

Yolov8-seg:制作并训练自己的数据集+提取并重建mask
本篇博文是作者对可见光图像进行图像分割,制作并且训练自己数据的数据集时的操作过程。本文是建立在yolov8-seg模型的基础上进行训练的,没有对模型进行更改。在训练完网络后,实现了对分割结果掩码mask的可视化重建。
目录
前言
本篇博文是作者对可见光图像进行图像分割,制作并且训练自己数据的数据集时的操作过程。本文是建立在yolov8-seg模型的基础上进行训练的,没有对模型进行更改。在训练完网络后,实现了对分割结果掩码mask的可视化重建。
一.制作分割数据集
1.1 基于SAM模型的半自动标注
标注工具的名称为ISAT with segment anything 。对于这个半自动标注工具,个人建议是用于一些比较明显的,分割图像的细节没有什么要求或者是分割的物体比较容易人肉眼看出的(因为太过于细节的分割,这个工具还做不到,当然如果不觉得麻烦的话,标注结果可以在后期手动调整)
对于工具的安装,可以直接参考这个博文:标注工具ISAT with segment anything介绍
安装成功后打开的界面如下:
选择好你需要进行标注的图像文件夹后,需要在SAM选项处选择一个模型的权重,如下图所示

注意:都选择好之后,可能会出现无法使用的情况,这个时候需要检查一下图片的格式。因为这个标注工具的输入图片要求是通道数是3,图片的信息格式在软件右上角,就比如我的图片通道数为4

下面提供一个将图片通道数由4转成3的脚本(注意要换成自己的路径):
from PIL import Image
import os
path = "Original path of picture" # 原始路径
save_path = "Picture save path" # 保存路径
all_images = os.listdir(path)
for image in all_images:
image_path = os.path.join(path, image)
img = Image.open(image_path) # 打开图片
print(img.format, img.size, img.mode) # 打印出原图格式
img = img.convert("RGB") # 四通道转化为rgb三通道
image_name = os.path.basename(image_path)
save_image_path = os.path.join(save_path, image_name)
img.save(save_image_path)之后开始标注,在软件的文件->设置中可以设置自己标注的类别及其颜色,标注成功并保存后会生成一个json文件


我们在进行yolov8-seg数据集建立的时候,需要将json文件转换成特定的txt文件(模型需要),但是这个软件所产生的json文件在后面json转txt的脚本中不能使用,因此要先进一步的进行格式转化,转化成脚本认可的labelme下的json文件:软件中的工具选项下 To LabelMe 可以转化

1.2 手动标注
半自动标注对于细节不要求的建议使用,对于比较抠细节的建议使用 labelme 手动标注软件。软件的下载、安装和使用可以参考此博文:Labelme的安装和使用 , 软件界面界面如下:

1.3 json文件处理与数据集的划分
标注完成后,要对得到的json文件进行处理,因为yolov8-seg要求的的标注文件是txt格式,因此要先从json转成txt,以下是脚本代码。其中需要注意的是 :json_dir,txt_dir是json文件和txt文件存放位置,A,B,C等是你标注过程中的所有的类别名称。
import json
import os
import argparse
from tqdm import tqdm
def convert_label_json(json_dir, save_dir, classes):
json_paths = os.listdir(json_dir)
classes = classes.split(',')
for json_path in tqdm(json_paths):
# for json_path in json_paths:
path = os.path.join(json_dir, json_path)
with open(path,'r') as load_f:
json_dict = json.load(load_f)
h, w = json_dict['imageHeight'], json_dict['imageWidth']
# save txt path
txt_path = os.path.join(save_dir, json_path.replace('json', 'txt'))
txt_file = open(txt_path,'w')
for shape_dict in json_dict['shapes']:
label = shape_dict['label']
label_index = classes.index(label)
points = shape_dict['points']
points_nor_list = []
for point in points:
points_nor_list.append(point[0]/ w)
points_nor_list.append(point[1]/ h)
points_nor_list = list(map(lambda x: str(x), points_nor_list))
points_nor_str = ' '.join(points_nor_list)
label_str = str(label_index) + ' ' + points_nor_str + '\n'
txt_file.writelines(label_str)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='json convert to txt params')
parser.add_argument('--json-dir', type=str, default='json_dir', help='json path dir')
parser.add_argument('--save-dir', type=str, default='txt_dir', help='txt save dir')
parser.add_argument('--classes', type=str, default='A,B,C.....', help='classes')
args = parser.parse_args()
json_dir = args.json_dir
save_dir = args.save_dir
classes = args.classes
convert_label_json(json_dir, save_dir, classes)数据准备完成后就是对数据集的划分:训练集,验证集和测试集。首先要先将你标注的图片、对应的txt文件分别存放在一个文件夹中,再新建一个文件夹split用于存放即将被划分的数据,之后再运行一下脚本,数据集的制作就到此完成
import shutil
import random
import os
import argparse
# 检查文件夹是否存在
def mkdir(path):
if not os.path.exists(path):
os.makedirs(path)
def main(image_dir, txt_dir, save_dir):
# 创建文件夹
mkdir(save_dir)
images_dir = os.path.join(save_dir, 'images')
labels_dir = os.path.join(save_dir, 'labels')
img_train_path = os.path.join(images_dir, 'train')
img_test_path = os.path.join(images_dir, 'test')
img_val_path = os.path.join(images_dir, 'val')
label_train_path = os.path.join(labels_dir, 'train')
label_test_path = os.path.join(labels_dir, 'test')
label_val_path = os.path.join(labels_dir, 'val')
mkdir(images_dir);
mkdir(labels_dir);
mkdir(img_train_path);
mkdir(img_test_path);
mkdir(img_val_path);
mkdir(label_train_path);
mkdir(label_test_path);
mkdir(label_val_path);
# 数据集划分比例,训练集75%,验证集15%,测试集15%,按需修改
train_percent = 0.70
val_percent = 0.15
test_percent = 0.15
total_txt = os.listdir(txt_dir)
num_txt = len(total_txt)
list_all_txt = range(num_txt) # 范围 range(0, num)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# 在全部数据集中取出train
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = os.path.join(image_dir, name + '.png')
srcLabel = os.path.join(txt_dir, name + '.txt')
if i in train:
dst_train_Image = os.path.join(img_train_path, name + '.png')
dst_train_Label = os.path.join(label_train_path, name + '.txt')
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
elif i in val:
dst_val_Image = os.path.join(img_val_path, name + '.png')
dst_val_Label = os.path.join(label_val_path, name + '.txt')
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
else:
dst_test_Image = os.path.join(img_test_path, name + '.png')
dst_test_Label = os.path.join(label_test_path, name + '.txt')
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='split datasets to train,val,test params')
parser.add_argument('--image-dir', type=str, default='image_dir', help='image path dir')
parser.add_argument('--txt-dir', type=str, default='txt_dir', help='txt path dir')
parser.add_argument('--save-dir', default='split_dir', type=str, help='save dir')
args = parser.parse_args()
image_dir = args.image_dir
txt_dir = args.txt_dir
save_dir = args.save_dir
完成后的数据集如图所示

二.训练网络
2.1 准备工作
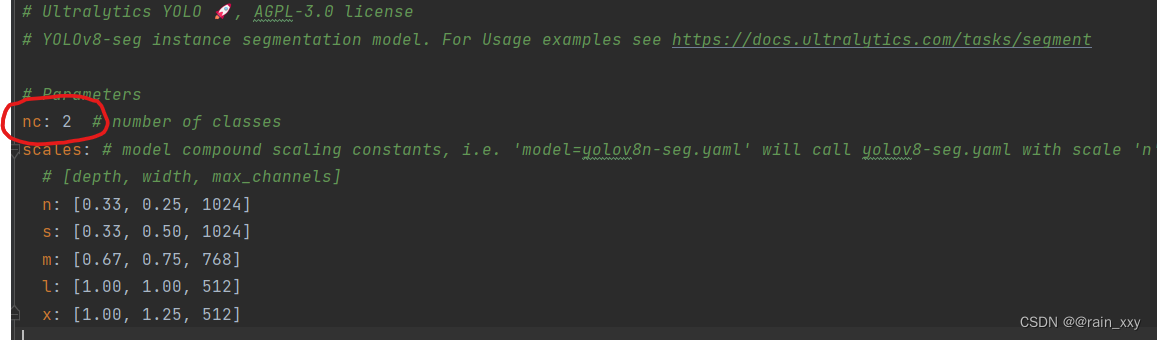
首先要先搭建好网络以及网络所需要的环境,下载好网络的预训练权重,并且验证网络是否能成功运行,这里就不多做介绍,可以参考这篇博文:适合小白的超详细yolov8环境配置+实例运行教程(Windows+conda+pycharm)![]() https://blog.csdn.net/weixin_45662399/article/details/134499605环境完成后,要对yolov8-seg.yaml文件进行修改,将nc:的值改成你的类别个数
https://blog.csdn.net/weixin_45662399/article/details/134499605环境完成后,要对yolov8-seg.yaml文件进行修改,将nc:的值改成你的类别个数

在项目的任一文件夹下新建一个myseg.yaml(可自定义)文件,用来存放训练集、验证集和测试集的划分文件,myseg.yaml内容(具体的路径还需要根据自己的实际路径填写)如下:
# Train/val/test sets as
# 1) dir: path/to/imgs,
# 2) file: path/to/imgs.txt
# 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: split_dir # dataset root dir
train:/images/train # train images (relative to 'path') 128 images
val: /images/val # val images (relative to 'path') 128 images
test: /images/test # test images (optional)
# Classes
names:
0: A
1: B2.2 训练网络
直接建立训练train脚本:
from ultralytics import YOLO
model =YOLO("X:/ultralytics-main/ultralytics/cfg/models/v8/yolov8-seg.yaml")
model =YOLO("X:/ultralytics-main/yolov8n-seg.pt")
model.train(data='myseg.yaml dir', epochs=100)运行成功的界面如下所示:

结束后会生成以下的指标以及表格:具体的含义可以参考这两篇博文:

超详细YOLOv8实例分割全程概述:环境、训练、验证与预测详解
yolov8模型训练结果分析以及如何评估yolov8模型训练的效果
2.3 结果预测
直接建立预测predict脚本:
from ultralytics import YOLO
import numpy as np
from PIL import Image
model = YOLO('X:/ultralytics-main/runs/segment/train9/weights/best.pt')
results = model('image_dir')
# Show the results
for r in results:
im_array = r.plot() # plot a BGR numpy array of predictions
im = Image.fromarray(im_array[..., ::-1]) # RGB PIL image
im.show() # show image
im.save('results.jpg') # save image三.提取并重建mask
我的目标是想要得到每张图片分割后的mask图像,但是yolov8-seg本身的预测结果results输出中的mask的属性中没有每个mask对应的像素点的坐标,但是他可以输出每个分割图mask的边缘点信息,因此我根据mask的边缘点信息,以及对应的类别属性信息对mask图进行了重建
输出结果中mask的边缘点以及对应检测框的类别如下:

在只知mask边缘点的前提下使用射线法(ray casting)算法计算出每个分割预测出的区域所在的像素点坐标,然后进行mask重建,(黑色对应背景,绿色对应类别属性为A,蓝色对应类别属性为B,颜色可以自己根据自己的需要调整),以下是对于一张图片的mask重建脚本:
from ultralytics import YOLO
import numpy as np
from PIL import Image
model = YOLO('X:/ultralytics-main/runs/segment/train9/weights/best.pt')
results = model('image_dir')
image = Image.open("image_dir")
for result in results:
boxes = result.boxes # 输出的检测框
masks = result.masks # 输出的掩码信息
def is_point_inside_polygon(x, y, polygon):
"""
检查点是否在多边形内部
参考:https://wrf.ecse.rpi.edu/Research/Short_Notes/pnpoly.html
"""
n = len(polygon)
inside = False
j = n - 1
for i in range(n):
if ((polygon[i][1] > y) != (polygon[j][1] > y)) and \
(x < polygon[i][0] + (polygon[j][0] - polygon[i][0]) * (y - polygon[i][1]) / (polygon[j][1] - polygon[i][1])):
inside = not inside
j = i
return inside
def find_polygon_pixels(masks_xy, boxes_cls): # 所有掩码像素点及其对应类别属性的列表
# 初始化存储所有像素点和类别属性的列表
all_pixels_with_cls = []
# 遍历每个多边形
for i, polygon in enumerate(masks_xy):
cls = boxes_cls[i] # 当前多边形的类别属性
# 将浮点数坐标点转换为整数类型
polygon = [(int(point[0]), int(point[1])) for point in polygon]
# 找出当前多边形的边界框
min_x = min(point[0] for point in polygon)
max_x = max(point[0] for point in polygon)
min_y = min(point[1] for point in polygon)
max_y = max(point[1] for point in polygon)
# 在边界框内遍历所有像素点
for x in range(min_x, max_x + 1):
for y in range(min_y, max_y + 1):
# 检查像素点是否在多边形内部
if is_point_inside_polygon(x, y, polygon):
# 将像素点坐标和类别属性组合成元组,添加到列表中
all_pixels_with_cls.append(((x, y), cls))
return all_pixels_with_cls
def reconstruct_image(image_size, pixels_with_cls):
# 创建一个和图片原始大小相同的黑色图像
reconstructed_image = np.zeros((image_size[1], image_size[0], 3), dtype=np.uint8)
# 将属性为 0 的像素点设为绿色,属性为 1 的像素点设为蓝色 ,其余的像素点默认为背景设为黑色
for pixel, cls in pixels_with_cls:
if cls == 0:
reconstructed_image[pixel[1], pixel[0]] = [0, 255, 0] # 绿色
elif cls == 1:
reconstructed_image[pixel[1], pixel[0]] = [0, 0, 255] # 蓝色
else:
reconstructed_image[pixel[1], pixel[0]] = [0, 0, 0] # 黑色
return reconstructed_image
masks_xy = masks.xy # 每个掩码的边缘点坐标
boxes_cls = boxes.cls # 每个多边形的类别属性
# 调用函数找出每个多边形内部的点和相应的类别属性
all_pixels_with_cls = find_polygon_pixels(masks_xy, boxes_cls)
image_size = image.size
# print("所有像素点和相应的类别属性:", all_pixels_with_cls) # 在终端显示所有掩码对应的坐标以及对应的属性元组
reconstructed_image = reconstruct_image(image_size, all_pixels_with_cls) # 重建图像
Image.fromarray(reconstructed_image).save("mask_image.png") # 保存图像
# Show the results
for r in results:
im_array = r.plot() # plot a BGR numpy array of predictions
im = Image.fromarray(im_array[..., ::-1]) # RGB PIL image
im.show() # show image
im.save('results.jpg') # save image将model的权重YOLO('X:/ultralytics-main/runs/segment/train9/weights/best.pt')换成你自己训练好的权重;image_dir是待处理图像的路径。最后得到的mask_image即为重建的mask图像,results为经过模型的分割预测图。以下是图像的原图以及重建的mask

tips:批量处理的脚本,在评论区看到很多读者想要,这里就放在文章里啦,创作不易,多多支持。脚本如下:(其中文件路径需要自己修改)
import os
from ultralytics import YOLO
from PIL import Image
import numpy as np
def is_point_inside_polygon(x, y, polygon):
n = len(polygon)
inside = False
j = n - 1
for i in range(n):
if ((polygon[i][1] > y) != (polygon[j][1] > y)) and \
(x < polygon[i][0] + (polygon[j][0] - polygon[i][0]) * (y - polygon[i][1]) / (polygon[j][1] - polygon[i][1])):
inside = not inside
j = i
return inside
def find_polygon_pixels(masks_xy, boxes_cls): # 所有掩码像素点及其对应类别属性的列表
# 初始化存储所有像素点和类别属性的列表
all_pixels_with_cls = []
# 遍历每个多边形
for i, polygon in enumerate(masks_xy):
cls = boxes_cls[i] # 当前多边形的类别属性
# 将浮点数坐标点转换为整数类型
polygon = [(int(point[0]), int(point[1])) for point in polygon]
# 找出当前多边形的边界框
min_x = min(point[0] for point in polygon)
max_x = max(point[0] for point in polygon)
min_y = min(point[1] for point in polygon)
max_y = max(point[1] for point in polygon)
# 在边界框内遍历所有像素点
for x in range(min_x, max_x + 1):
for y in range(min_y, max_y + 1):
# 检查像素点是否在多边形内部
if is_point_inside_polygon(x, y, polygon):
# 将像素点坐标和类别属性组合成元组,添加到列表中
all_pixels_with_cls.append(((x, y), cls))
return all_pixels_with_cls
def reconstruct_image(image_size, pixels_with_cls):
# 创建一个和图片原始大小相同的黑色图像
reconstructed_image = np.zeros((image_size[1], image_size[0], 3), dtype=np.uint8)
# 将属性为 0 的像素点设为绿色,属性为 1 的像素点设为蓝色 ,其余的像素点默认为背景设为黑色
for pixel, cls in pixels_with_cls:
if cls == 0:
reconstructed_image[pixel[1], pixel[0]] = [0, 255, 0] # 绿色
elif cls == 1:
reconstructed_image[pixel[1], pixel[0]] = [0, 0, 255] # 蓝色
else:
reconstructed_image[pixel[1], pixel[0]] = [0, 0, 0] # 黑色
return reconstructed_image
# 获取RGB图像的路径
image_dir = "__________"
# 遍历每个图片文件
for image_filename in os.listdir(image_dir):
if image_filename.endswith('.png'):
image_path = os.path.join(image_dir, image_filename)
# 执行模型预测
model = YOLO('X:/ultralytics-main/runs/segment/train9/weights/best.pt')
results = model(image_path)
image = Image.open(image_path)
# 提取掩码和检测框信息
for result in results:
boxes = result.boxes # 输出的检测框
masks = result.masks # 输出的掩码信息
masks_xy = masks.xy # 每个掩码的边缘点坐标
boxes_cls = boxes.cls # 每个多边形的类别属性
# 调用函数找出每个mask内部的点和相应的类别属性
all_pixels_with_cls = find_polygon_pixels(masks_xy, boxes_cls)
# 对每一张图像的分割掩码进行重建并保存在特定的文件夹中
image_size = image.size
reconstructed_image = reconstruct_image(image_size, all_pixels_with_cls) # 重建图像
reconstructed_image_filename = f"{image_filename.split('_rgb.png')[0]}_mask.png" # 重建图像文件名
reconstructed_image_path = os.path.join('_______', reconstructed_image_filename) # 重建图像保存路径
Image.fromarray(reconstructed_image).save(reconstructed_image_path) # 保存图像四.结尾
对本文参考的博文表以尊重。如果这篇文章对你有帮助或者是有问题,欢迎各位大佬指正评论,感谢点赞。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 59
59 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)