
详解多模态大模型:LLaVA+LLaVA1.5+LLaVA-Med
作者:凯恩博,香港城市大学计算机科学博士编辑:青稞AILLaVA repo:https://github.com/haotian-liu/LLaVA/LLaVA 1.0:Visual Instruction TuningLLaVA 1.5:Improved Baselines with Visual Instruction Tuning一句话优点:1、极大简化了VLM的训练方式:Pre-tra..
作者:凯恩博,香港城市大学计算机科学博士
编辑:青稞AI
LLaVA repo:https://github.com/haotian-liu/LLaVA/
LLaVA 1.0:Visual Instruction Tuning
LLaVA 1.5:Improved Baselines with Visual Instruction Tuning
一句话优点:
1、极大简化了VLM的训练方式:Pre-training + Instruction Tuning
2、训练量得到简化:1M量级数据+ 8卡A100 → 一天完成训练
影响力
LLaVA是2023的连续工作,包含了LLaVA 1.0和 1.5两个版本,也是2023年多模态领域妥妥的顶流。发表9个月620的stars,GitHub超过12K的stars。
LLaVA它的网络结构简单、微调成本比较低,任何研究组、企业甚至个人都可以基于它构建自己的领域的多模态模型。
非常建议对多模态大模型感兴趣的朋友关注LLaVA这篇工作。
简介
LLaVA通过使用机器生成的指令遵循数据对大型语言模型(LLMs)进行指令调优,已经在新任务上提高了零样本能力,但在多模态领域,这一想法还没有被充分探讨。在本文中,我们首次尝试使用GPT-4生成多模态语言-图像指令遵循数据。通过对这些生成数据进行指令调优,作者引入了LLaVA:一个大型语言和视觉助手。LLavA是一个端到端训练的大型多模态模型,将视觉Encoder和LLM连接起来,用于通用视觉和语言理解。实验表明,LLaVA展示了令人印象深刻的多模型聊天能力,有时会展示出在未见过的图像/指令上的类似于GPT-4v的表现,并在一个合成的多模态指令遵循数据集上获得了与相比于GPT-4 85.1%的相对分数。在Science QA上进行微调时,LLaVA和GPT-4的协同作用实现了新的SOTA准确率92.53%。
Contributions
LLaVA的贡献包括以下几个方面:
• 多模态指令跟随数据。由于缺乏视觉-语言指令跟随数据,作者利用ChatGPT/GPT-4提出了一种将图像文本对转换成适当的指令跟随格式的数据重新构造方法。
• 大型多模态模型。作者开发了一个大型多模态模型(LMM),通过将CLIP的开放集视觉编码器与语言解码器Vicuna相连接,并在我们生成的指令视觉语言数据上进行端到端微调。证明了使用生成数据进行LMM指令调优的有效性,并为构建通用的指令跟随视觉代理提供了实用建议。当与GPT-4集成时,我们的方法在Science QA多模态推理数据集上实现了最佳性能。
• 多模态指令跟随基准测试。作者提出了LLaVA-Bench,包括两个具有挑战性的基准测试,其中包含多样化的配对图像、指令和详细注释。
• 开源。包括生成的多模态指令数据、代码库、模型文件等。
网络架构

网络架构图
• ViT:CLIP ViT-L/14-224px(LLaVA 1.5用的是 CLIP ViT-L/14-336px )
• Text:Vicuna 13B (推理)
• Projection:MLP * 2 (Linear → GELU → Linear) 类似翻译官(编译器)的角色 架构设计时,主要考虑要复用已有的LLM和Visual预训练模型。Projection scheme选择非常轻量的MLP是为了能够快速的实验迭代。
两阶段训练
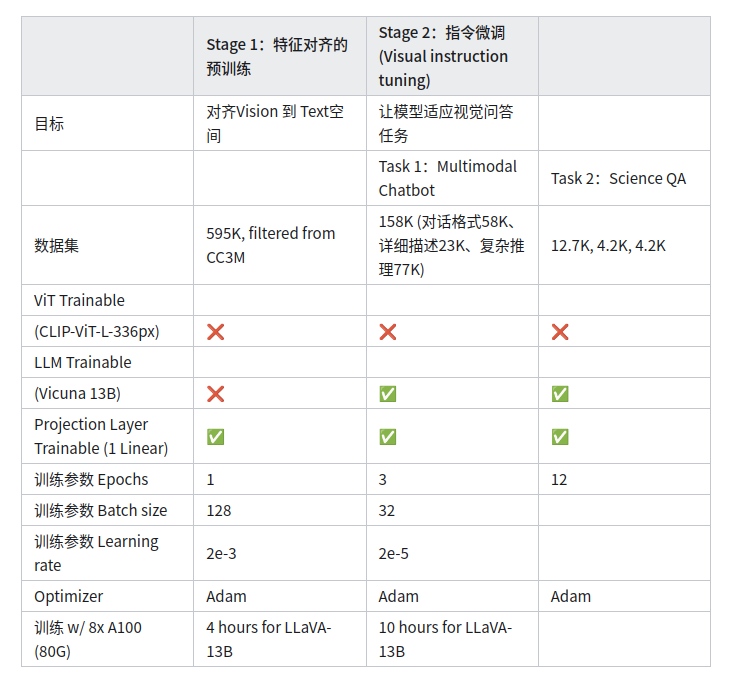
Dataset
利用ChatGPT/GPT-4生成多样化的QA pairs。
利用两种格式的数据:
• Captions
• Bounding boxes
对于每类数据,先人工标注一些数据,作为In-context-learning的few-shot examples,送给GPT-4。共计158K
• 对话格式:58K
• 详细描述:23K
• 复杂推理:77K
实验结果
在Chatbot任务上,大幅的超过同期的BLIP-2和OpenFlamingo

在ScienceQA任务上,其实没超过SOTA MM-CoT_Large,但是结合上GPT-4的ensembling 模型,高过SOTA不到1个点。

文章同时做了一些ablation study,一些值得关注的结论:
1、视觉特征提取:使用ViT倒数第二层的Features更有利
2、思维链CoT:发现“先生成reason再生成answer” 相比“先生成answer再生成reason” 仅对模型快速收敛有帮助,对最终的性能 上限的提升没帮助。
3、Pre-train:证明了pre-train的有效性,pre-train+scienceQA finetune 相对比 直接在ScienceQA train from scratch 会提升5.11%。
4、模型大小:7B比13B的低1.08%,印证了越大的LLM对整体的性能越有利。
5、涌现能力:LLaVA 的一个有趣的涌现行为是它能够理解训练中未涵盖的视觉内容。此外LLaVA 还展示了令人印象深刻的 OCR(光学字符识别)能力。
更强的LLaVA 1.5
作者在LLaVA 1.0发布后半年左右,推出了LLaVA 1.5。
LLaVA-1.5在11个基准测试中达到了SoTA水平,仅通过对原始LLaVA进行简单修改,利用约一百万量级的数据,超越了使用十亿规模数据的方法。
搬上超强直观的雷达图,各项指标超越BLIP-2、InstructBLILP、Qwen-VL-Chat。

Ablation Study显示了Format Prompt(显式Prompt回答问题的方式)、Projection Layer从单个Linear 改为MLP(两层Linear+Activation)、更丰富的数据、更大的LLM 模型(从7B到13B)、更大的ViT分辨率(从224px到336px)。如下图:

和一些SOTA方法的对比细节:

从训练的细节上看,LLaVA 1.5的训练方式和LLaVA 1.0基本一致。但在一些细节上不同,比如Optimizer换成AdamW、batch size更大、Stage 2更少的epochs,整体的训练时长基本翻倍。
LLaVA 1.5的实验细节如下:
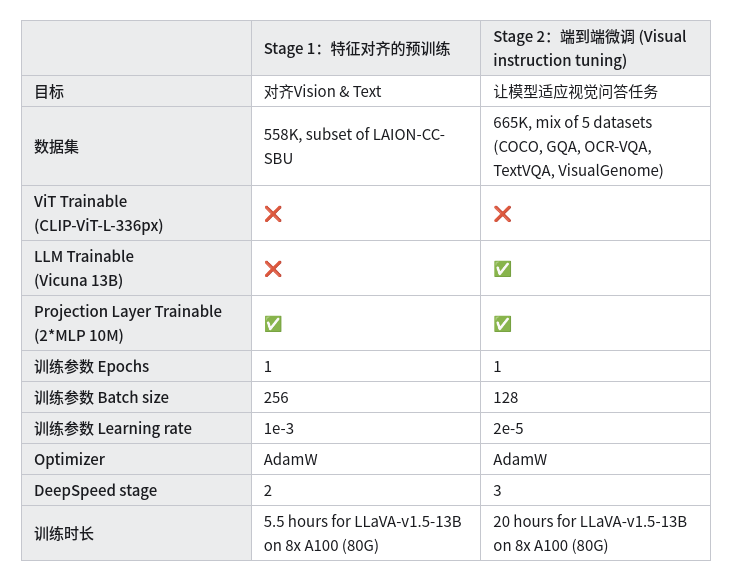
自有数据微调
LLaVA的code repo写的非常好(感谢作者的开源)。如果个人希望基于LLaVA的模型对自己的数据集做微调,是非常容易的,尤其是采用LoRA这样的微调方式。
主要可参考https://github.com/haotian-liu/LLaVA/tree/main/scripts/v1_5里的微调脚本,其中LoRA Finetune使用https://github.com/haotian-liu/LLaVA/blob/main/scripts/v1_5/finetune_lora.sh 即可,其中shell脚本如下:
deepspeed llava/train/train_mem.py \
--lora_enable True --lora_r 128 --lora_alpha 256 --mm_projector_lr 2e-5 \
--deepspeed ./scripts/zero3.json \
--model_name_or_path lmsys/vicuna-13b-v1.5 \
--version v1 \
--data_path ./playground/data/llava_v1_5_mix665k.json \
--image_folder ./playground/data \
--vision_tower openai/clip-vit-large-patch14-336 \
--pretrain_mm_mlp_adapter ./checkpoints/llava-v1.5-13b-pretrain/mm_projector.bin \
--mm_projector_type mlp2x_gelu \
--mm_vision_select_layer -2 \
--mm_use_im_start_end False \
--mm_use_im_patch_token False \
--image_aspect_ratio pad \
--group_by_modality_length True \
--bf16 True \
--output_dir ./checkpoints/llava-v1.5-13b-lora \
--num_train_epochs 1 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 50000 \
--save_total_limit 1 \
--learning_rate 2e-4 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--tf32 True \
--model_max_length 2048 \
--gradient_checkpointing True \
--dataloader_num_workers 4 \
--lazy_preprocess True \
--report_to wandb通常自己需要修改的主要涉及:
• data_path:你自有数据集的json路径,构造方式可参考
https://github.com/haotian-liu/LLaVA/blob/main/docs/Finetune_Custom_Data.md
• image_folder:你自有数据集的图片路径
• per_device_train_batch_size:这个主要和你GPU的显存有关系的
此外需注意,因为使用的是DeepSpeed,所有的GPU默认会被全部占用。另外finetune_lora.sh里的DeepSpeed使用了ZeRO Stage 3。
相关工作:LLaVA-Med
LLaVA-Med是基于LLaVA,适配到生物医学领域的工作。展现了LLaVA在专有领域的有效性。
• LLaVA-Med:https://arxiv.org/abs/2306.00890
从下图来看,延续了LLaVA的two-stage训练的方式。额外增加了在downstream数据集中的微调环节。

一些实验的细节如下,不具体展开了。
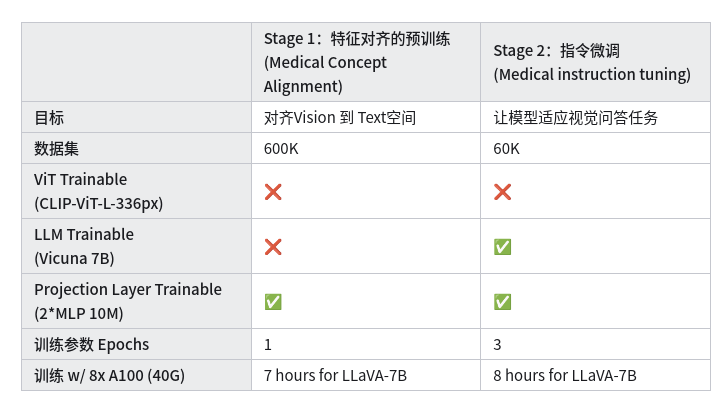
下表的实验证明了Stage-2的必要性、大数据量的必要性

LLaVA-Med Ablation Study
• LLaVA-Med性能大幅超过LLaVA原声模型,说明在biomedical domain-specific adaption的有效性
• Stage 1训练更长时间对于提升Zero-shot能力有帮助,但仅仅只有Stage 1指标仍然很低
• Stage 2的Instruction-following的数据很关键,而且从10K到60K增长过程中,模型指标不断提升。此外inline mention有一点帮助
• 在下游数据集上finetune到9个epochs是有帮助的
• 语言模型从7B提升到13B有一点帮助
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 4
4 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)