
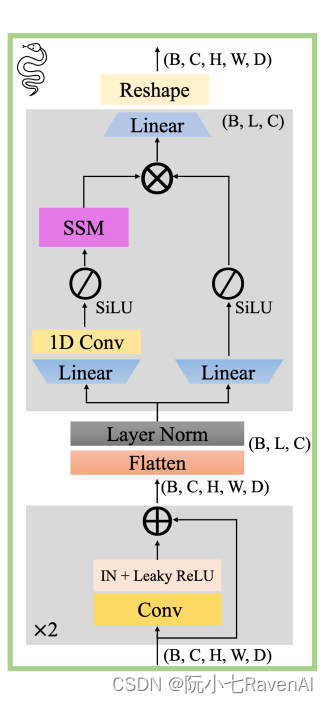
关于Umamba和mamba-SSM输入的小笔记 (2D情况)
mamba
项目地址:https://gitcode.com/gh_mirrors/ma/mamba
·
Umamba (https://arxiv.org/pdf/2401.04722.pdf) 里输入就用最正常的Pytorch格式就行,即 (B, C, H, W),

class MambaLayer(nn.Module):
def __init__(self, dim, d_state = 16, d_conv = 4, expand = 2):
super().__init__()
self.dim = dim
self.norm = nn.LayerNorm(dim)
self.mamba = Mamba(
d_model=dim, # Model dimension d_model
d_state=d_state, # SSM state expansion factor
d_conv=d_conv, # Local convolution width
expand=expand, # Block expansion factor
)
@autocast(enabled=False)
def forward(self, x):
if x.dtype == torch.float16:
x = x.type(torch.float32)
B, C = x.shape[:2]
assert C == self.dim
n_tokens = x.shape[2:].numel()
img_dims = x.shape[2:]
x_flat = x.reshape(B, C, n_tokens).transpose(-1, -2)
x_norm = self.norm(x_flat)
x_mamba = self.mamba(x_norm)
out = x_mamba.transpose(-1, -2).reshape(B, C, *img_dims)
return out
训练或推理时迭代的x, 是(B, C, H ,W), B 为batch size, C是channel dim, 比如浅层或许为1, 3, 深层512, H, W 为当前图像长宽。
初始化MambaLayer时候, dim对应的是当前channel dim, 其实就是特征深度或者说厚度,
mamba
项目地址:https://gitcode.com/gh_mirrors/ma/mamba
即 mamba_exmaple = MambaLayer(C).
我们再看看mamba本身库里,
def forward(self, hidden_states, inference_params=None):
"""
hidden_states: (B, L, D)
Returns: same shape as hidden_states
"""
batch, seqlen, dim = hidden_states.shape
hidden_states是输入x, 在上面第一块代码里即为x_norm, x_norm的维度是 所谓(B,L, D), 这里有符号的不同, 这里的D其实就是上面C, 即为特征厚度,或说特征通道数。 L是HxW, 即把图像拉长成一维数据。
阅读全文
AI总结
最近提交(Master分支:8 个月前 )
2e16fc30
* Numerical stability for large negative values
* Fix causal_conv1d xBC stride not multiple of 8 issue
* Fix backprop for causal_conv1d xBC stride not multiple of 8 issue
* Fix ddt -> dt typo
* Add nit comment
* Call ontiguous before causal_conv1d only when stride is not a multiple of 8
* Copy only if strides differ
---------
Co-authored-by: Roger Waleffe <rwaleffe@nvidia.com>
Co-authored-by: Duncan Riach <duncan@nvidia.com> 23 天前
0cce0fa6
* Update pyproject.toml
Added triton as dependency
* Use triton as dependency in setup.py 3 个月前

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)