
CVPR 2024 | SVGDreamer: 北航&港大发布全新文本引导的矢量图形可微渲染方法
关注公众号,发现CV技术之美本篇分享 CVPR 2024 论文SVGDreamer: Text Guided SVG Generation with Diffusion Model,由北航&港大发布全新文本引导的矢量图形可微渲染方法,SVGDreamer。0论文地址:https://arxiv.org/abs/2312.16476项目地址:https://ximinng.github.io
关注公众号,发现CV技术之美
本篇分享 CVPR 2024 论文SVGDreamer: Text Guided SVG Generation with Diffusion Model,由北航&港大发布全新文本引导的矢量图形可微渲染方法,SVGDreamer。

论文地址:https://arxiv.org/abs/2312.16476
项目地址:https://ximinng.github.io/SVGDreamer-project/
代码地址:https://github.com/ximinng/SVGDreamer
论文背景
可缩放矢量图形(Scalable Vector Graphics,SVG)是用于描述二维图型和图型应用程序的基本元素;与传统的像素图形不同,SVG 使用数学描述来定义图形,因此可以在任何大小下无损地缩放而不失真。这使得 SVG 成为网站设计领域的理想选择,特别是在需要适应不同分辨率和设备的情况下。但是创作者手工设计SVG是高成本并具有挑战的。
最近,随着CLIP和生成式模型的快速发展,文本引导的矢量图合成(Text-to-SVG)在抽象像素风格[1,2]和矢量手绘草图[3,4]等领域都取得了不错的进展。通过可微分渲染器[5]驱动矢量路径基元自动合成对应的矢量图形,成为一个热门的研究方向。相比于人类设计师,Text-to-SVG方法可以快速并大量的创建矢量内容,用于扩充矢量资产。
然而,现有的Text-to-SVG方法还存在两个限制:1.生成的矢量图缺少编辑性;2. 难以生成高质量和多样性的结果。为了解决这些限制,作者提出了一种新的文本引导矢量图形合成方法:SVGDreamer。
实现思路
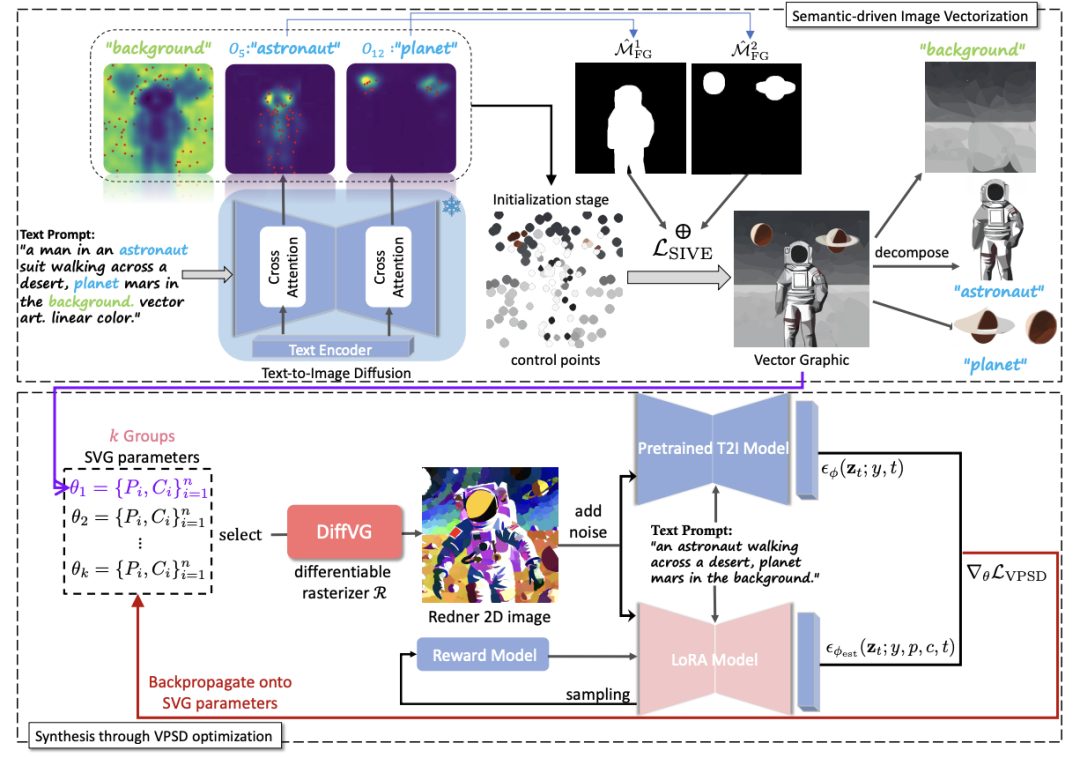
SVGDreamer由两部分构成:语义驱动的图像矢量化(Semantic-driven Image Vectorization,SIVE)和基于矢量例子的分数蒸馏(Vectorized Particle-based Score Distillation,VPSD)构成。其中SIVE根据文本提示矢量化图像,VPSD则通过分数蒸馏从预训练的扩散模型中合成高质量、多样化并具有审美吸引力的矢量图。
语义驱动的图像矢量化(SIVE)
SIVE根据文本提示合成语义层次解耦的矢量图。它包括两个部分:1. 矢量基元初始化(Primitive Initialization);2. 基于语义级优化(Semantic-aware Optimization)。
如图1上半部分所示,文本提示中不同的词语对应不同的注意力图,这使得作者可以借助注意力图初始化矢量图控制点(control points)。具体来说,作者对注意力图进行归一化,将它视为一个概率分布图,根据概率加权采样画布上的点作为贝塞尔曲线的控制点。
然后,作者将初始化阶段获得的注意力图转换为可重复使用的掩码,大于等于阈值的部分设为 1,代表目标区域,小于阈值为0。作者利用掩码定义SIVE损失函数从而精确地优化不同的对象。
SIVE确保了控制点保持在各自的语义对象区域中,从而实现不同对象的解构,最终结果如图1右上部分所示。
基于矢量粒子的分数蒸馏(VPSD)
之前基于扩散模型的SVG生成工作[2,4],已经探索了使用分数蒸馏采样(SDS)优化SVG参数的方式,但这种优化方式往往会带来颜色过饱和、优化得到的SVG过于平滑的结果。受变分分数蒸馏采样的启发,作者提出了基于向量化粒子的分数蒸馏采样(Vectorized Particle-based Score Distillation,VPSD)损失来解决以上问题。相对于SDS,这种采样方式将SVG建模为控制点和色彩的一个分布,VPSD通过优化这个分布来实现对SVG参数的优化:
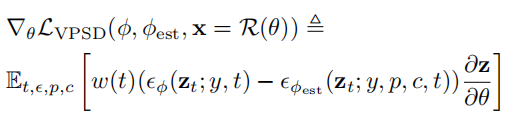
由于直接优化另一个模型的成本过大,所以引入Lora来减少被优化的参数量:
最后,为了改善合成矢量图的美观评价,作者引入了一种奖励反馈学习方法(ReFL),将采样得到的样本输入到使用预训练的Reward模型中,共同进行对LoRA参数的优化:
最后完整的目标函数即为上述三个函数的加权组合:
通过反向传播更新SVG路径参数,经过循环迭代完成优化,得到最终结果。
实验结果
定性结果
下图展示了SVGDreamer生成的6种风格类型的SVG结果,包括肖像图风格(Iconography)、像素风格(Pixel-Art)、水墨(Ink and Wash)、多边形(Low-poly)、手绘(Sketch)和线条绘画(Painting)风格等。不同颜色的后缀表示不同的SVG风格类型,这些风格类型也并不需要在Prompt中给出,只需要通过控制矢量图基元实现。

SVGDreamer能够根据文本提示合成语义层次解耦的矢量图,这使得其可以被用于创建大量矢量数据资产,同时这些矢量元素可以被自由地组合,如下图所示:

应用展示
除此之外,作者展示了SVGDreamer的应用:制作矢量海报。通过将制定字形转为矢量表示,并且与生成的矢量图结合,即可得到美观的矢量海报。与基于扩散模型的生成式位图海报相比,矢量海报的文字与内容部分同样具有良好的编辑性,并且不会产生错误的文字:

结论
在这项工作中,作者介绍了SVGDreamer,一个用于文本引导矢量图形合成的创新模型。SVGDreamer结合了两个关键的技术设计: 语义驱动的图像矢量化(SIVE)和基于矢量粒子的分数蒸馏(VPSD),这使得模型能够生成具有高可编辑性、卓越的视觉质量和显著的多样性的矢量图形。
未来展望
由于SVGDreamer能够生成具有可编辑性的复杂矢量图形,因此,SVGDreamer有望显著推进文本到SVG模型在设计领域的应用。它已经被证实可以用来创建矢量图形资产库,设计师可以根据不同的需求,很容易地将库中的元素重新排列组合,用于创建独特的矢量海报或Logo,以及其他矢量艺术形式。
矢量图可微渲染库PyTorch-SVGRender介绍

项目地址:https://ximinng.github.io/PyTorch-SVGRender-project/
代码地址:https://github.com/ximinng/PyTorch-SVGRender
文档地址:https://pytorch-svgrender.readthedocs.io/en/latest/index.html
Pytorch-SVGRender 是作者团队在2023.12发布的一个用于 SVG 生成的可微分渲染方法的Python库,使研究人员和开发者们可以通过一个统一的、简化的接口来访问不同的SVG生成技术。
Pytorch-SVGRender包含两大功能:位图到SVG的渲染(Img-to-SVG),以及文本到SVG(Text-to-SVG)的渲染。并且整合了与这些功能有关的研究成果,例如DiffVG、LIVE、CLIPasso、CLIPDraw、VectorFusion、Word-As-Image、DiffSketcher和SVGDreamer等。
Pytorch-SVGRender的设计理念是基于模块化和可扩展性的原则,让用户能够无缝集成最新的SVG创作技术。通过提供一套清晰的、统一的API,该库允许开发者轻松地调用底层绘图算法,无需深入了解其底层原理。此外,库中的每一种方法的相关参数都经过精心优化,以确保生成的SVG文件在性能和质量上都能满足高标准的要求。
最后,Pytorch-SVGRender 还提供了丰富的文档和示例代码,帮助用户快速入门上手。作者希望这个库可以提高 SVG 研究人员和开发者的工作效率,为未来 SVG 相关技术的创新与实践提供帮助。
参考文献
[1] Kevin Frans, Lisa Soros, and Olaf Witkowski. CLIPDraw: Exploring text-to-drawing synthesis through language-image encoders. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems(NIPS), 2022.
[2] Ajay Jain, Amber Xie, and Pieter Abbeel. Vectorfusion: Text-to-svg by abstracting pixel-based diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), 2023.
[3] Yael Vinker, Ehsan Pajouheshgar, Jessica Y Bo, Roman Christian Bachmann, Amit Haim Bermano, Daniel Cohen-Or, Amir Zamir, and Ariel Shamir. Clipasso: Semantically-aware object sketching. ACM Transactions on Graphics(TOG), 41(4):1–11, 2022.
[4] Xing X, Wang C, Zhou H, et al. Diffsketcher: Text guided vector sketch synthesis through latent diffusion models[J]. Advances in Neural Information Processing Systems(NIPS), 2023.
[5] Tzu-Mao Li, Michal Lukac, Gharbi Michael and Jonathan Ragan-Kelley. Differentiable vector graphics rasterization for editing and learning. ACM Transactions on Graphics (TOG), 39(6):193:1–193:15, 2020.
[6] Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. In The Eleventh International Conference on Learning Representations(ICLR), 2023.

END
欢迎加入「文生图」交流群👇备注:生成


瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)