Subject-Diffusion: Open Domain Personalized Text-to-Image Generation without Test-time Fine-tuning
LaLaβ⋅tanhγ⋅S([Lahe])heMLP([vFourierl)])LaβγSvl。
·
- 问题引入
- 针对的是不需要test time finetuning的subject driven image generation,且能实现multi-subject生成;
- 两个特点,open domain + test time finetuning free
- methods
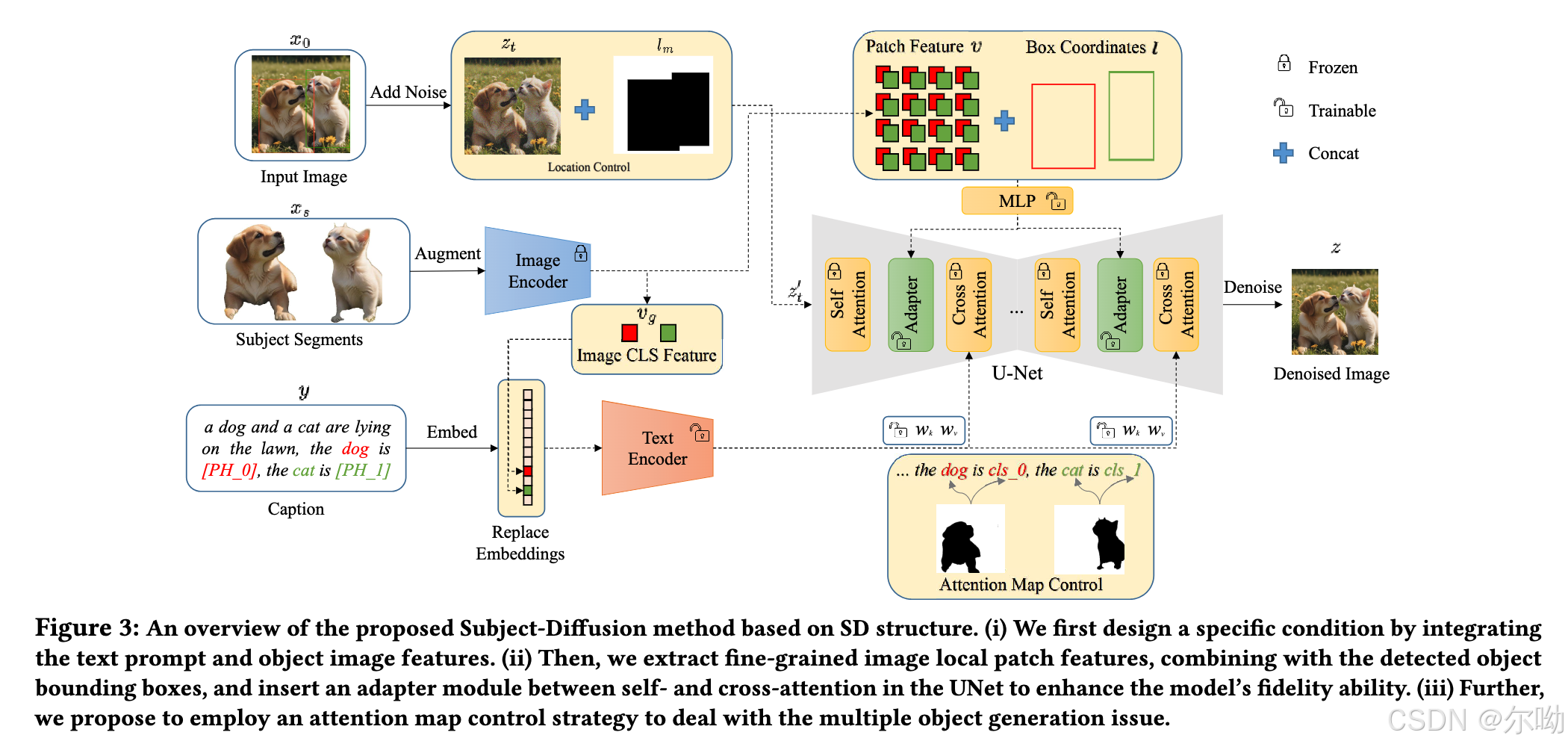
- Dataset Construction:首先使用BLIP2来对图片进行caption,之后将caption中的entity提取出来(spacy),使用grounding dino的方法获取对应的bounding box,之后使用bbox为prompt通过sam得到对应的mask,最后的数据包含image-text pair, bounding box, segmentation mask, label,总共的数据量为76M;
- Fusion text encoder:image feature包含两个部分,image embedding+feature patch embedding,其中前者和text embedding融合且融合方式类似,如图所示,值得注意的是融合的位置是在text encoder之前,text encoder的参数在训练中没有被冻结;
- Dense image and object location control:image patch embedding和model融合的方式是在self attn层以及cross attn层中间添加adapter,该adapter的操作是 L a = L a + β ⋅ t a n h ( γ ) ⋅ S ( [ L a , h e ] ) , h e = M L P ( [ v , F o u r i e r ( l ) ] ) L_a = L_a + \beta\cdot tanh(\gamma)\cdot S([L_a,h^e]),h^e = MLP([v,Fourier(l)]) La=La+β⋅tanh(γ)⋅S([La,he]),he=MLP([v,Fourier(l)]),其中 L a L_a La是self attn的输出, β \beta β是一个超参,平衡adapter的影响, γ \gamma γ是一个可学习的参数,初始化为0, S S S是self attn操作, v v v是image patch feature, l l l是coordinate position information;
- 在训练的过程中text encoder+cross attn的k,v linear+adapter是可以训练的;
- 输入除了noisy latent以外还concat上了subject个mask,如图;
- 此外,针对multi object,和fastcomposer一样加入了新的损失项来监督cross attn map,但是个人感觉fastcomposer得损失更加合理一点;
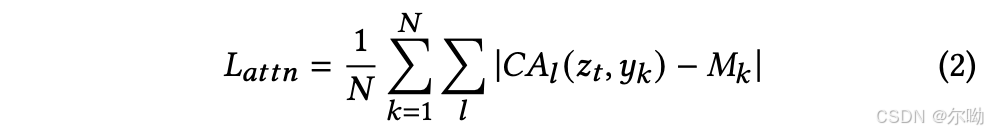

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)