
【LLM-RAG】BGE M3-embedding模型(模型篇|混合检索、多阶段训练)
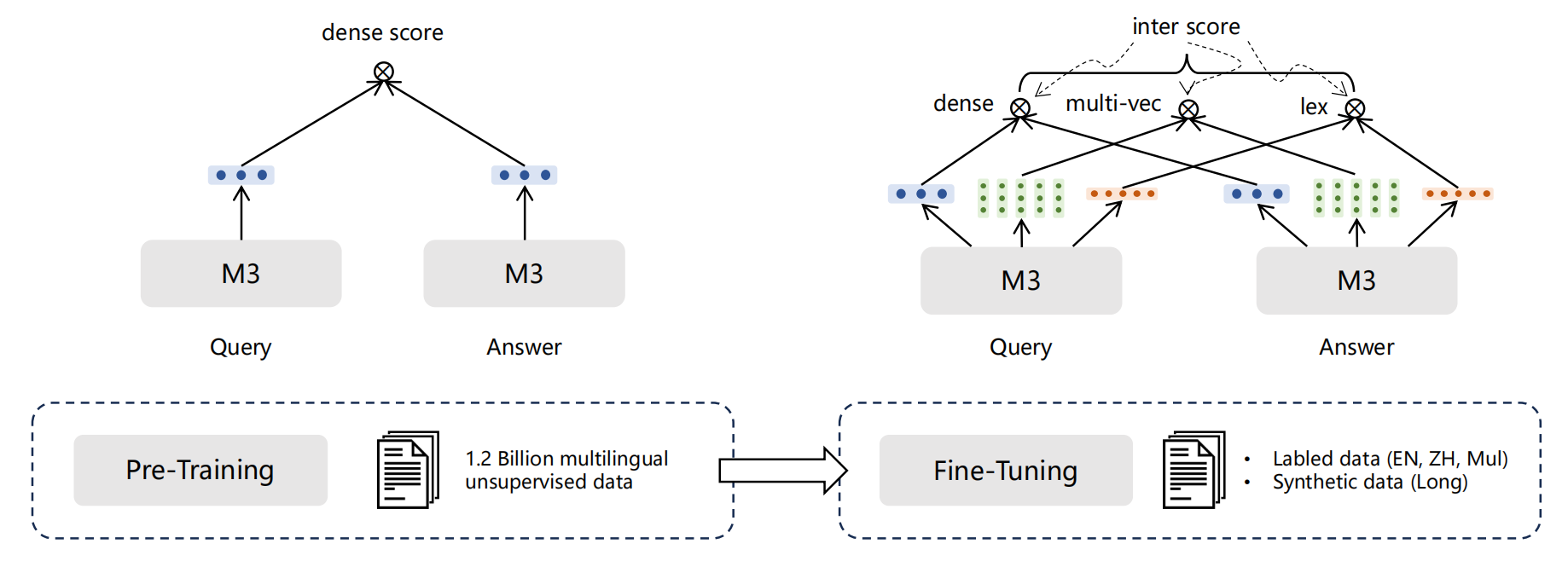
M3-Embedding联合了3种常用的检索方式,对应三种不同的文本相似度计算方法。可以基于这三种检索方式进行多路召回相关文档,然后基于三种相似度得分平均求和对召回结果做进一步重排。多阶段训练过程:在这里插入图片描述第一阶段:第一阶段的自动编码预训练采用的是RetroMAE,在105种语言的网页跟wiki数据上进行,从而获得一个基底模型第二阶段:在第一个数据源的弱监督数据进行预训练,这阶段的损失损
note
-
M3-Embedding联合了3种常用的检索方式,对应三种不同的文本相似度计算方法。可以基于这三种检索方式进行多路召回相关文档,然后基于三种相似度得分平均求和对召回结果做进一步重排。
-
多阶段训练过程:
-
第一阶段:第一阶段的自动编码预训练采用的是RetroMAE,在105种语言的网页跟wiki数据上进行,从而获得一个基底模型
-
第二阶段:在第一个数据源的弱监督数据进行预训练,这阶段的损失损失只考虑基于稠密检索的对比学习损失。
-
第三阶段:会在第二,三个数据源的监督数据进行训练,这阶段的损失就包括前面提及的所有损失,包括对比学习损失跟蒸馏损失。
文章目录
零、BGE M3-emb模型
- 项目链接:https://github.com/FlagOpen/FlagEmbedding
- 论文:BGE M3-Embedding: Multi-Lingual, Multi-Functionality,
Multi-Granularity Text Embeddings Through Self-Knowledge Distillation - 该模型支持超过100种语言,能够接受不同形式的文本输入,文本最大输入长度扩展到4192,并且支持包括稠密检索,稀疏检索,多向量检索三种不同检索手段。
- BGE M3-Embedding的效果超过微软E5-mistral-7b、openai去年发布的第三代text embedding
一、训练数据的构建
1. 三个数据来源
有三个来源:
- 没有标注信息的弱监督数据:来自于从网上挖掘得到的各种有语义关联的数据,并过滤掉其中低质量的内容。
- 来自有标注信息的监督数据:包括若干个中文跟英文的开源数据集,例如MS MARCO,NLI,DuReader等。
- 合成得到的监督数据:利用GPT3.5为来自Wiki跟MC4的长文本生成对应的问题,用于缓解模型在长文档检索任务的不足,同时引入额外的多语言数据。
注:这三种不同来源的数据相互补充,分别作用于模型不同阶段的训练

2. 微调emb的数据样例
和之前微调BGE的数据格式类似,每个query对应pos的正样例、neg的负样例(注意这里的负样例可能有多个)。
{"query": "Five women walk along a beach wearing flip-flops.", "pos": ["Some women with flip-flops on, are walking along the beach"], "neg": ["The 4 women are sitting on the beach.", "There was a reform in 1996.", "She's not going to court to clear her record.", "The man is talking about hawaii.", "A woman is standing outside.", "The battle was over. ", "A group of people plays volleyball."]}
{"query": "A woman standing on a high cliff on one leg looking over a river.", "pos": ["A woman is standing on a cliff."], "neg": ["A woman sits on a chair.", "George Bush told the Republicans there was no way he would let them even consider this foolish idea, against his top advisors advice.", "The family was falling apart.", "no one showed up to the meeting", "A boy is sitting outside playing in the sand.", "Ended as soon as I received the wire.", "A child is reading in her bedroom."]}
{"query": "Two woman are playing instruments; one a clarinet, the other a violin.", "pos": ["Some people are playing a tune."], "neg": ["Two women are playing a guitar and drums.", "A man is skiing down a mountain.", "The fatal dose was not taken when the murderer thought it would be.", "Person on bike", "The girl is standing, leaning against the archway.", "A group of women watch soap operas.", "No matter how old people get they never forget. "]}
{"query": "A girl with a blue tank top sitting watching three dogs.", "pos": ["A girl is wearing blue."], "neg": ["A girl is with three cats.", "The people are watching a funeral procession.", "The child is wearing black.", "Financing is an issue for us in public schools.", "Kids at a pool.", "It is calming to be assaulted.", "I face a serious problem at eighteen years old. "]}
{"query": "A yellow dog running along a forest path.", "pos": ["a dog is running"], "neg": ["a cat is running", "Steele did not keep her original story.", "The rule discourages people to pay their child support.", "A man in a vest sits in a car.", "Person in black clothing, with white bandanna and sunglasses waits at a bus stop.", "Neither the Globe or Mail had comments on the current state of Canada's road system. ", "The Spring Creek facility is old and outdated."]}
{"query": "It sets out essential activities in each phase along with critical factors related to those activities.", "pos": ["Critical factors for essential activities are set out."], "neg": ["It lays out critical activities but makes no provision for critical factors related to those activities.", "People are assembled in protest.", "The state would prefer for you to do that.", "A girl sits beside a boy.", "Two males are performing.", "Nobody is jumping", "Conrad was being plotted against, to be hit on the head."]}
{"query": "A man giving a speech in a restaurant.", "pos": ["A person gives a speech."], "neg": ["The man sits at the table and eats food.", "This is definitely not an endorsement.", "They sold their home because they were retiring and not because of the loan.", "The seal of Missouri is perfect.", "Someone is raising their hand.", "An athlete is competing in the 1500 meter swimming competition.", "Two men watching a magic show."]}
{"query": "Indians having a gathering with coats and food and drinks.", "pos": ["A group of Indians are having a gathering with food and drinks"], "neg": ["A group of Indians are having a funeral", "It is only staged on Winter afternoons in Palma's large bullring.", "Right information can empower the legal service practices and the justice system. ", "Meanwhile, the mainland was empty of population.", "Two children is sleeping.", "a fisherman is trying to catch a monkey", "the people are in a train"]}
{"query": "A woman with violet hair rides her bicycle outside.", "pos": ["A woman is riding her bike."], "neg": ["A woman is jogging in the park.", "The street was lined with white-painted houses.", "A group watches a movie inside.", "man at picnics cut steak", "Several chefs are sitting down and talking about food.", "The Commission notes that no significant alternatives were considered.", "We ran out of firewood and had to use pine needles for the fire."]}
{"query": "A man pulls two women down a city street in a rickshaw.", "pos": ["A man is in a city."], "neg": ["A man is a pilot of an airplane.", "It is boring and mundane.", "The morning sunlight was shining brightly and it was warm. ", "Two people jumped off the dock.", "People watching a spaceship launch.", "Mother Teresa is an easy choice.", "It's worth being able to go at a pace you prefer."]}
二、混合检索
M3-Embedding联合了3种常用的检索方式,对应三种不同的文本相似度计算方法。可以基于这三种检索方式进行多路召回相关文档,然后基于三种相似度得分平均求和对召回结果做进一步重排。
1. Dense retrieval
Dense retrieval: 给定一个文本,获取语言模型最后一层上[CLS]位置的隐状态,经过标准化作为文本的稠密向量表征。通过计算query跟doc的向量表征之间的内积就知道文本之间的稠密检索相似度。
注:这是目前主流text embedding模型用的比较多的一种检索方式,这部分表征更注重文本整体的语义信息。
2. Lexical Retrieval
Lexical Retrieval:给定一个文本,获取语言模型最后一层上所有位置的隐状态,每个位置对应原始文本中的一个token,依次将每个位置的隐状态通过一个全连接层+Relu函数得到该token的权重,将所有每个token的隐状态*对应的权重再求和作为文本的稀疏表征(如果文本包含两个以上相同的token,则该token的权重取其中最大的权重值)。
注:很像tfidf,也跟RetroMAE-V2的第二部分特征很相似,这部分特征更在意文本中各个token的信息,重要的token就赋予更高的权重。
3. Multi-Vec Retrieval
Multi-Vec Retrieval: 给定一个文本,获取语言模型最后一层上所有位置的隐状态,经过一个全连接矩阵跟标准化后得到文本的多向量表征(文本的多向量表征维度为n*d,其中n是文本长度,d是隐状态维度)。给定query,query上第i个位置跟doc的相似度的计算方式为依次计算query第i个位置的多向量表征跟doc各个位置上的多向量表征之间的内积,取其中最大值作为其得分,将query上所有位置跟doc的相似度平均求和就得到对应的多向量表征相似度。其实这就是稠密检索的一个引申版本。
三、训练方式
1. loss的组成
loss由两个部分组成:
- 第一部分是对比学习损失,沿用InfoNCE的方式,希望拉近query跟相关文档之间的距离,同时疏远query跟不相关文档之间的距离,但是由于M3-Embedding提供了三种相似度计算方式,所以这里其实是包含了3个对比学习损失的。
- 第二部分蒸馏损失,研究人员将三种不同方式的相似度得分进行加权求和作为teacher分数,然后让三种相似度得分去学习teacher得分的信息,由此得到3个蒸馏损失。
2. 多阶段训练
多阶段训练过程:
- 第一阶段:第一阶段的自动编码预训练采用的是RetroMAE,在105种语言的网页跟wiki数据上进行,从而获得一个基底模型
- 第二阶段:在第一个数据源的弱监督数据进行预训练,这阶段的损失损失只考虑基于稠密检索的对比学习损失。
- 最后第三阶段会在第二,三个数据源的监督数据进行训练,这阶段的损失就包括前面提及的所有损失,包括对比学习损失跟蒸馏损失。
四、实验结果
1. 任务上的表现
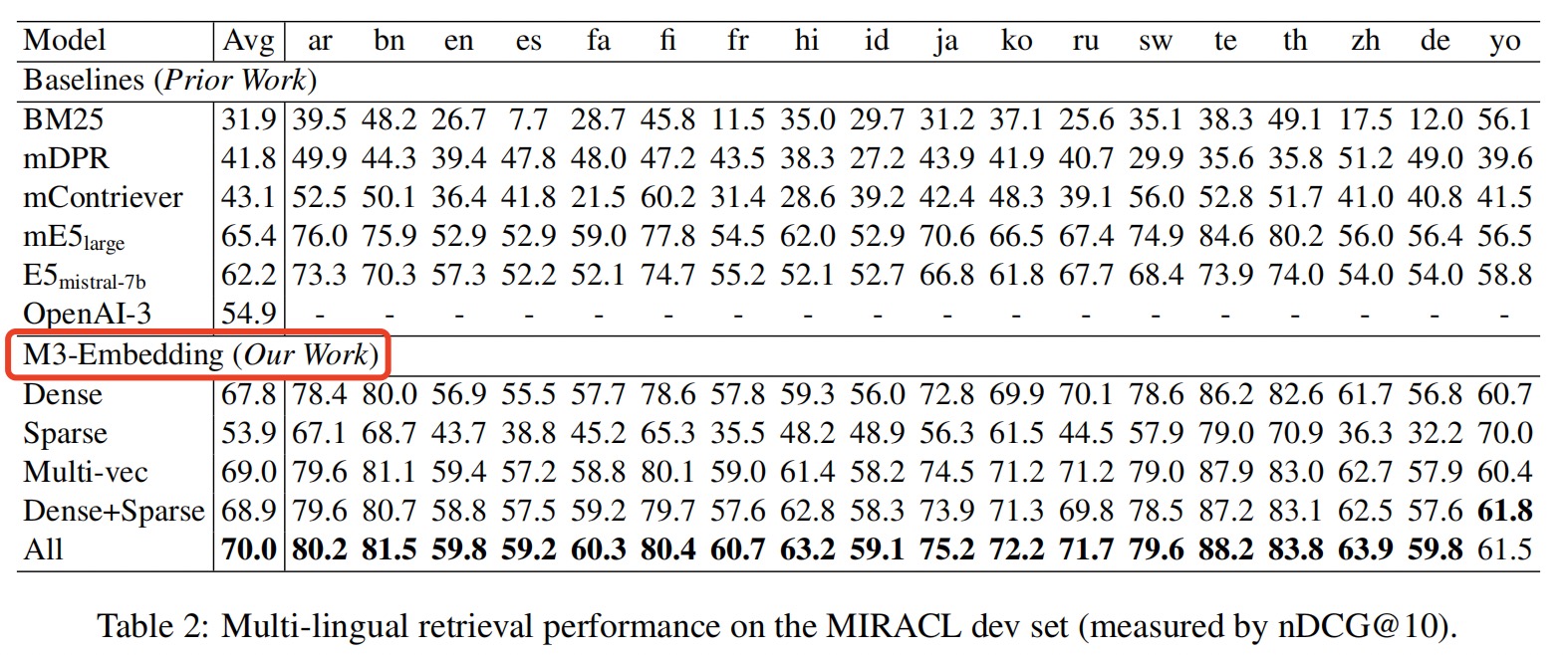
(1)在多语言检索,跨语言检索,多语言长文档检索等任务上效果表现出色
2. 消融实验
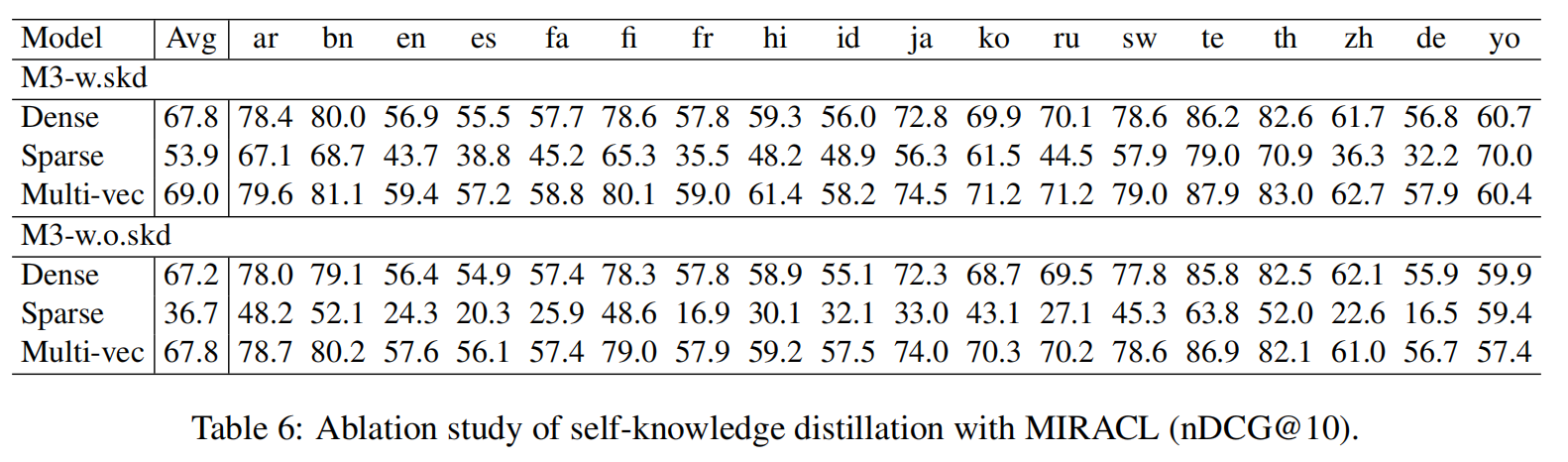
(2)通过消融实验对比,可以发现在使用不同相似度计算方式条件下,M3-Embedding中的蒸馏损失都能给最终效果带来明显提升,尤其是对于稀疏检索而言。
Reference
[1] BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation
[2] https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/BGE_M3/BGE_M3.pdf
[3] BGE M3-Embedding:智源最新发布的text embedding模型,多语言检索效果超过微软跟openai
[4] 中文原生检索增强生成测评基准 : https://github.com/CLUEbenchmark/SuperCLUE-RAG

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 14
14 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)