
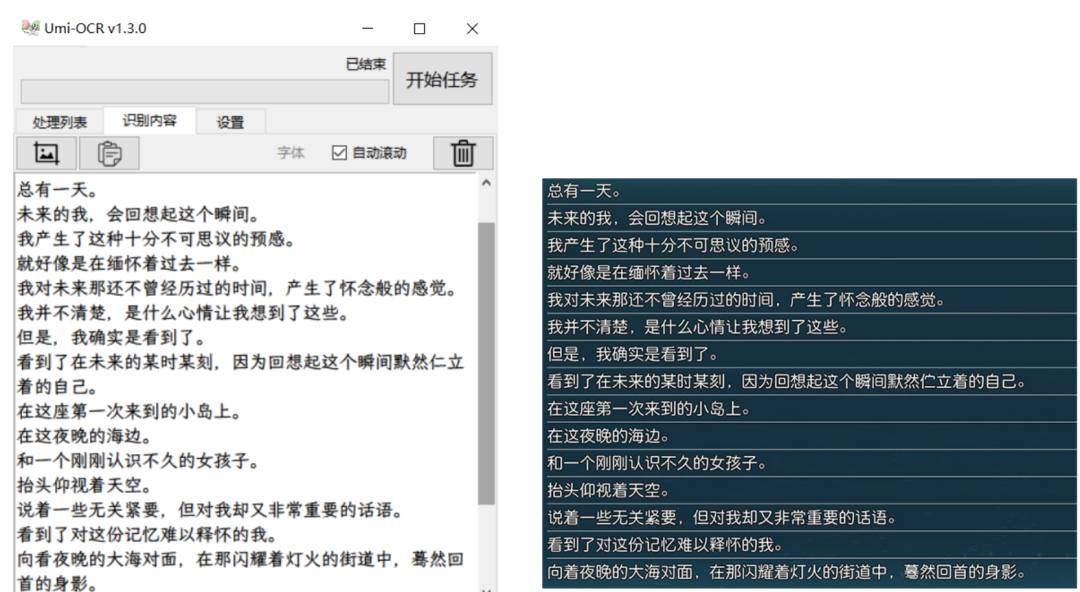
【GitHub项目推荐--OCR 图片转文字识别软件】【转载】
基于 PaddleOCR 的 OCR 图片转文字软件,已经获得 3.6K 的 Star。该开源项目完全离线,支持截屏/批量导入图片,除了能准确辨认常规文字,对手写、方向不正、杂乱背景等情景也有不错的识别率。可设置忽略区域排除水印、设置文块后处理合并排版段落,得到规整的文本。开源地址:https://github.com/hiroi-sora/Umi-OCR。
Umi-OCR
基于 PaddleOCR 的 OCR 图片转文字软件,已经获得 3.6K 的 Star。该开源项目完全离线,支持截屏/批量导入图片,除了能准确辨认常规文字,对手写、方向不正、杂乱背景等情景也有不错的识别率。可设置忽略区域排除水印、设置文块后处理合并排版段落,得到规整的文本。
开源地址:https://github.com/hiroi-sora/Umi-OCR
Tesseract 开源 OCR 引擎(主存储库)
github地址
https://github.com/tesseract-ocr/tesseract
官方网址
tesseract-ocr.github.io/
Tesseract 是一个开源的光学字符识别(OCR)引擎,它能够从图像文件中识别和提取文字。Tesseract 由 Ray Smith 在 1985 到 1995 年间在惠普公司(Hewlett-Packard)的布里斯托尔实验室开发。在 2005 年,Tesseract 被惠普开源,并且自 2006 年以来,它一直在由 Google 进行维护和开发。
Tesseract 的主要特点包括:
1. 多语言支持:Tesseract 支持多种语言,包括但不限于英语、中文、西班牙语、法语、德语等。它通过使用预训练的语言模型来提高识别的准确性。
2. 平台兼容性:Tesseract 可以在多种操作系统上运行,包括 Windows、Linux、Mac OS X 等。
3. 命令行工具:Tesseract 主要作为一个命令行工具提供,用户可以通过命令行接口与它交互,执行 OCR 任务。
4. 易于集成:Tesseract 可以很容易地集成到其他应用程序中,它提供了多种编程语言的接口,如 C/C++、Python、Java 等。
5. 开源和免费:Tesseract 是完全开源的,并且可以免费使用。它的源代码托管在 GitHub 上,任何人都可以贡献代码或者修改代码来适应自己的需求。
6. 社区支持:Tesseract 拥有一个活跃的社区,用户和开发者可以分享经验、解决问题和改进引擎。
7. 培训和自定义:Tesseract 允许用户对自己的数据集进行训练,以创建定制的语言模型和字符识别规则。
8. 输出格式:Tesseract 支持多种输出格式,包括纯文本、HTML、PDF、TSV 等,这使得它可以根据不同的需求进行灵活的使用。
Tesseract 的最新版本是 4.x,它引入了一些新的功能和改进,包括一个基于神经网络(LSTM)的 OCR 引擎,这个新引擎专注于线条识别,并且提供了更好的字符识别性能。Tesseract 4 也与之前的版本兼容,支持旧的 OCR 引擎模式 (--oem0) 和相关的 traineddata 文件。
总的来说,Tesseract 是一个功能强大、灵活且不断进化的 OCR 引擎,它在学术、商业和开源社区中都有广泛的应用。
Tesseract 4 添加了一个新的基于神经网络 (LSTM) 的OCR 引擎,该引擎专注于线条识别,但仍然支持 Tesseract 3 的旧版 Tesseract OCR 引擎,该引擎通过识别字符模式进行工作。通过使用旧版 OCR 引擎模式 (--oem 0) 可以实现与 Tesseract 3 的兼容性。它还需要支持旧引擎的经过训练的数据文件,例如来自tessdata存储库的数据文件。
Stefan Weil 是现任首席开发人员。Ray Smith 一直是首席开发人员,直到 2018 年。维护者是 Zdenko Podobny。有关贡献者列表,请参阅作者 和 GitHub 的贡献者日志。
Tesseract支持 unicode (UTF-8),并且可以“开箱即用”识别100 多种语言。
Tesseract 支持多种图像格式,包括 PNG、JPEG 和 TIFF。
Tesseract 支持各种输出格式:纯文本、hOCR (HTML)、PDF、仅不可见文本的 PDF、TSV 和 ALTO。
您应该注意,在许多情况下,为了获得更好的 OCR 结果,您需要提高提供给 Tesseract 的图像质量。
该项目不包括 GUI 应用程序。如果您需要,请参阅3rdParty文档。
可以训练Tesseract识别其他语言。有关更多信息,请参阅Tesseract 培训。
安装
您可以通过预构建的二进制包安装 Tesseract 或从源代码构建它。
从源代码构建 Tesseract 需要具有良好 C++17 支持的 C++ 编译器。
运行
基本命令行用法:
tesseract imagename outputbase [-l lang] [--oem ocrenginemode] [--psm pagesegmode] [configfiles...]
有关各种命令行选项的更多信息,请使用tesseract --help或man tesseract。
示例可以在文档中找到。
Tesseract 开源 OCR 引擎的使用场景非常广泛,它可以应用于多种环境和场合,以下是一些常见的使用场景:
1. 文档数字化:将纸质文档转换为电子文档,以便于存储、检索和编辑。Tesseract 可以识别文档中的文字,从而实现文档的数字化。
2. 数据录入自动化:在需要手动输入大量数据的场景中,如调查问卷、表单处理等,Tesseract 可以自动识别和输入文本,提高数据录入的效率。
3. 图像和视频分析:在图像和视频分析中,Tesseract 可以用于提取场景中的文本信息,例如从新闻报道、社交媒体视频等中提取关键信息。
4. 文本挖掘和自然语言处理:Tesseract 可以用于从大量文本中提取关键信息,支持文本挖掘和自然语言处理的应用,如情感分析、关键词提取等。
5. 教育辅助:在教育领域,Tesseract 可以用于识别试卷、讲义等教育材料中的文字,帮助教师和学生快速整理和复习资料。
6. 金融和保险行业:在金融和保险行业中,Tesseract 可以用于处理各种文档,如支票、保险单、发票等,自动化处理和验证文本信息。
7. 零售和电子商务:在零售和电子商务领域,Tesseract 可以用于识别商品标签、条形码等,支持库存管理、价格比较等应用。
8. 医疗健康:在医疗健康领域,Tesseract 可以用于识别病历、检查报告等医疗文档中的文字,提高医疗信息处理的效率。
9. 交通和导航:在交通和导航领域,Tesseract 可以用于识别路标、交通标志等图像中的文本信息,帮助提高导航系统的准确性。
10. 社交媒体内容分析:在社交媒体平台中,Tesseract 可以用于识别用户生成内容中的文本,如评论、帖子等,支持内容分析和监控。
11. 艺术品和文化遗产保护:在艺术品和文化遗产保护领域,Tesseract 可以用于识别和记录历史文献、艺术品描述等中的文本信息。
12. 验证码识别:在需要自动识别验证码的场景中,如自动化测试、机器人程序等,Tesseract 可以用于识别和输入验证码中的文字。
Tesseract 的开源特性和灵活性使其能够适应各种不同的应用场景,用户可以根据自己的需求进行定制和扩展。随着技术的不断进步,Tesseract 的应用领域也在不断扩展。
EasyOCR
EasyOCR 是一个用于从图像中提取文本的 python 模块。它是一种通用的 OCR,既可以读取自然场景文本,也可以读取文档中的密集文本。我们目前支持 80 多种语言,并且还在不断扩展。
github地址:
https://github.com/yuanxiaoming8899/EasyOCR
国内源代码地址:
http://www.gitpp.com/yuanxiaoming/EasyOCR
EasyOCR 是一款功能强大的光学字符识别(OCR)软件,它可以识别多种语言和书写脚本。这意味着无论您需要处理哪种语言的文本,EasyOCR 都能为您提供准确的识别结果。
以下是 EasyOCR 支持的一些主要语言和书写系统:
1. 拉丁文:包括英语、法语、德语、西班牙语、葡萄牙语等。
2. 中文:简体和繁体。
3. 阿拉伯文:包括阿拉伯语、波斯语、乌尔都语等。
4. 梵文:印度梵语、巴利文等。
5. 西里尔文:包括俄语、乌克兰语、塞尔维亚语等。
6. 希伯来文。
7. 希腊文。
8. 土耳其文。
9. 朝鲜文。
10. 日文:包括汉字、平假名、片假名等。
此外,EasyOCR 还支持其他许多语言和书写系统,总计达 80 多种。这使得它成为处理多种语言文本的理想工具,特别是在跨国企业、研究机构或个人需求的场景中。
值得一提的是,EasyOCR 具有较高的识别准确率,但在处理某些复杂或模糊的字体时,也可能出现误识别。为了解决这个问题,您可以尝试使用其他辅助工具,如人工校对,以提高识别结果的准确性。总之,EasyOCR 是一款值得尝试的 OCR 软件,尤其是对于需要处理多种语言和书写系统的人来说。
背景介绍
OCR(Optical Character Recognition,光学字符识别)是一种图型识别技术,其目的是让计算机能够识别纸质文档、图片等中的文字信息。通过光学方式将文档中的文字转换为计算机可处理的数字文本,OCR 技术解决了低速信息输入与高速信息处理之间的矛盾,提高了整个计算机系统的效率。
OCR 技术的主要功能如下:
1. 汉字识别:采用光学方式将纸质文档中的汉字转换为计算机文本文件,便于文字处理软件进一步编辑和加工。
2. 自动判断、拆分、识别和还原各种通用型印刷体表格。
3. 自动分析文稿的版面布局,分栏、判断标题、横栏、图像、表格等相应属性,并确定识别顺序。
4. 提高识别正确率:通过除错或利用辅助信息,如词典、语法规则等,提高识别准确率。
5. 跨行业应用:OCR 技术在多个行业均有广泛应用,如印刷业、图书馆、档案馆、政务处理等。
6. 智能化发展:随着人工智能技术的融入,OCR 识别软件具备了更高的智能水平,如自动纠错、语言理解等。
7. 便捷性:用户可以通过拍照、扫描等方式将纸质文档中的文字快速转换为计算机文本,节省了大量打字时间。
目前,许多企业和软件产品都采用了 OCR 技术,如谷歌、百度、有道云笔记等。随着技术的不断发展和创新,OCR 技术在各个领域的应用将更加广泛,为人们的生活和工作带来更多便利。
EasyOCR 是一款功能强大的光学字符识别(OCR)软件,其应用场景广泛主要包括以下几类:
1. 文档处理:EasyOCR 可以帮助用户将纸质文档、扫描件或其他来源的文本转换为可编辑的数字文本。这类应用场景包括:
- 纸质文件数字化:将纸质文件(如合同、报告、手册等)转换为电子文档,便于存储和检索。
- 图片文本提取:从图片中提取出文字内容,如合影中的字幕、广告牌上的文字等。
- 电子文档处理:将模糊、畸变的电子文档(如 PDF、扫描件等)转化为可编辑的文本。
2. 语言学习与翻译:EasyOCR 可以识别多种语言,帮助学习者获取外语学习材料,或进行跨语言交流。应用场景包括:
- 外文文献翻译:将外文文献(如学术论文、新闻报道等)转换为中文,便于阅读和理解。
- 口语翻译:实时识别对话中的外语文字,为语言学习者和外籍人士提供便利。
3. 商业应用:EasyOCR 可以帮助企业和个人实现文字信息的自动化处理,提高工作效率。应用场景包括:
- 数据录入:将纸质表格、问卷等数据转换为电子表格,进行数据分析。
- 商品信息采集:从图片或网页中提取商品信息,如商品名称、价格、规格等。
- 文字监控与分析:实时监测特定场景(如社交媒体、网站评论等)的文字信息,进行情感分析、关键词提取等。
4. 娱乐与创作:EasyOCR 可以将图片中的文字内容提取出来,应用于各种创意项目。应用场景包括:
- 图片编辑:从图片中提取文字,进行编辑、替换等操作。
- 字体设计:从书法作品、手写字体等中提取文字,用于字体创作。
- 影视制作:从电影、电视剧等素材中提取字幕,进行后期处理。
5. 其他应用场景:
- 医学影像分析:识别病历、报告等医疗文档中的关键信息。
- 智能家居:与智能音响、智能投影等设备结合,实现语音识别和文字输出。
- 自动驾驶:识别道路标志、指示牌等,为自动驾驶汽车提供支持。
总之,EasyOCR 是一款实用的 OCR 工具,其应用场景丰富多样,可以满足个人和企业的各种需求。



安装方式
安装使用pip
对于最新的稳定版本:
pip install easyocr
对于最新的开发版本:
pip install git+https://github.com/JaidedAI/EasyOCR.git
注 1:对于 Windows,请先按照官方说明安装 torch 和 torchvision https://pytorch.org。在 pytorch 网站上,请务必选择您拥有的正确的 CUDA 版本。如果您打算仅在 CPU 模式下运行,请选择CUDA = None。
注2:我们在这里还提供了一个Dockerfile 。
用法
import easyocr
reader = easyocr.Reader(['ch_sim','en']) # this needs to run only once to load the model into memory
result = reader.readtext('chinese.jpg')
输出将采用列表格式,每个项目分别代表一个边界框、检测到的文本和置信度。
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路', 0.3754989504814148), ([[86, 80], [134, 80], [134, 128], [86, 128]], '西', 0.40452659130096436), ([[517, 81], [565, 81], [565, 123], [517, 123]], '东', 0.9989598989486694), ([[78, 126], [136, 126], [136, 156], [78, 156]], '315', 0.8125889301300049), ([[514, 126], [574, 126], [574, 156], [514, 156]], '309', 0.4971577227115631), ([[226, 170], [414, 170], [414, 220], [226, 220]], 'Yuyuan Rd.', 0.8261902332305908), ([[79, 173], [125, 173], [125, 213], [79, 213]], 'W', 0.9848111271858215), ([[529, 173], [569, 173], [569, 213], [529, 213]], 'E', 0.8405593633651733)]
注1:['ch_sim','en']是您要阅读的语言列表。您可以同时传递多种语言,但并非所有语言都可以一起使用。英语与所有语言兼容,并且具有共同字符的语言通常彼此兼容。
注 2:除了 filepath 之外chinese.jpg,您还可以将 OpenCV 图像对象(numpy 数组)或图像文件作为字节传递。原始图像的 URL 也是可以接受的。
注3:该行reader = easyocr.Reader(['ch_sim','en'])用于将模型加载到内存中。这需要一些时间,但只需运行一次。
您还可以设置detail=0更简单的输出。
reader.readtext('chinese.jpg', detail = 0)
结果:
['愚园路', '西', '东', '315', '309', 'Yuyuan Rd.', 'W', 'E']
所选语言的模型权重将自动下载,或者您可以从模型中心手动下载它们并将其放入“~/.EasyOCR/model”文件夹中
如果您没有 GPU,或者您的 GPU 内存不足,您可以通过添加gpu=False.
reader = easyocr.Reader(['ch_sim','en'], gpu=False)
有关更多信息,请阅读教程和API 文档。
在命令行上运行
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=True
目前市面上有很多优秀的 OCR 库可供选择,这些库涵盖了多种编程语言和平台,以下是一些常见的 OCR 库:
1. Tesseract:Tesseract 是一个开源的 OCR 引擎,支持多种编程语言,如 Python、Java、C++ 等。它由 Google 开发并维护,具有较高的识别准确率和兼容性。Tesseract 支持识别多种文本格式,如 PDF、PNG、JPEG 等。
2. CuneiForm:CuneiForm 是一款由 Cognitive Technologies(俄罗斯)开发的 OCR 库,支持 Windows 平台。它具有较高的识别准确率,尤其擅长识别手写体文字。
3. GOCR:GOCR 是德国大学计算机科学研究所开发的一个 OCR 引擎,支持 Python 语言。GOCR 具有较好的识别性能,尤其在识别德语文字方面表现优异。
4. CRAFT:CRAFT 是一款基于深度学习技术的 OCR 库,支持 Python 语言。它由 Clova AI 实验室开发,具有较高的识别准确率和自适应能力。
5. pytesseract:pytesseract 是 Tesseract 的一个 Python 绑定库,支持多种 Python 版本。它提供了简单易用的 API,方便开发者快速实现 OCR 功能。
6. OpenCV:OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,包含了许多图像处理、视频分析等功能。OpenCV 中的 OCR 模块支持多种语言,如 C++、Python 等。
7. Google Cloud Vision API:Google 提供的 Cloud Vision API 包含了一项 OCR 服务,支持识别多种文本格式,如 PDF、JPEG、PNG 等。该服务基于 Tesseract 引擎,并提供了丰富的 API 接口。
这些 OCR 库具有各自的特点和优势,开发者可以根据项目需求和编程语言选择合适的库进行开发。随着 OCR 技术的不断发展,更多优秀的 OCR 库将不断涌现。
github地址:
https://github.com/yuanxiaoming8899/EasyOCR
pix2tex: 一种 LaTeX-OCR
LaTeX-OCR是使用程序方便的将数学方程图像转换为 LaTeX 代码。数学公式轻松搞定!!
如果搞科研,长期写论文,还是学习一下 LaTex。
github地址:
https://github.com/lukas-blecher/LaTeX-OCR
国内源代码:
http://www.gitpp.com/yuanxiaoming/EasyOCR
OCR(Optical Character Recognition,光学字符识别)是一种将扫描文本转换为可编辑文本的技术。它通过扫描纸质文档或图像中的文本,然后使用光学字符识别软件将图像中的字符识别出来,转化为计算机可处理的文本格式。OCR 技术在许多领域都有广泛应用,如图书馆、档案馆、印刷业等。
OCR 技术的主要优点如下:
1. 高效:与手动输入相比,OCR 技术可以大大提高文本输入的速度。
2. 准确:现代 OCR 技术具有较高的识别准确率,可以满足大部分应用场景的需求。
3. 自动化:使用 OCR 技术可以实现文本的自动化处理,减轻人力资源负担。
4. 通用性:OCR 软件支持多种文件格式和图像源,如 PDF、JPEG、TIFF 等。
然而,OCR 技术也存在一定的局限性:
1. 识别准确率:虽然近年来 OCR 技术的识别准确率有了很大提高,但仍然有可能出现误识别的情况。因此,在应用 OCR 技术时,用户需要对识别结果进行适当的检查和修正。
2. 字体兼容性:OCR 技术可能在不同字体和大小的情况下出现识别问题。
3. 背景噪音:图像中的背景噪音可能会影响 OCR 技术的识别效果。
4. 技术更新换代:随着技术的不断发展,现有的 OCR 软件可能无法兼容新的设备和操作系统。
总之,OCR 技术在许多方面具有优点,但用户也需要注意其局限性,并在实际应用中根据需求和实际情况进行选择。
如果搞科研,长期写论文,还是学习一下 LaTex。
LaTeX 是一种排版系统,将制作文档的过程分为两个阶段:编写内容和排版。编写内容阶段可以使用纯文本形式的 LaTeX 代码来描述文档的结构和格式,然后在排版阶段,LaTeX 处理器将代码转换为高质量的打印输出。
以下是一个简单的 LaTeX 代码示例,演示了如何创建一个包含标题、段落和列表的文档:
```latex
\documentclass{article}
\begin{document}
% 标题
\title{My Title}
\author{Your Name}
\date{}
\maketitle
% 段落
This is a paragraph. It is a simple example of a LaTeX document.
% 列表
\begin{itemize}
\item First item
\item Second item
\item Third item
\end{itemize}
\end{document}
```
将上述代码保存为一个 `.tex` 文件,然后使用 LaTeX 处理器(如 `pdflatex`)编译,即可得到一个包含标题、段落和列表的 PDF 文件。
LaTeX 代码具有以下特点:
1. 结构清晰:LaTeX 代码按照文档结构进行组织,易于阅读和理解。
2. 严格规范:LaTeX 代码遵循严格的语法规则,确保文档在不同环境下的一致性和稳定性。
3. 强大的数学公式支持:LaTeX 内置了丰富的数学公式库,方便用户制作专业水平的数学内容。
4. 丰富的宏包:LaTeX 提供了一系列宏包,用于实现特定的排版效果,如表格、图表、图片等。
5. 兼容性:LaTeX 代码可以在多种操作系统和设备上进行编译,生成高质量的打印输出。
需要注意的是,LaTeX 代码的编写和编译过程相对繁琐,需要用户掌握一定的技术知识和耐心。但是,一旦掌握了 LaTeX 的使用方法,它可以为用户提供强大的排版功能,轻松制作专业水平的文档。
LaTeX-OCR是使用 ViT 将方程图像转换为 LaTeX 代码。

LaTeX-OCR的介绍
LaTeX-OCR 是一款将 LaTeX 源代码转换为图像的软件工具,它利用光学字符识别(OCR)技术,识别 LaTeX 文本和图形,并将其转换为常见的图像格式,如 PNG、JPEG 等。这样,用户可以将 LaTeX 文档用于其他用途,如在网页上展示、打印或与他人分享。
LaTeX-OCR 主要由以下部分组成:
1. 输入:用户通过命令行或 GUI 界面输入 LaTeX 源代码。
2. 预处理:LaTeX-OCR 使用 `pdflatex` 命令将输入的 LaTeX 代码转换为 PDF 格式。
3. OCR 识别:LaTeX-OCR 使用 Tesseract 或其他 OCR 引擎识别 PDF 文件中的文本和图形。
4. 转换:识别后的文本和图形被转换为图像格式,如 PNG 或 JPEG。
5. 输出:最后,LaTeX-OCR 将生成的图像文件输出到指定目录。
LaTeX-OCR 的优势在于它能有效地将 LaTeX 文档转换为图像,从而让用户在不受排版和字体限制的情况下使用和分享文档内容。然而,由于 OCR 技术的局限性,识别准确率并非 100%,用户在得到输出图像后还需进行一定的复查。
LaTeX-OCR 支持多种操作系统,如 Windows、macOS 和 Linux。用户可以通过命令行或 GUI 界面进行操作。在激活 conda 环境后,输入命令“latexocr”即可启动 GUI 界面。此外,Detexify 等工具也可以帮助用户查看 LaTeX 特殊符号,以便在转换过程中更好地识别和处理。
LaTeX-OCR 的主要应用场景如下:
1. 将学术文献、技术文档、报告等 LaTeX 文件转换为图像,便于在网页、PPT 等场景中展示。
2. 将 LaTeX 制作的图形和文本转换为图像,以便在非 LaTeX 环境下使用。
3. 在编辑 LaTeX 文件时,由于某些原因(如字体问题、排版问题等),需要将文本或图形转换为图像,以满足特定需求。
4. 将 LaTeX 文件中的表格、图表等数据转换为图像,以便进行数据可视化、报告展示等场景。
5. 在教育、培训、学术会议等场合,将 LaTeX 文件中的关键内容转换为图像,以便在投影仪、显示屏等设备上展示。
6. 将 LaTeX 制作的图片、插图等转换为高分辨率的图像,以满足印刷、出版等需求。
需要注意的是,虽然 LaTeX-OCR 可以将 LaTeX 文件中的大部分内容转换为图像,但由于 OCR 技术的局限性,识别准确率并非 100%。在实际应用中,用户需要对转换结果进行适当的检查和调整。
该项目的目标是创建一个基于学习的系统,该系统获取数学公式的图像并返回相应的 LaTeX 代码。

使用模型
要运行模型,您需要 Python 3.7+
如果您没有安装 PyTorch。请按照此处的说明进行操作。
安装包pix2tex:
pip install "pix2tex[gui]"(更多安装流程请参考官网)
github地址:
https://github.com/lukas-blecher/LaTeX-OCR
原文链接:
Python学习项目:Python识别手写字符; EasyOCR 是一个用于从图像中提取文本的 python 模块
Python学习项目:LaTeX-OCR 识别数学公式,手写字符,转化为 LaTeX 代码; 写论文必备 数学公式轻松搞定!!

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 4
4 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)