探索丹摩智算:Llama3.1模型的部署与使用
在人工智能的浪潮中,大型语言模型(LLM)正逐渐成为推动技术进步的关键力量。丹摩智算(DAMODEL)作为这一领域的先行者,最近发布了其最新的开源模型——Llama3.1。本文将带你深入了解Llama3.1模型的部署与使用,让你领略丹摩智算的强大之处。Llama3.1的发布,不仅是Meta在大模型领域的一次飞跃,也为整个AI社区带来了新的机遇。通过丹摩智算平台,用户可以轻松部署和使用这一强大的模型
文章目录
📑前言
在人工智能的浪潮中,大型语言模型(LLM)正逐渐成为推动技术进步的关键力量。丹摩智算(DAMODEL)作为这一领域的先行者,最近发布了其最新的开源模型——Llama3.1。本文将带你深入了解Llama3.1模型的部署与使用,让你领略丹摩智算的强大之处。
一、Llama3.1:Meta的开源巨作
2024年7月23日,Meta宣布推出Llama3.1,这是迄今为止最强大的开源模型之一。Llama3.1 405B版本支持上下文长度为128K Tokens,基于15万亿个Tokens、超1.6万个H100 GPU进行训练,标志着Meta在大模型领域的重大突破。
Llama3.1的优势
- 强大的处理能力:Llama3.1 405B能够处理高达128K Tokens的上下文长度,这意味着它能够理解和生成更加复杂和连贯的文本。
- 开源可定制:Llama3.1的开源特性使得用户可以根据自己的需求进行本地部署和微调,打造专属于自己的大模型。
- 多种版本选择:除了405B版本,Llama3.1还提供了70B和8B版本,以适应不同的资源和性能需求。
二、部署Llama3.1:8B版本的实践指南
2.1 环境准备
在部署Llama3.1之前,你需要准备以下环境:
- 操作系统:Ubuntu 22.04
- Python版本:Python 3.12
- CUDA版本:CUDA 12.1
- PyTorch版本:PyTorch 2.4.0
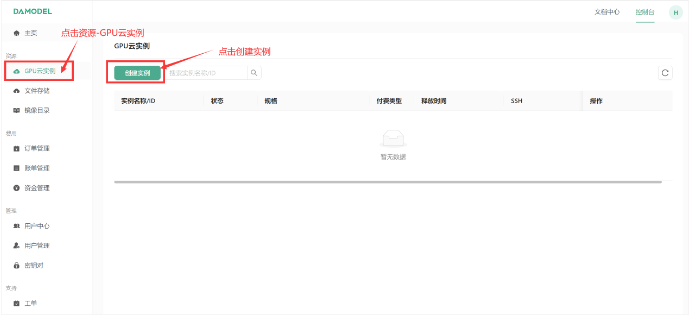
2.2 创建GPU云实例
- 登录丹摩智算平台,进入控制台-GPU云实例,点击创建实例。
- 选择付费类型(按量付费或包月套餐),GPU数量和型号(推荐NVIDIA GeForce RTX 4090,至少16GB显存)。
- 配置数据硬盘大小(至少50GB,建议60GB)。
- 创建并保存密钥对,用于安全登录。
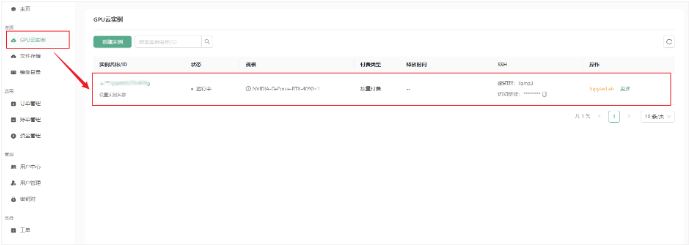
2.3 登录实例
- JupyterLab:通过平台提供的JupyterLab入口直接登录实例。
- SSH登录:使用SSH工具(如Xshell、MobaXterm等)和保存的密钥登录。
2.4 部署流程
- 创建环境:使用
conda创建新的Python环境。 - 安装依赖:安装
langchain、streamlit、transformers和accelerate。 - 下载模型:通过内网高速下载
Llama-3.1-8B-Instruct模型并解压缩。 - 启动服务:编写
llamaBot.py脚本,使用streamlit启动服务。
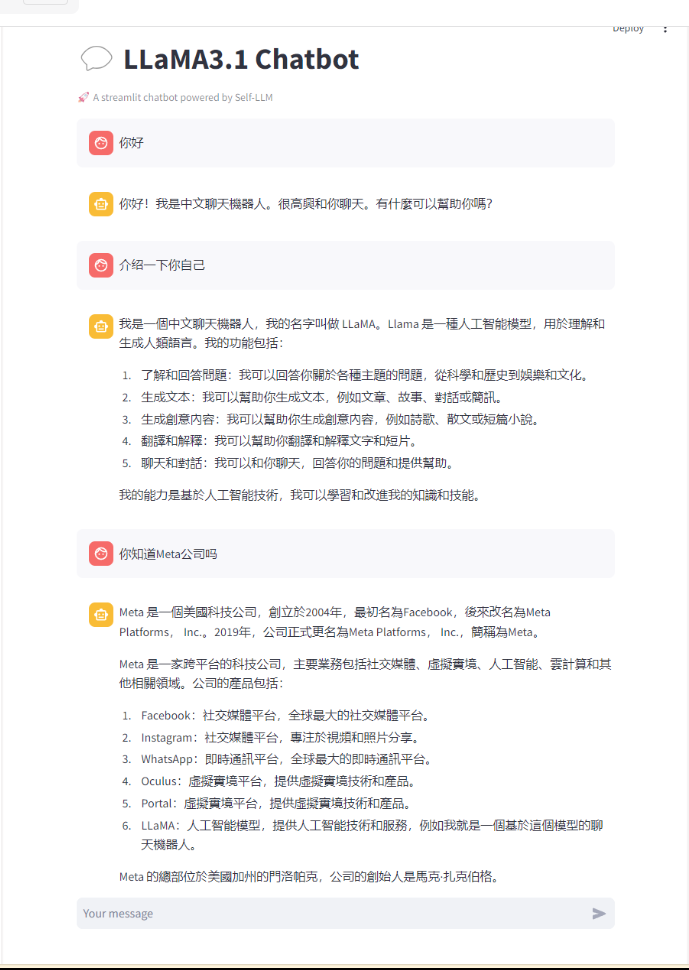
三、使用Llama3.1:构建交互式Chatbot
通过streamlit,你可以轻松地启动一个基于Llama3.1的交互式Chatbot。以下是一些关键步骤:
- 创建Chatbot脚本:编写
llamaBot.py,定义模型路径,加载模型和tokenizer。 - 启动服务:在终端中运行
streamlit run llamaBot.py,将服务端口映射到公网。 - 交互体验:通过访问链接,打开LLaMA3.1 Chatbot交互界面,开始与Chatbot对话。
四、总结
Llama3.1的发布,不仅是Meta在大模型领域的一次飞跃,也为整个AI社区带来了新的机遇。通过丹摩智算平台,用户可以轻松部署和使用这一强大的模型,探索自然语言处理的无限可能。无论是学术研究还是商业应用,Llama3.1都将为你的项目带来前所未有的智能体验。

尧米是由西云算力与CSDN联合运营的AI算力和模型开源社区品牌,为基于DaModel智算平台的AI应用企业和泛AI开发者提供技术交流与成果转化平台。
更多推荐
 9
9 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)