pandas库基础操作
https://i-blog.csdnimg.cn/direct/cb9976308aa64b50a09393987aadbdb6.png
目录
1.安装pandas库
打开命令提示符,输入如下指令进行安装
pip install pandas2.导入pandas库
导入pandas库,并简写为pd
import pandas as pd3.主要数据结构
Series
类似一维数组,由一组数据和相应的索引组成
-
每个元素有一个唯一的索引(称为
index),默认从0开始编号。
import pandas as pd
# 创建Series
s= pd.Series(['a','b','c','d','e'])
print(s)-
可以为每个元素重新设定唯一的索引(
index)
import pandas as pd
# 创建Series
s= pd.Series(['a','b','c','d','e'], index=[1,2,3,4,5])
print(s)DataFrame
类似二维表格,由多组数据和相应的索引值组成(由多个Series组成)
- Series越多,列越多
- Series中的数据越多,行越多
import pandas as pd
# 创建DataFrame
df = pd.DataFrame({
'name':['a','b','c'],
'age':[18,35,45],
'gender':['male','female','male']
})
print(s)
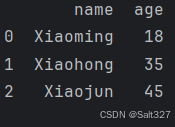
4.创建一个DataFrame
import pandas as pd
df = pd.DataFrame({
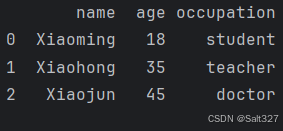
'name':['Xiaoming','Xiaohong','Xiaojun'],
'age':[18,35,45],
'occupation':['student','teacher','doctor']
})
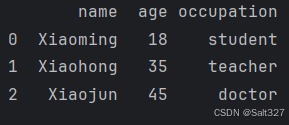
print (df)该代码创建了一个Pandas库的DataFrame数据结构并赋值给df,
包含三个人的信息:姓名(name)、年龄(age)和职业(occupation)。然后打印这个DataFrame。具体数据如下:
Xiaoming,18岁,学生
Xiaohong,35岁,教师
Xiaojun,45岁,医生
打印结果:
5.查看数据
# 查看前5行数据
print(df.head())
# 查看后5行数据
print(df.tail())
# 显示 DataFrame 的列名、数据类型、非空值数量等基本信息
print(df.info())
# 显示 DataFrame 中数值列的描述性统计信息,如计数、平均值、标准差、最小值、最大值等。
print(df.describe())6.选择数据
可以通过索引值或切片来选择数据
import pandas as pd
df = pd.DataFrame({
'name':['Xiaoming','Xiaohong','Xiaojun'],
'age':[18,35,45],
'occupation':['student','teacher','doctor']
})
# 选择单列数据
print(df['name'])
# 选择多列数据
print(df[['age','occupation']])
# 选择单行数据
print(df.iloc[0])
# 选择多行数据
print(df.iloc[1:3])
# 根据条件选择数据
print(df[df['age'] > 30])7.添加与删除与更改数据
添加数据
添加列
import pandas as pd
df = pd.DataFrame({
'name':['Xiaoming','Xiaohong','Xiaojun'],
'age':[18,35,45],
'occupation':['student','teacher','doctor']
})
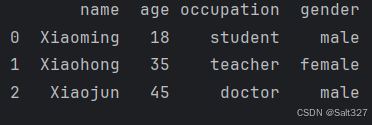
# 添加一列
df['gender']=['male','female','male']
print(df)此代码为设置DataFrame df的'gender'列赋值为一个固定列表,由于DataFrame df并没有'gender'列,所以添加这个列
打印结果:
原来的结果(意为4讲的创建一个DataFrame的结果,提供用于方便对比)
添加行
import pandas as pd
df = pd.DataFrame({
'name':['Xiaoming','Xiaohong','Xiaojun'],
'age':[18,35,45],
'occupation':['student','teacher','doctor']
})
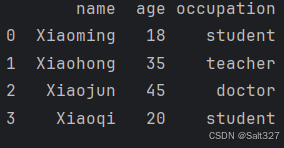
# 添加一行
df.loc[3] = ['Xiaoqi', 20, 'student']
print(df)功能:.loc 主要用于基于行标签或列标签进行选择和赋值。
此代码为设置DataFrame df索引值为3的行赋值为一个固定列表,由于DataFrame df并没有索引值为3的行, 所以添加这个行
打印结果:
原来的结果(意为4讲的创建一个DataFrame的结果,提供用于方便对比)
删除数据
删除列
import pandas as pd
df = pd.DataFrame({
'name':['Xiaoming','Xiaohong','Xiaojun'],
'age':[18,35,45],
'occupation':['student','teacher','doctor']
})
# 删除一列
df.drop('occupation',axis=1,inplace=True)
print(df)此代码将删除DataFrame df中的列'gender'。
drop方法 用于删除指定的行或列。
'gender' 指定要删除的列名。
axis=1 表示操作在列上进行。
inplace=True 表示修改原始数据框,不返回新数据框。
节省内存,避免创建额外的数据副本。
原始 DataFrame 被永久改变。
打印结果:
原来的结果(意为4讲的创建一个DataFrame的结果,提供用于方便对比)
删除行
import pandas as pd
df = pd.DataFrame({
'name':['Xiaoming','Xiaohong','Xiaojun'],
'age':[18,35,45],
'occupation':['student','teacher','doctor']
})
# 删除一行
df.drop(1,axis=0,inplace=True)
print(df)此代码将删除DataFrame df中索引值为1的行
1 指定要删除的对象。
axis=0 表示操作在行上进行。(默认为删除行,因此这里可以不输入)
inplace=True 表示修改原始数据框,不返回新数据框。
节省内存,避免创建额外的数据副本。
原始 DataFrame 被永久改变。
打印结果:
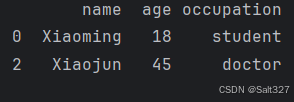
原来的结果(意为4讲的创建一个DataFrame的结果,提供用于方便对比)
修改数据
修改列
import pandas as pd
df = pd.DataFrame({
'name':['Xiaoming','Xiaohong','Xiaojun'],
'age':[18,35,45],
'occupation':['student','teacher','doctor']
})
# 修改一列
df['age'] = [20,37,47]
print(df)此代码为设置DataFrame df的'age'列赋值为一个固定列表,由于DataFrame df已经有'age'列,所以修改这个列
打印结果:
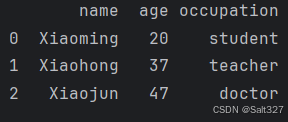
原来的结果(意为4讲的创建一个DataFrame的结果,提供用于方便对比)
修改行
import pandas as pd
df = pd.DataFrame({
'name':['Xiaoming','Xiaohong','Xiaojun'],
'age':[18,35,45],
'occupation':['student','teacher','doctor']
})
# 修改一行
df.loc[2] = ['Xiaoqi', 20, 'student']
print(df)功能:loc 主要用于基于行标签或列标签进行选择和赋值。
此代码为设置DataFrame df索引值为2的行赋值为一个固定列表,由于DataFrame df已经有索引值为2的行, 所以修改添加这个行
打印结果:
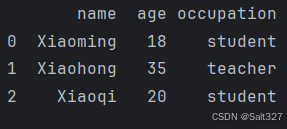
原来的结果(意为4讲的创建一个DataFrame的结果,提供用于方便对比)
8.数据清洗
数据清洗(Data cleaning)是指对数据进行重新审查和校验的过程,目的是为了删除重复信息、纠正存在的错误,并提供数据的一致性。数据清洗是数据预处理的第一步,也是确保后续数据分析结果准确性的关键步骤。
代码用到:
# 处理重复数据
df.drop_duplicates(inplace=True)
# 删除缺失值
df=df.dropna()
# 填充缺失值
df=df.fillna(0)
# 计算平均值
df['mean']=df[['math','chinese','english']].mean(axis=1)
# 计算中位数
df['median']=df[['math','chinese','english']].median(axis=1)处理重复数据
import pandas as pd
df = pd.DataFrame({
'name':['Xiaoming','Xiaohong','Xiaojun','Xiaoming','Xiaohong'],
'age':[18,35,45,18,35],
'occupation':['student','teacher','doctor','student','teacher']
})
# 处理重复数据
df.drop_duplicates(inplace=True)
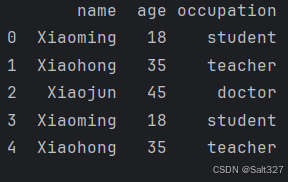
print(df)该函数用于删除Pandas DataFrame中的重复行。
drop_duplicates 方法会保留重复数据中的第一条记录,默认情况下删除其余重复项。
inplace=True 表示修改原始数据框,不返回新数据框。
节省内存,避免创建额外的数据副本。
原始 DataFrame 被永久改变。
打印结果:
处理前的结果(用于对比)
处理缺失数据
删除缺失值
import pandas as pd
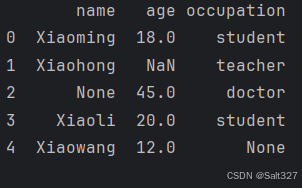
df = pd.DataFrame({
'name':['Xiaoming','Xiaohong',None,'Xiaoli','Xiaowang'],
'age':[18,None,45,20,12],
'occupation':['student','teacher','doctor','student',None]
})
# 删除缺失值
df=df.dropna()
print(df)dropna()函数用于删除含有缺失值的行和列‘
打印结果: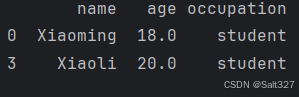
处理前的结果(用于对比)
填充缺失值
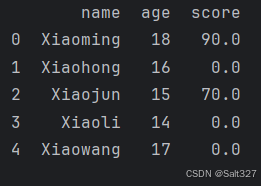
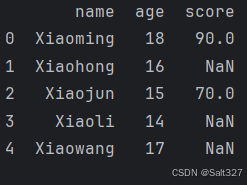
import pandas as pd
df = pd.DataFrame({
"name":['Xiaoming','Xiaohong','Xiaojun','Xiaoli','Xiaowang'],
"age":[18,16,15,14,17],
"score":[90,None,70,None,None],
})
# 填充缺失值
df=df.fillna(0)
print(df)
fillna(value)函数可以填充缺失值为value
打印结果:
处理前的结果(用于对比)
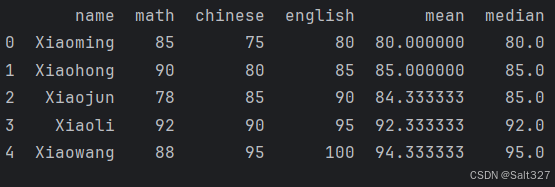
计算平均值和中位数
import pandas as pd
df = pd.DataFrame({
'name':['Xiaoming','Xiaohong','Xiaojun','Xiaoli','Xiaowang'],
'math': [85, 90, 78, 92, 88],
'chinese': [75, 80, 85, 90, 95],
'english': [80, 85, 90, 95, 100],
'mean':[None,None,None,None,None],
'median':[None,None,None,None,None]
})
# 计算平均值
df['mean']=df[['math','chinese','english']].mean(axis=1)
# 计算中位数
df['median']=df[['math','chinese','english']].median(axis=1)
print(df)Pandas 的 mean()函数用于计算 DataFrame 或 Series 中数值的平均值。
Pandas 的 median()函数用于计算 DataFrame 或 Series 中数值的中位数。
axis:指定沿着哪个轴计算。默认为 0,表示按列计算;如果设为 1,则按行计算。
打印结果
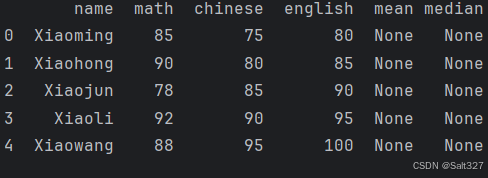
处理前的结果(用于对比)
修改数据类型
假设我们有一个表格,其中包含姓名(name)、年龄(age),但年龄列的数据是字符串(str)类型,我们需要把他修改成整数(int)类型:
import pandas as pd
df=pd.DataFrame({
'name':['a','b','c'],
'age':['10','20','30']
})
df['age']=df['age'].astype(int)
print(df)astype() 是 Pandas 中的一个非常实用的方法,用于将 DataFrame 或 Series 中的数据类型转换为指定的数据类型。
如果年龄(age)列有缺失值,这时候就不能直接使用astype(int),需要使用:
df['age']=df['age'].astype(int,errors='ignore')errors='ignore'可以把无法转换的数据进行保留
纠正错误数据
假设我们有一个包含学生成绩数据的 DataFrame,其中可能存在一些错误数据。我将逐步展示如何检测和纠正这些错误数据。
import pandas as pd
df = pd.DataFrame({
'name':['Xiaoming','Xiaohong','Xiaojun','Xiaoli','Xiaowang'],
'math': [85, 90, -3, 92, 88],
'chinese': [75, 105, 170, 90, -5],
'english': [80, 85, 90, 95, 102],
'mean':[None,None,None,None,None],
'median':[None,None,None,None,None]
})
#检测并纠正异常值(各科目分数里有哪些分数>100 or <0)
for i in ['math','chinese','english']:
df.loc[df[i]>100,i]=100
df.loc[df[i]<0,i]=0
print(df)利用for循环对DataFrame df的语数英分数进行遍历,这里利用了loc方法来选取数据。loc方法可以同时选择行和列,并且允许进行更复杂的条件筛选。
在给定的代码中:
df.loc[df[i]>100, i] = 100 这一行的意思是对于列 i(这里 i 是 'math', 'chinese', 'english' 中的一个),找出所有值大于100的行,并将这些行中列 i 的值设置为100。
同样的,df.loc[df[i]<0, i] = 0 这一行是找出所有值小于0的行,并将这些行中列 i 的值设置为0。
打印结果:
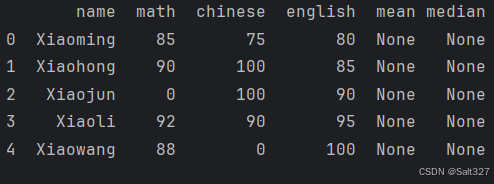
处理前的结果(用于对比)
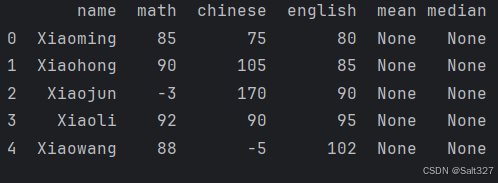
重新排序索引值
import pandas as pd
df=pd.DataFrame({
'name':['a','b','c'],
'age':[11,12,14],
'score':[71,62,55]
},index=[4,5,6])
# 重置索引并忽略原来的索引值
df=df.reset_index(drop=True)
print(df)使用 reset_index 方法并设置 drop=True 来忽略原来的索引值。
打印结果:
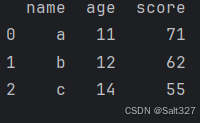
处理前的结果(用于对比)

9.数据分析
数据分组
import pandas as pd
# 假设df是包含学生分数和班级信息的数据框
df=pd.DataFrame({
'class': ['A','B','A','A','A','B','A','B','B','B'],
'score': [90, 85, 75, 65, 95, 85, 70, 90, 80, 85]
})
# 使用groupby()按'class'列分组,然后计算'score'的平均值,结果赋值给新的变量grouped
grouped = df.groupby('class')['score'].mean()
print(grouped)
groupby()函数 是 Pandas 中用于对数据进行分组的强大工具。它允许你按照一个或多个列的值将数据分成不同的组,并对每个组执行聚合操作。
聚合操作(Aggregation Operations)是指在数据处理和数据分析领域中,将数据集中的数据根据一个或多个字段进行分组,并对每个分组执行一个或多个统计函数的过程
grouped = df.groupby('class'):按照 class 列的值将数据分成不同的组。例如,所有 class 为 'A' 的行组成一组,所有 class 为 'B' 的行组成另一组。
['score'].mean():对每个组中的 score 列计算平均值。
打印结果:
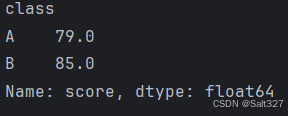
Name: score:
含义: 表示该 Series 对象的名称是 score。
dtype: float64:
含义: 表示该 Series 对象的数据类型是 float64,即浮点型数字。’
数据提取
import pandas as pd
df=pd.DataFrame({
'email': ['john.doe@example.com',
'jane.smith@company.org',
'mike.brown@university.edu']
})
# 使用正则表达式提取用户名和域名
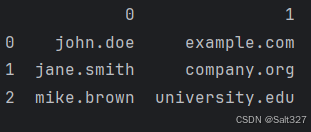
result = df['email'].str.extract(r'(\w+)\.(\w+)@(\w+)\.(\w+)')
print(result)str.extract() 是一个非常强大的工具,可以用于从字符串中提取特定的子串。 (r'(\w+)\.(\w+)@(\w+)\.(\w+)')详细讲解: 第一个捕获组:(\w+) (\w+): 捕获一个或多个字母数字字符(包括下划线)。这里的括号 () 形成一个捕获组。 例如,在 john.doe@example.com 中,这会捕获 john。 第二个捕获组:\. \.: 匹配一个点字符 .。由于点字符在正则表达式中有特殊含义,需要用反斜杠 \ 转义。 例如,在 john.doe@example.com 中,这会匹配 .。 第三个捕获组:(\w+) (\w+): 捕获一个或多个字母数字字符(包括下划线)。这里的括号 () 形成一个捕获组。 例如,在 john.doe@example.com 中,这会捕获 doe。 第四个捕获组:@ @: 匹配一个 @ 字符。 例如,在 john.doe@example.com 中,这会匹配 @。 第五个捕获组:(\w+) (\w+): 捕获一个或多个字母数字字符(包括下划线)。这里的括号 () 形成一个捕获组。 例如,在 john.doe@example.com 中,这会捕获 example。 第六个捕获组:\. \.: 匹配一个点字符 .。由于点字符在正则表达式中有特殊含义,需要用反斜杠 \ 转义。 例如,在 john.doe@example.com 中,这会匹配 .。 第七个捕获组:(\w+) (\w+): 捕获一个或多个字母数字字符(包括下划线)。这里的括号 () 形成一个捕获组。 例如,在 john.doe@example.com 中,这会捕获 com。
(r'(\w+)\.(\w+)@(\w+)\.(\w+)')
r 前缀表示的是 原始字符串(raw string)。使用 r 前缀可以避免在字符串中转义特殊字符
为什么使用 r 前缀
在 Python 中,字符串默认会对某些字符进行转义处理。例如,\n 表示换行符,\t 表示制表符。然而,在正则表达式中,这些转义字符本身具有特殊的含义。如果不使用 r 前缀,就需要多次转义这些特殊字符,这会使正则表达式变得复杂且难以阅读。
打印结果:
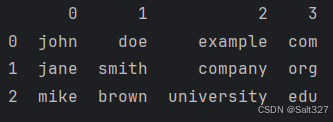
如果觉得复杂只想提取完整的用户名和域名的话,可以这样
# 使用正则表达式提取完整的用户名和域名
result = df['email'].str.extract(r'(\w+\.\w+)@(\w+\.\w+)')
print(result)
数据合并
import pandas as pd
df=pd.DataFrame({
'name':['a','b','c'],
'age':[11,12,14],
'score':[71,62,55]
})
df2=pd.DataFrame({
'name':['d','e','f'],
'age':[13,16,12],
'score':[44,85,76]
})
# 合并
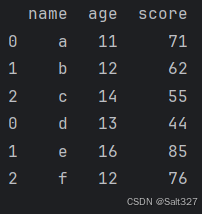
All_df=pd.concat([df,df2])
print(All_df)可以使用concat()函数将数据合并,这里将df与df2合并在一起并赋值给All_df。
打印结果:
可以在concat()函数里加上ignore_index=True把索引值重新排序
# 合并
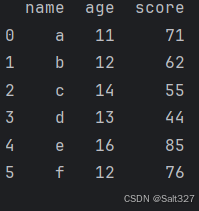
All_df=pd.concat([df,df2],ignore_index=True)
print(All_df)
打印结果:
总结
对于Pandas库我是一位初学者,把学习过程记录在这篇文章上,希望这篇文章对你有帮助!如有不足的地方可以在评论区补充

欢迎加入西安开发者社区!我们致力于为西安地区的开发者提供学习、合作和成长的机会。参与我们的活动,与专家分享最新技术趋势,解决挑战,探索创新。加入我们,共同打造技术社区!
更多推荐
 72
72 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)