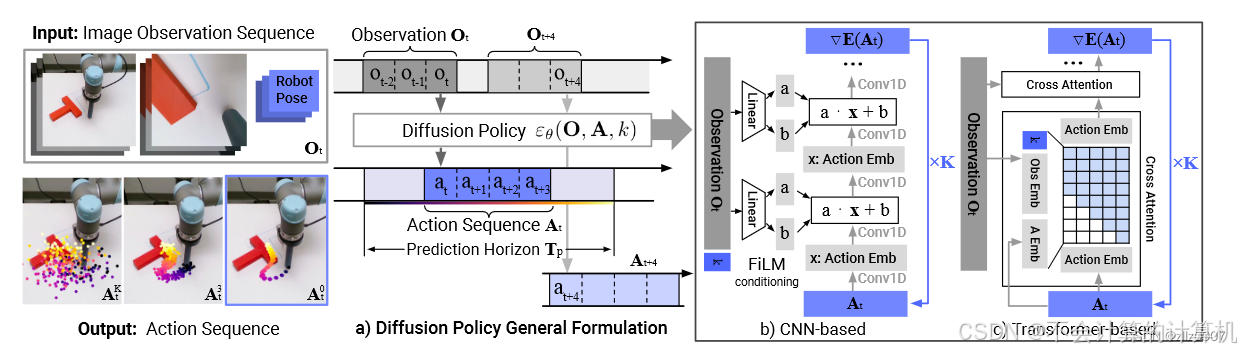
扩散策略概述 a) 一般表述。在时间步长 t,该策略将最新 To 步的观测数据 Ot 作为输入,并输出 Ta 步的行动 At。 b) 在基于 CNN 的扩散策略中,Perez 等人(2018 年)将观测特征 Ot 的 FiLM(Feature-wise Linear Modulation)调理应用于每个卷积层,按通道进行调理。c) 在基于transformer的 Vaswani 等人(2017)扩散策略中,观测特征 Ot 的嵌入被传递到每个变换器解码块的多头交叉注意层。利用图示的注意力掩码,每个动作嵌入只关注自身和之前的动作嵌入(因果注意力)。
问题5:解决任务规划问题(从任务变成指令的过程):
直接用LLM理解单次的简单任务比较容易,但是长期的复杂任务就很难处理,主要还是任务分解的思路。
延申:如何分解
将LLM照着这个方向训练准没错,就是训练中整什么花活:
- 引入一个主动数据收集,对不成功的任务分派进行重新分配并再训练,可以利用到失败的数据。
- 两步法的框架,先将高级指令分解为短语,再将短语转换为动作。
- 三步法:分割、标记和参数更新。在分割步骤中,高级子任务与低级动作对齐,然后在标记步骤中推断出子任务描述,最后更新网络参数。
- 分两段,一段对齐视觉语言,一段对齐动作指令调整
- 当然直接用prompt工程也可以对LLM做任务分解进行提示
分割、标记和参数更新。在分割步骤中,高级子任务与低级动作对齐,然后在标记步骤中推断出子任务描述,最后更新网络参数。 - 分两段,一段对齐视觉语言,一段对齐动作指令调整
- 当然直接用prompt工程也可以对LLM做任务分解进行提示
- 环境和API调用模式,ChatGPT for Robotics

分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐



 39
39 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)