K8S故障处理指南:网络问题排查思路
K8S故障处理指南:网络问题排查思路
1. 前言
对于私有化环境,客户的网络架构,使用的云平台存在着各种差异,K8S网络可能会出现各种问题,此文着重讲解遇到此种问题的排查方法和思路,不会涉及相关网络底层技术描述.
环境说明
由于我们的k8s网络组件默认使用了flannel,这里描述的集群网络,均为flannel。但如果你使用了其他CNI组件,依然可以参考此文章的排查思路.
2. 异常场景
如何判断k8s集群网络出现异常?
-
当集群出现pods大量异常,日志显示dns解析失败,或者节点间网络连接失败等,即可判断是集群网络异常
我们可以通过如下几种方式进行排查。当任何一种方式的结果非预期内,则确认k8s集群网络出现异常
2. 排查步骤
-
测试节点互ping
可以按照如下步骤操作
查询node名称,podcidr,address并打印
[root@localhost ~]# kubectl get nodes -o jsonpath='{range .items[*]}[name:{.metadata.name} , podCIDR:{.spec.podCIDR} , ipaddr:{.status.addresses[0].address}]{"\n"} {end}'
[name:10.28.87.59 , podCIDR:172.27.1.0/24 , ipaddr:10.28.87.59]
[name:10.28.87.60 , podCIDR:172.27.0.0/24 , ipaddr:10.28.87.60]
[name:10.28.87.61 , podCIDR:172.27.2.0/24 , ipaddr:10.28.87.61]
[name:10.28.87.62 , podCIDR:172.27.4.0/24 , ipaddr:10.28.87.62]
[name:10.28.87.63 , podCIDR:172.27.3.0/24 , ipaddr:10.28.87.63]
[name:10.28.87.64 , podCIDR:172.27.5.0/24 , ipaddr:10.28.87.64]
此命令需要在所有节点下执行,可在部署机器上使用ansible调用使用上述命令获取到的CIDR地址,进行ping操作,seq根据节点数量进行设置
从上面结果可以看到共6个K8S节点,子网分别是172.27.0-172.27.5子网段。
使用下边shell脚本测试pod子网,通的话打印up
[root@localhost ~]# for ip in $(seq 0 5);do ping -c2 -W1 -q 172.27.$ip.1 2>1 &>/dev/null && echo "172.27.$ip.1 up" || echo "172.27.$ip.1 down";done
172.27.0.1 up
172.27.1.1 up
172.27.2.1 up
172.27.3.1 up
172.27.4.1 up
172.27.5.1 up非预期结果: 出现某个节点固定的ping异常,即认为对应节点间vxlan通信异常,检查对应节点的网络即可
-
tcp,udp查询
需要在所有节点上执行,可在一台机器上使用ansible调用
ping操作属于三层操作,由于某些环境会禁ping,因此我们可以使用如下命令进行确认
使用http请求访问coredns metrics接口,状态码为200时正常,状态码000代表网络异常不通
[root@CentOS76 ~]# kubectl get pods -n kube-system -o wide | grep coredns | awk '{print $6}' | xargs -i curl --connect-timeout 2 -o /dev/null -s -w "%{http_code}\n" http://{}:9153/metrics
200
200
200
200
200
200使用dns查询kubernetes.default地址。有返回则代表正常
[root@localhost ~]# kubectl get pods -n kube-system -o wide | grep coredns | awk '{print $6}' | xargs -l nslookup -type=a kubernetes.default.svc.cluster.local
Server: 172.27.2.23
Address: 172.27.2.23#53
Name: kubernetes.default.svc.cluster.local
Address: 172.26.0.1
---------
Server: 172.27.1.131
Address: 172.27.1.131#53
Name: kubernetes.default.svc.cluster.local
Address: 172.26.0.1
---------
Server: 172.27.3.57
Address: 172.27.3.57#53
Name: kubernetes.default.svc.cluster.local
Address: 172.26.0.1
---------
Server: 172.27.0.29
Address: 172.27.0.29#53
Name: kubernetes.default.svc.cluster.local
Address: 172.26.0.1
---------
Server: 172.27.5.53
Address: 172.27.5.53#53
Name: kubernetes.default.svc.cluster.local
Address: 172.26.0.1
---------
Server: 172.27.4.65
Address: 172.27.4.65#53
Name: kubernetes.default.svc.cluster.local
Address: 172.26.0.1
---------非预期结果:dns查询报connection timed out; no servers could be reached, curl报000,都代表网络可能存在异常
3. 异常场景
当我们通过上述方式,确认集群节点存在异常时,可以使用如下思路进行逐一排查
-
ip_forward内核被重置为0
-
flannel通信异常
-
启用了firewalld防火墙
-
启用了安全软件
-
ip_forward
名词解释:ip_forward代表了路由转发特性,为0时不开启,设置为1时代表启用。由于vxlan的跨三层特性, 集群节点需要转发目标主机非自己的数据包.
影响范围: 如果此值设为0,会导致跨节点通信异常.
出现原因: 在部署时,会向/etc/sysctl.conf里边添加net.ipv4.ip_forward=1,来保证永久生效。
问题定位: 出现在集群重启后,发现pods异常,网络不通. 通过tcmdump抓包发现flannel流量正常。
处理方式
查询本机内核参数, 在所有节点上执行,可在部署机上使用ansible调用,为读操作,可放心执行
[root@localhost ~]# sysctl -n net.ipv4.ip_forward
0打印sysctl加载链,会变更相关内核参数,生产环境禁用使用(如果出现ip_forward为0则可使用)
[root@localhost ~]# sysctl --system
* Applying /usr/lib/sysctl.d/00-system.conf ...
......
* Applying /usr/lib/sysctl.d/10-default-yama-scope.conf ...
.....
* Applying /usr/lib/sysctl.d/50-default.conf ...
.......
* Applying /etc/sysctl.d/99-sysctl.conf ...
.......
* Applying /etc/sysctl.conf ...
.......找到具体是哪个文件修改了ip_forward为0,则修改此文件,并重载内核参数。无异常禁止使用
[root@localhost ~]# sysctl -p-
flannel通信异常
名词说明: vxlan是vlan的拓展协议,为overlay网络,可以穿透三层网络对二层进行扩展,即大二层网络。flannel我们默认使用了vxlan做为封装协议,端口为8472
影响范围: 跨节点通信异常
问题定位: 对udp 8472端口抓发,发现只有出站流量,未有入站流量,即可认定为flannel vxlan通信异常
出现原因: 安全组封禁,vxlan端口冲突,网卡异常等。由于flannel异常的原因多种多样,此次仅针对常见情况进行描述。建议具体问题具体分析。
问题处理: 使用nc等相关命令进行测试,如果抓包仍未发现入站流量,且其他udp端口正常,则可使用修改port的方式
添加Port字段,将通信端口修改为8475
[root@localhost ~]# kubectl edit cm -n kube-system kube-flannel-cfg
net-conf.json: |
{
"Network": "172.27.0.0/16",
"Backend": {
"Type": "vxlan",
"Port": 8475
}
}修改后需要重启相关daemonset pods
[root@localhost ~]# kubectl get pods -n kube-system | grep flannel | xargs kubectl delete pods -n kube-system
修改port不生效,可使用host-gw 如果内网各节点二层互通,可使用host-gw模式,此模式兼容性好,网络效率高.
[root@localhost ~]# kubectl edit cm -n kube-system kube-flannel-cfg
net-conf.json: |
{
"Network": "172.27.0.0/16",
"Backend": {
"Type": "host-gw",
}如果无法定位问题,可以通过抓包的方式来判断
例如:当时coredns网络不通时,通过curl测试
curl -I 10.187.1.24:9153/metrics然后再开一个窗口抓包
tcpdump -nn -i flannel.1 host 10.187.1.24 and port 9153 -vv防火墙排查
名词解释: 此处的防火墙指Linux的软件防火墙,在Cenots上叫firewalld, 在UOS下叫UFW. 默认的软件防火墙会导致相关数据库被拦截
影响范围: 特定服务访问异常,集群节点互通异常
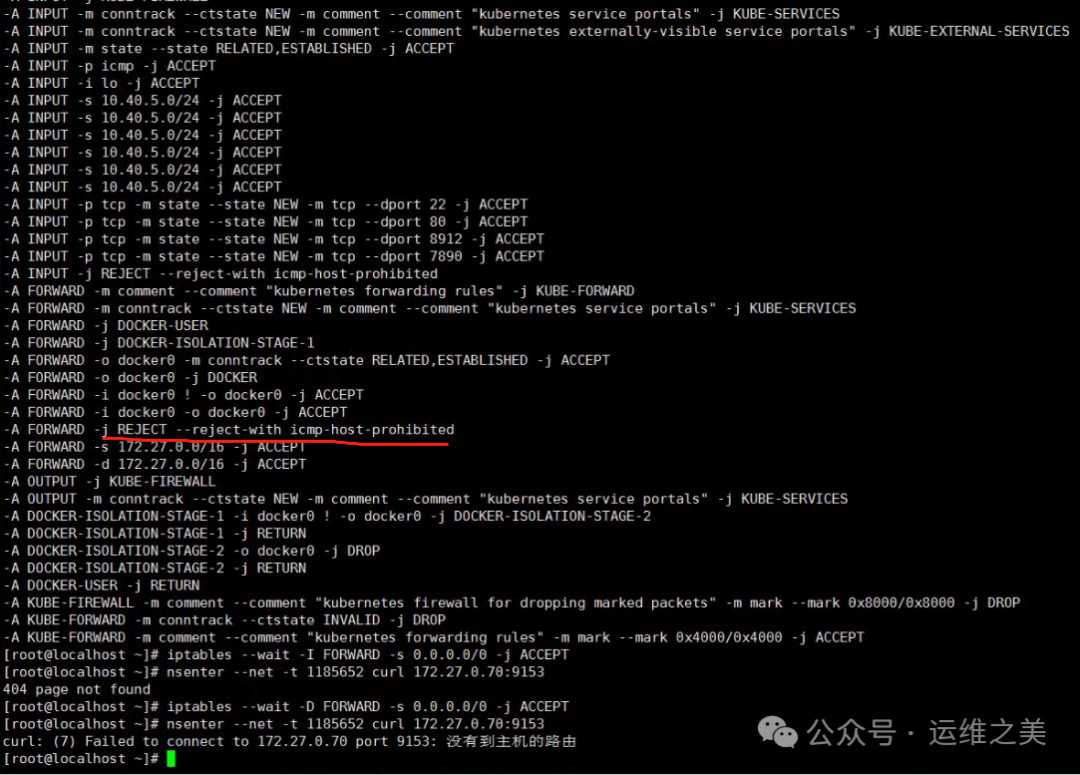
问题定位: 对iptables表链进行分析,发现有非预期的规则出现,则代表存在其他防火墙规则
出现原因: 客户安装安全软件,或者是非预期的软件行为导致
问题排查:
一般看到ufw, public, zone这种,都可能是默认的系统防火墙
[root@localhost ~]# iptables-save | egrep "^:" | egrep -v "KUBE|CNI|DOCKER"
:FORWARD_IN_ZONES - [0:0]
:FORWARD_IN_ZONES_SOURCE - [0:0]
:FORWARD_OUT_ZONES - [0:0]
:FORWARD_OUT_ZONES_SOURCE - [0:0]发现后手动关闭,以centos7为例
[root@localhost ~]# systemctl stop firewalldiptables FORWARD转发链添加了REJECT规则,该规则在ACCEPT之上

删除规则后正常
iptables -D FORWARD -j REJECT --reject-with icmp-host-prohibited常见安全软件排查
qaxsafed # 奇安信,
sangfor_watchdog # 深信服安全软件
YDservice #qcloud安全软件,影响pod和docker桥接网络
Symantec #赛门铁克的安全软件
start360su_safed #360安全软件
gov_defence_service
gov_defence_guard # ps aux | grep defence
wsssr_defence_daemon # 奇安信服务器安全加固软件
wsssr_defence_service
wsssr_defence_agent #影响pod网络
kesl #卡巴斯基安全软件,影响容器通信 名词解释: 和在windows环境下是一样的,xc背景下,linux的各类安全软件也非常多,如奇安信,深信服等
影响范围: 特定服务访问异常
问题定位: 以上所有排查方式都尝试过,则可往此方面排查
出现原因: 客户安全软件在内核网络层hook了对应函数,相关规则过滤了特定的应用数据库,导致异常

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)