
GaussDB(DWS)运维利刃:TopSQL工具解析
本文深入讲解GaussDB(DWS) TopSQL的基本原理、能力及典型应用场景。
本文分享自华为云社区《GaussDB(DWS)运维利刃:TopSQL工具解析》,作者:胡辣汤。
在生产环境中,难免会面临查询语句出现异常中断、阻塞时间长等突发问题,如果没能及时记录信息,事后就需要投入更多的人力及时间成本进行问题的定位和解决,有时还无法定位到错误出现的地方。在本期《GaussDB(DWS)运维利刃:TopSQL工具解析》的主题直播中,华为云数仓GaussDB(DWS)调优专家刘坤鹏老师,深入讲解GaussDB(DWS) TopSQL的基本原理、能力及典型应用场景。
一、 什么是TopSQL?
TopSQL是GaussDB(DWS)数据库中内置的一款功能十分强大的性能分析工具。在生产环境中,难免会出现一些突发情况,导致查询语句出现异常中断、阻塞时间长等情况,如果当时没能记录下来,那么事后就要投入更多的人力以及时间成本去对错误进行定位和解决,有时还往往定位不到错误出现的地方。为了解决这样的窘迫的情况,GaussDB(DWS)开发了TopSQL功能,对运行中的语句记录(实时TopSQL),对运行完成的语句进行记录(历史TopSQL)。
TopSQL作为GaussDB(DWS)的性能诊断工具,记录GaussDB(DWS)中各个作业、算子级别的资源使用数据、耗时数据,包括下盘信息、内存、网络、耗时、自诊断告警、基础信息等作业执行的数据。
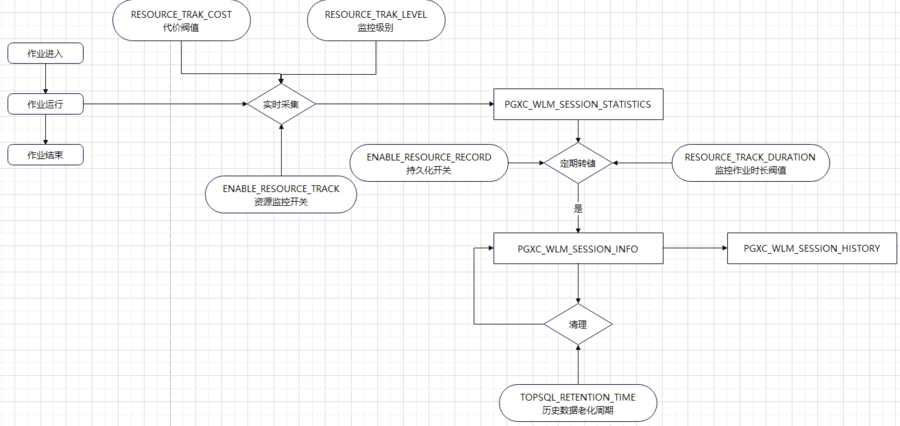
TopSQL工作原理
二、TopSQL系统表和参数介绍
以GaussDB(DWS) 8.1.3版本为例,推荐TopSQL相关的一些参数。
| 参数 | 解释及用法 |
| enable_resource_track:on | 资源监控总开关,开启后TopSQL才能发挥作用。 |
| enable_resource_record:on | 控制实时TopSQL是否做历史TopSQL转储,813版本推荐打开,方便对历史问题做定位分析。 |
| resource_track_cost:0 | 执行代价超过预值,才会被记录,建议保持默认值0。 |
| resource_track_duration:1 | 实时TopSQL是否转储到历史TopSQL,默认值为60秒,建议设置为1。 |
| resource_track_level:query/perf | 语句级TopSQL信息记录到历史TopSQL的系统表中。 |
| TopSQL_retention_time:30 | TopSQL老化时间为30秒,建议保持默认值。 |
| enable_track_record_subsql:按需开启 | 控制子查询是否记录到TopSQL系统表中。 |
TopSQL常用系统表:
• 实时TopSQL:pgxc_wlm_session_statistics
• 历史TopSQL:pgxc_wlm_session_info
TopSQL系统表关键字段:
| 字段 | 字段说明 |
| username | 用户名 |
| block_time | 排队时间,辅助定位CCN场景 |
| Start_time | 语句执行的开始时间 |
| duration | 语句执行时长,重点关注 |
| Estimate_memory | 估算内存,复制定位ccn排队或内存问题 |
| Max_peak_memory | 实际最大使用内存,定位内存不足场景 |
| Max_spill_size | 下盘大小 |
| Unique_sql_id | 归一化ID,标志同一语句/同一语句不同入参 |
| Cpu_skew_percent | CPU倾斜情况 |
| warning | 自诊断信息 |
三、TopSQL的3个典型应用场景
1、 实时TopSQL
问题场景:某集群业务反馈某业务SQL偶发执行慢,该集群resource_track_duration设置较大,历史TopSQL中没有记录计划详情,需要定位原因。
处理过程:
1) 系统管理员根据queryid查看等待视图,等待视图部分结果如下:
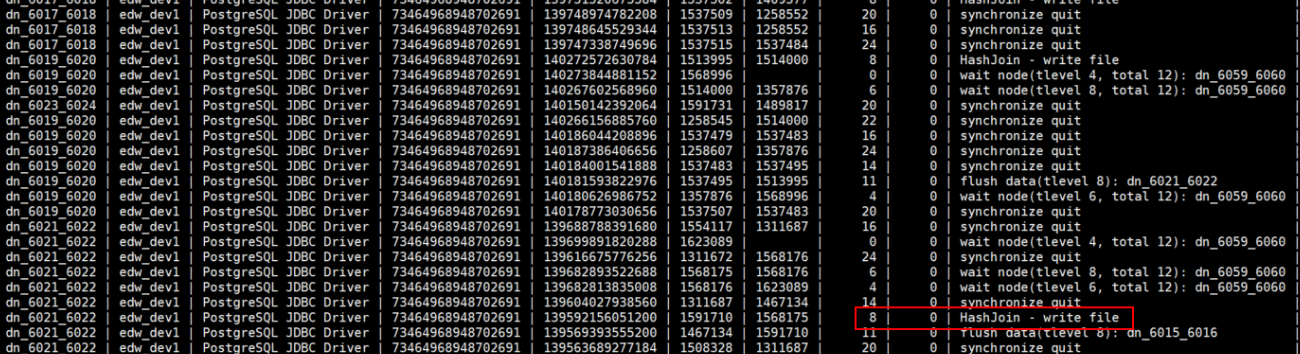
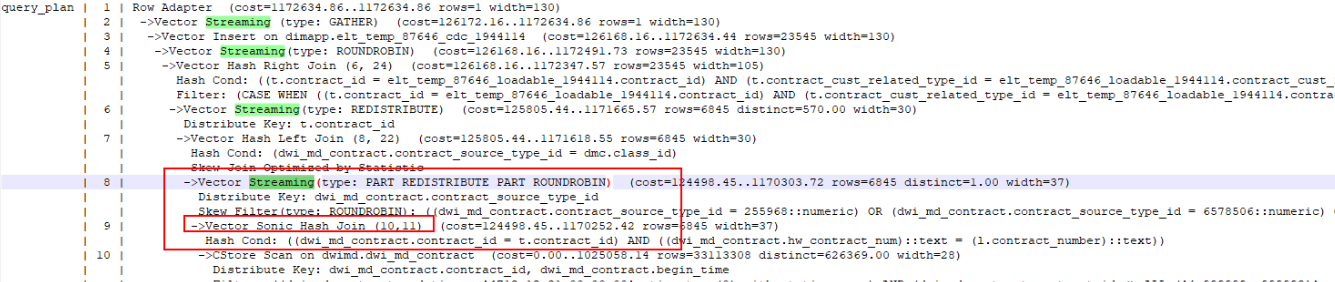
2)管理员执行explain verbose,得到的执行计划如下

3) 第8层非Stream算子,说明该计划不是正在执行语句的计划,使用实时TopSQL查看实际计划:
2、 历史TopSQL
问题场景:某客户由于内存规格较小,经常出现内存不可用的报错,云上运维人员通过autopilot定期巡检时发现该集群内存周期性冲高,且存在单实例内存使用倾斜的问题,需定位原因。
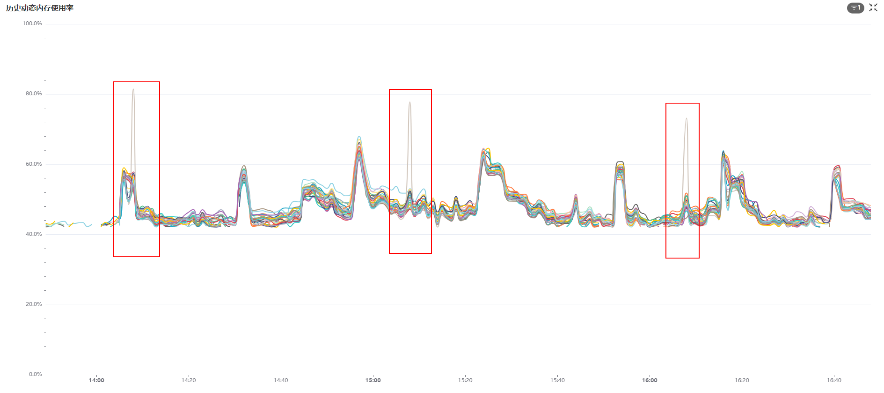
处理过程:
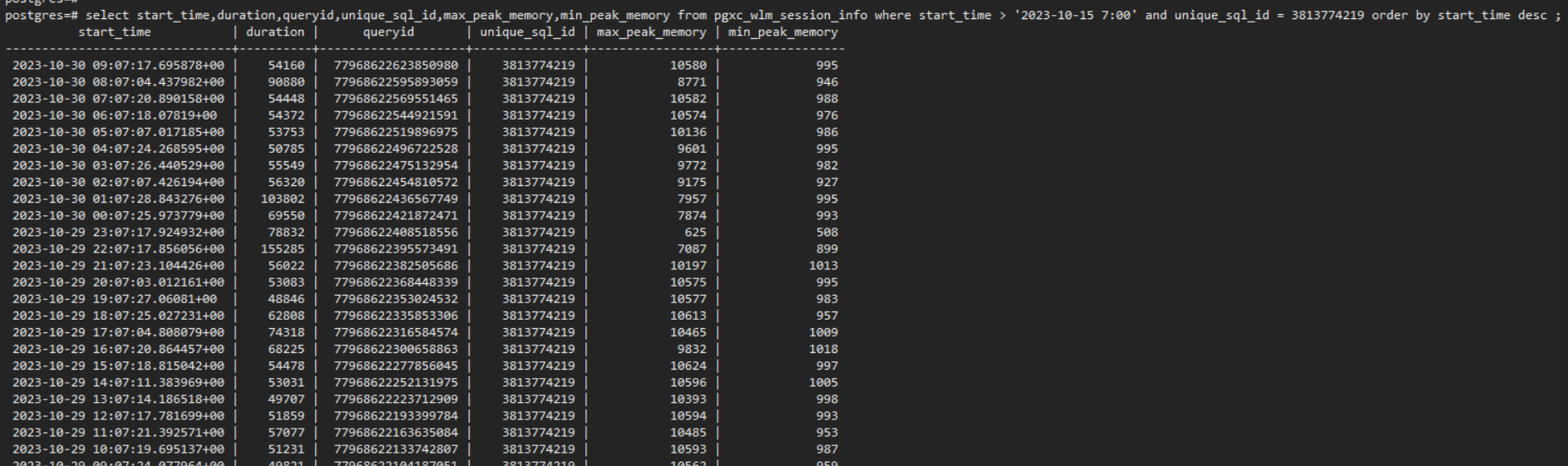
1) 通过历史TopSQL找到内存占用高的语句
Select * from pgxc_wlm_session_info where start_time > '2023-10-30 10:05' and start_time < '2023-10-30 10:10' order by max_peak_memory desc limit 100;复制2) 根据unique_sql_id确认作业的历史执行情况
3、 存储过程子语句
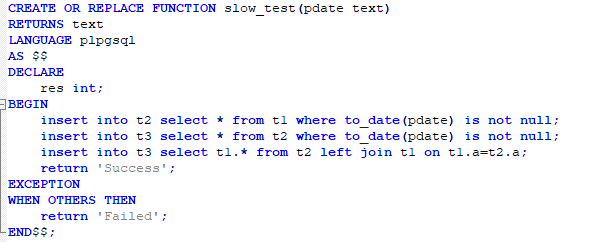
问题场景:某客户在业务中封装了大量的存储过程和匿名块脚本,用于业务系统的调度,随着业务数据越来越多,存储过程和匿名块脚本执行越来越慢,需要对其中的脚本进行优化。示例脚本如下:
处理过程:
1) 查看历史TopSQL,存储过程和匿名块的query_plan字段显示NoPlan;
2) 设置enable_track_record_subsql: on,该参数打开后可以记录存储过程和匿名块中的自语句和执行计划;
3) 重新执行慢的存储过程,根据query_id查看历史TopSQL中各个自语句的执行计划。
四、如何通过TopSQL进行信息统计
1、 常用TopSQL进行业务信息统计
1) 识别stream数量多的语句:select *,(length(query_plan) - length(replace(query_plan, 'Streaming', ''))) / length('Streaming') as stream_count FROM pgxc_wlm_session_info ORDER BY stream_count DESC limit 100;
2) 识别内存占用高的语句:select * from pgxc_wlm_session_info where start_time > 'xxxx-xx-xx' and start_time < 'xxxx-xx-xx' order by max_peak_memory desc limit 100;
3) 识别需要优化的语句:select * from pgxc_wlm_session_info where start_time > 'xxxx-xx-xx' and start_time < 'xxxx-xx-xx' and warning is not null order by duration desc limit 100。
2、 TopSQL使用注意事项
1) 查询时使用start_time做条件,避免全表查询;
2) 查询时使用limit对结果集大小限制,防止结果集过大导致客户端OOM。
本期分享到此结束,更多关于GaussDB(DWS)产品技术解析、数仓产品新特性的介绍,请关注GaussDB(DWS)开发者平台,GaussDB(DWS)开发者平台为开发者们提供最新、最全的信息咨询,包括精品技术文章、最佳实践、直播集锦、热门活动、海量案例、智能机器人。让您学+练+玩一站式体验GaussDB(DWS)。
GaussDB(DWS)开发者平台链接:DWS-华为云

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 18
18 0
0- 0



 已为社区贡献5445条内容
已为社区贡献5445条内容

所有评论(0)