

TEXT2SQL-顶峰:Vanna部署及介绍
Vanna 是一款采用 MIT 许可的开源 Python RAG (检索增强生成)框架,用于生成 SQL 语句和相关功能。如何使用 VannaVanna 的使用分为两个简单步骤 - 在你的数据上训练一个 RAG "模型",然后提出问题,该问题将返回可设置为自动在你的数据库上运行的 SQL 查询。1.。2.。如果你不知道什么是 RAG,不用担心 -- 你不需要知道这是如何在底层工作的。你只需要知道你
Vanna
Vanna 是一款采用 MIT 许可的开源 Python RAG (检索增强生成)框架,用于生成 SQL 语句和相关功能。
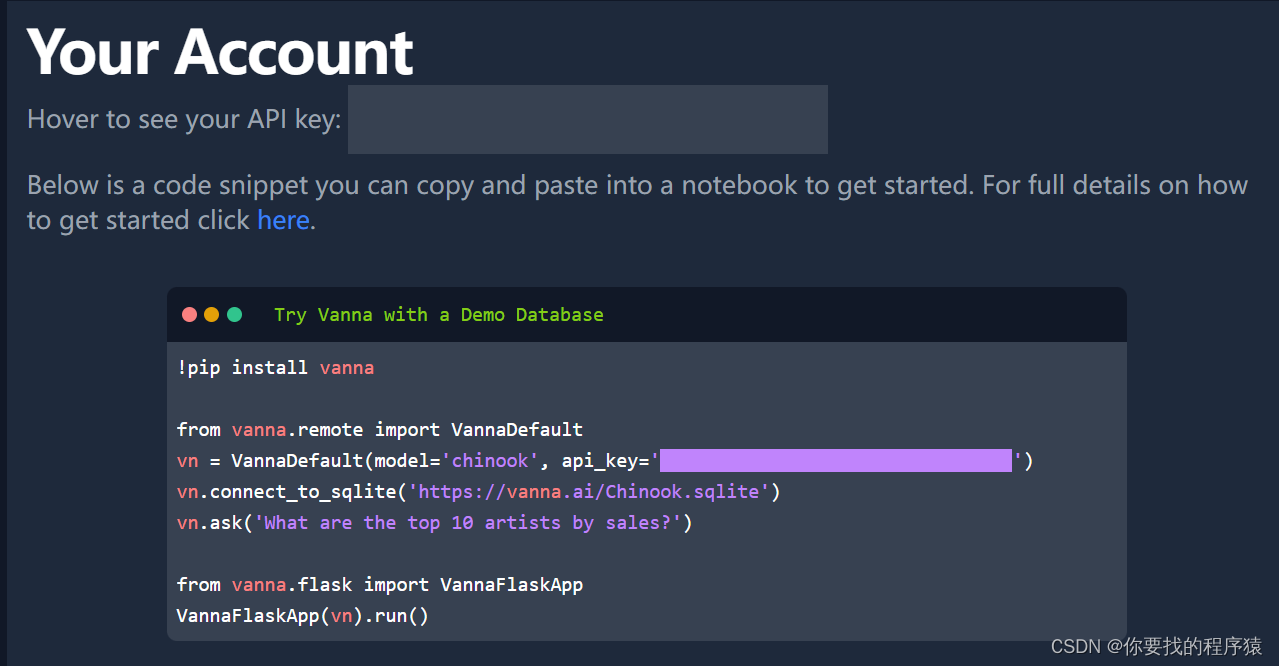 如何使用 Vanna
如何使用 Vanna
Vanna 的使用分为两个简单步骤 - 在你的数据上训练一个 RAG "模型",然后提出问题,该问题将返回可设置为自动在你的数据库上运行的 SQL 查询。
1.在你的数据上训练一个 RAG "模型"。
2.提问。
如果你不知道什么是 RAG,不用担心 -- 你不需要知道这是如何在底层工作的。你只需要知道你需要“训练”一个模型,它会存储一些元数据,然后你可以用它来“提问”。
关于RAG的相关知识可以参考:生成式人工智能-rag的全面介绍文献资源-CSDN文库
用户界面
这些是我们使用 Vanna 构建的一些用户界面。你可以直接使用这些界面,或者作为你自己定制界面的起点。
•Jupyter Notebook[2]
•vanna-ai/vanna-streamlit[3]
•vanna-ai/vanna-flask[4]
•vanna-ai/vanna-slack[5]
入门
具体内容请参见文档[6],了解有关你想要的数据库、LLM 等的具体信息。
如果你想在训练后了解它是如何工作的,你可以尝试这个Colab 笔记本[7]。
安装
pip install vanna有许多可选的包可以安装,具体请参见文档了解更多细节。
导入
如果你正在定制 LLM 或向量数据库,请参见文档。
import vanna as vn训练
根据您的具体用例,您可能需要或不需要运行这些 vn.train 命令。更多细节请参阅文档[8]。
这些说明旨在让您了解其工作原理。
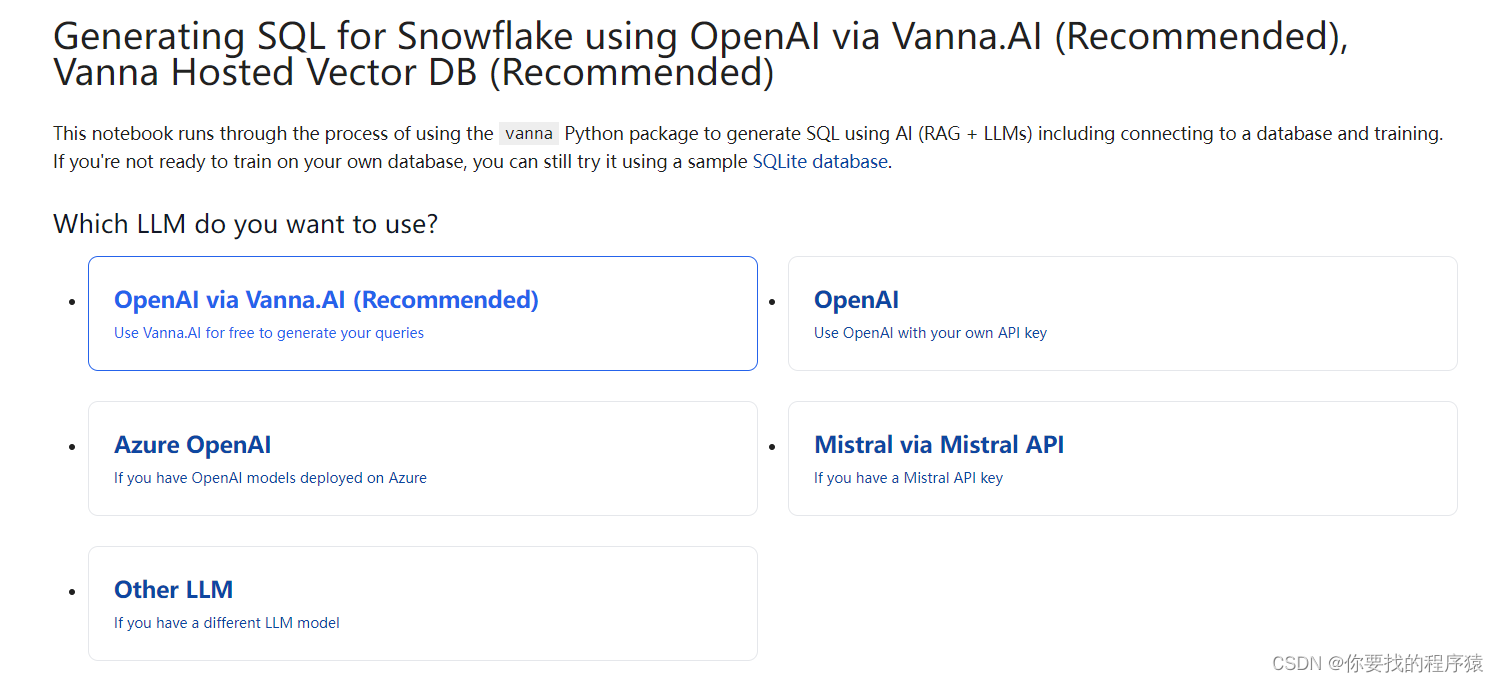
你可以选择VANNA提供的API、Openai等模型,甚至支持你本地自身的模型。以及多种向量库,向量库相关信息可以参考其他博主,我只在使用还没进行更深入开发。

使用本地的模型,最近在尝试写。当有进展的时候会继续更新。
使用 DDL 语句训练
DDL 语句包含有关你的数据库中表名、列、数据类型和关系的信息。
vn.train(ddl="""CREATE TABLE IF NOT EXISTS my-table (id INT PRIMARY KEY,name VARCHAR(100),age INT)""")
使用文档训练
有时你可能想要添加有关你的业务术语或定义的文档。
vn.train(documentation="Our business defines XYZ as ...")使用 SQL 训练
你还可以向你的训练数据中添加 SQL 查询。这在你已经有一些查询并希望直接从编辑器中复制粘贴以生成新的 SQL 时非常有用。
vn.train(sql="SELECT name, age FROM my-table WHERE name = 'John Doe'")提问
vn.ask("What are the top 10 customers by sales?")如果你连接到了数据库,你将得到以下表格:
| CUSTOMER_NAME | TOTAL_SALES | |
| 0 | Customer#000143500 | 6757566.0218 |
| 1 | Customer#000095257 | 6294115.3340 |
| 2 | Customer#000087115 | 6184649.5176 |
| 3 | Customer#000131113 | 6080943.8305 |
| 4 | Customer#000134380 | 6075141.9635 |
| 5 | Customer#000103834 | 6059770.3232 |
| 6 | Customer#000069682 | 6057779.0348 |
| 7 | Customer#000102022 | 6039653.6335 |
| 8 | Customer#000098587 | 6027021.5855 |
| 9 | Customer#000064660 | 5905659.6159 |
你还会得到一个自动生成的 Plotly 图表:[9]
RAG 与精调 (Fine-Tuning) 对比
RAG:
•可以跨 LLM 使用•容易移除过时的训练数据•运行成本比精调低得多•更具未来性 -- 如果出现更好的 LLM,你可以直接替换
精调 (Fine-Tuning):
•如果你需要在提示中最小化令牌数量,这是个好选择•开始使用较慢•训练和运行成本较高(通常情况下)
为什么选择 Vanna?
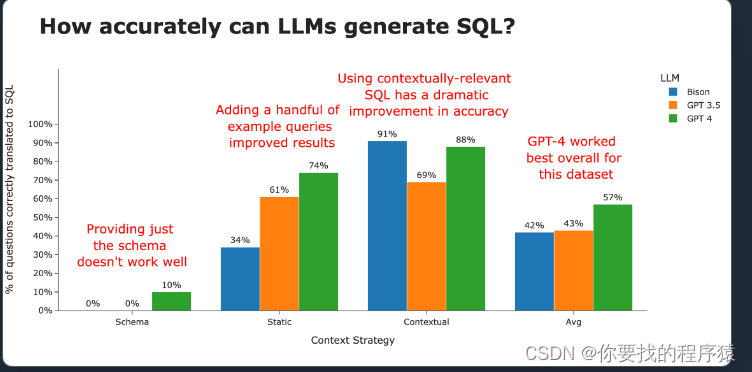
1.在复杂数据集上的高准确性。•Vanna 的能力与你提供的训练数据相关•更多的训练数据意味着在大型和复杂的数据集上有更好的准确性2.安全且私密。•你的数据库内容永远不会发送给 LLM 或向量数据库•SQL 执行发生在你的本地环境中3.自我学习。•如果通过 Jupyter 使用,你可以选择在成功执行的查询上“自动训练”•如果通过其他界面使用,你可以让界面提示用户对结果提供反馈•正确的问题到 SQL 对会被存储以供将来参考,使未来的结果更加准确4.支持任何 SQL 数据库。•该包允许你连接到任何你可以通过 Python 连接的 SQL 数据库5.选择你的前端。•大多数人从 Jupyter 笔记本开始。•通过 Slackbot、Web 应用、Streamlit 应用或自定义前端向你的最终用户展示。
扩展 Vanna
Vanna 设计用于连接任何数据库、LLM 和向量数据库。有一个 VannaBase 抽象基类定义了一些基本功能。该包提供了与 OpenAI 和 ChromaDB 一起使用的实现。你可以轻松地扩展 Vanna 以使用你自己的 LLM 或向量数据库。更多细节请参见文档[10]。
引用
更多信息请参考:https://github.com/vanna-ai/vanna
References
[1] 基类: https://github.com/vanna-ai/vanna/blob/main/src/vanna/base/base.py[2] Jupyter Notebook: https://github.com/vanna-ai/vanna/blob/main/notebooks/getting-started.ipynb[3] vanna-ai/vanna-streamlit: https://github.com/vanna-ai/vanna-streamlit[4] vanna-ai/vanna-flask: https://github.com/vanna-ai/vanna-flask[5] vanna-ai/vanna-slack: https://github.com/vanna-ai/vanna-slack[6] 文档: https://vanna.ai/docs/[7] Colab 笔记本: https://colab.research.google.com/github/vanna-ai/vanna/blob/main/notebooks/getting-started.ipynb[8] 文档: https://vanna.ai/docs/[9] : https://github.com/vanna-ai/vanna/blob/main/img/top-10-customers.png[10] 文档: https://vanna.ai/docs/[11] 完整文档: https://vanna.ai/docs/[12] 网站: https://vanna.ai/[13] 支持用的 Discord 群组: https://discord.gg/qUZYKHremx

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)